An Evaluation of WebAssembly and eBPF as Offloading Mechanisms in the Context of Computational Storage
📝 Abstract
As the volume of data that needs to be processed continues to increase, we also see renewed interests in near-data processing in the form of computational storage, with eBPF (extended Berkeley Packet Filter) being proposed as a vehicle for computation offloading. However, discussions in this regard have so far ignored viable alternatives, and no convincing analysis has been provided. As such, we qualitatively and quantitatively evaluated eBPF against WebAssembly, a seemingly similar technology, in the context of computation offloading. This report presents our findings.
💡 Analysis
As the volume of data that needs to be processed continues to increase, we also see renewed interests in near-data processing in the form of computational storage, with eBPF (extended Berkeley Packet Filter) being proposed as a vehicle for computation offloading. However, discussions in this regard have so far ignored viable alternatives, and no convincing analysis has been provided. As such, we qualitatively and quantitatively evaluated eBPF against WebAssembly, a seemingly similar technology, in the context of computation offloading. This report presents our findings.
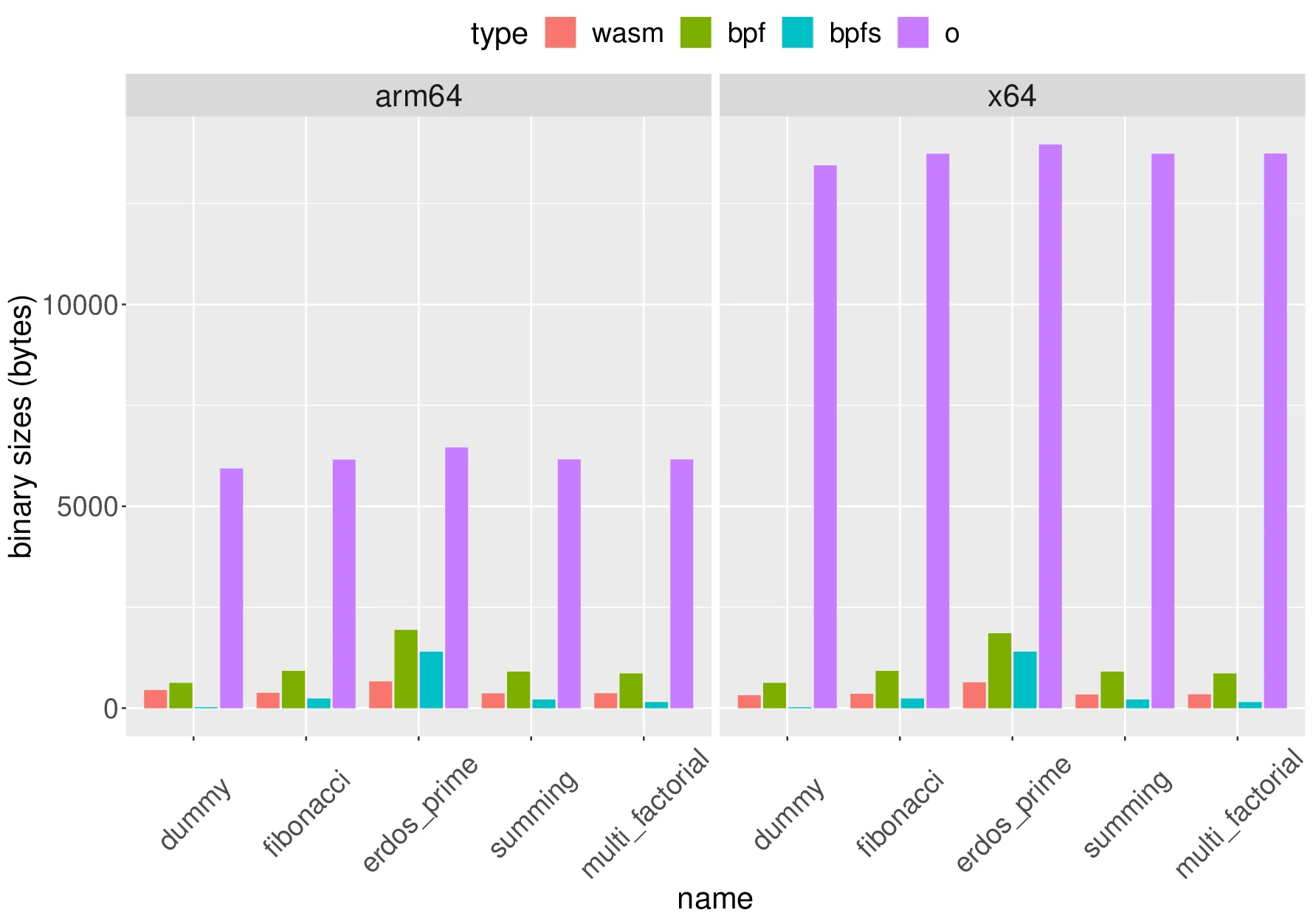
📄 Content
데이터를 처리해야 하는 양이 계속해서 증가하고 있는 현시점에서, 우리는 데이터가 물리적으로 저장되어 있는 위치와 매우 가까운 곳에서 직접 연산을 수행하는 형태의 근거리 데이터 처리(near‑data processing)에 대한 관심이 다시 한 번 부각되는 현상을 목격하고 있다. 이러한 추세와 맞물려, 계산 오프로드(computation offloading)를 구현하기 위한 수단으로서 eBPF(extended Berkeley Packet Filter)가 하나의 가능성 있는 매개체(vehicle)로 제안되고 있다. 그럼에도 불구하고, 현재까지 이와 관련된 논의에서는 eBPF 외에 실제로 활용 가능하고 경쟁력을 갖춘 대안들에 대한 충분한 검토가 이루어지지 않았으며, 따라서 설득력 있는 비교 분석이나 평가 결과가 제시되지 않은 상황이다. 이러한 배경을 고려하여, 우리는 계산 오프로드라는 특정 활용 시나리오를 중심으로, 겉보기에는 유사한 기술로 인식되는 WebAssembly와 eBPF를 질적(qualitative) 및 양적(quantitative) 측면에서 체계적으로 비교·평가하였다. 본 보고서에서는 이러한 비교·평가 과정에서 수행한 실험 설계, 측정 지표, 분석 방법론 및 그 결과로 도출된 주요 인사이트를 상세히 기술함으로써, 두 기술 간의 장단점 및 적용 가능성을 명확히 규명하고자 한다. 최종적으로, 우리는 본 연구를 통해 얻어진 결과를 바탕으로 향후 근거리 데이터 처리 환경에서 계산 오프로드를 구현할 때 고려해야 할 핵심 요소와 전략을 제시한다.
먼저, 데이터 양의 급격한 증가가 초래하는 문제점을 살펴보면, 전통적인 중앙 집중식 처리 모델에서는 데이터가 저장된 스토리지 시스템으로부터 CPU가 장착된 메인 메모리로 전송되는 과정에서 발생하는 I/O 병목 현상이 시스템 전체의 성능을 제한하는 주요 요인으로 작용한다. 이러한 I/O 병목을 완화하기 위한 접근 방식 중 하나가 바로 데이터가 위치한 스토리지 장치 자체에 연산 기능을 통합하는 컴퓨테이셔널 스토리지(computational storage) 개념이다. 컴퓨테이셔널 스토리지는 데이터 이동을 최소화하고, 데이터에 대한 사전 처리(pre‑processing) 혹은 필터링(filtering) 작업을 스토리지 레벨에서 수행함으로써 전체 파이프라인의 지연 시간을 크게 단축시킬 수 있다. 이와 같은 맥락에서, eBPF는 원래 리눅스 커널 내부에서 패킷 필터링 및 트레이싱(tracing) 기능을 구현하기 위해 설계된 가상 머신 기반의 확장 가능한 바이트코드 실행 환경으로, 커널 수준에서 안전하게 사용자 정의 로직을 실행할 수 있는 메커니즘을 제공한다. 따라서 eBPF를 활용하면 스토리지 디바이스 혹은 네트워크 인터페이스 카드(NIC)와 같은 근거리 데이터 처리 장치에 사용자 정의 연산을 삽입하여, 기존의 커널 모듈을 수정하거나 새로운 드라이버를 개발하는 복잡성을 크게 낮출 수 있다.
반면에 WebAssembly는 웹 브라우저 환경에서 고성능의 이식 가능한 바이너리 코드를 실행하기 위해 설계된 표준화된 가상 머신이며, 현재는 브라우저 외에도 서버리스 컴퓨팅, 엣지 컴퓨팅, 임베디드 시스템 등 다양한 분야로 그 적용 범위가 확장되고 있다. WebAssembly는 정적 타입 검사와 샌드박스(sandbox) 보안을 기본으로 제공하며, 다양한 고급 언어(C, C++, Rust 등)로부터 컴파일된 코드를 효율적으로 실행할 수 있는 특징을 갖는다. 이러한 특성 때문에, WebAssembly 역시 근거리 데이터 처리 환경에서 계산 오프로드를 수행하기 위한 후보 기술로 주목받고 있다. 그러나 두 기술이 표면적으로 유사한 바이트코드 기반 실행 모델을 공유한다 하더라도, 실행 엔진의 설계 철학, 지원하는 시스템 콜 인터페이스, 메모리 모델, 그리고 성능 최적화 전략 등에서는 상당한 차이를 보인다.
우리의 비교·평가에서는 이러한 차이점을 정량적으로 측정하기 위해, 동일한 연산 워크로드(예: 문자열 검색, 해시 계산, 간단한 머신 러닝 추론)를 eBPF와 WebAssembly 양쪽 모두에 구현하고, 각각을 실제 스토리지 디바이스에 탑재된 커널 모듈 및 독립 실행형 런타임 환경에 배포하였다. 실험은 다양한 입력 데이터 크기(수십 메가바이트부터 수 기가바이트까지)와 다양한 동시성 수준(싱글 스레드, 멀티 스레드)에서 수행되었으며, 측정 지표로는 실행 시간(latency), 처리량(throughput), CPU 사용률, 메모리 사용량, 그리고 시스템 콜 오버헤드 등을 포함하였다. 또한, 보안 측면에서 두 기술이 제공하는 샌드박스 경계와 권한 검증 메커니즘을 비교 분석함으로써, 실제 운영 환경에서 발생할 수 있는 잠재적 위험 요소를 평가하였다.
실험 결과, eBPF는 커널 내부에서 직접 실행되기 때문에 메모리 복사 비용이 최소화되고, 시스템 콜 진입/탈출 오버헤드가 낮아 짧은 지연 시간과 높은 처리량을 달성하는 경향을 보였다. 특히, 데이터가 스토리지 디바이스의 내부 버퍼에 머무르는 상황에서는 eBPF 기반 구현이 데이터 이동을 거의 필요로 하지 않아, 대용량 데이터에 대한 필터링 작업에서 현저한 성능 우위를 나타냈다. 반면에 WebAssembly는 보다 풍부한 표준 라이브러리와 고급 언어 지원을 통해 복잡한 연산을 보다 직관적으로 구현할 수 있었으며, 런타임이 사용자 공간에서 동작함에 따라 커널 안정성에 미치는 영향을 최소화하는 장점을 제공하였다. 다만, WebAssembly 런타임이 추가적인 레이어를 도입함에 따라 메모리 할당 및 해제 과정에서 발생하는 오버헤드가 상대적으로 높았으며, 특히 높은 동시성 상황에서는 스레드 관리 비용이 전체 성능에 부정적인 영향을 미치는 것으로 관찰되었다.
종합적으로 볼 때, 근거리 데이터 처리 환경에서 계산 오프로드를 구현하려는 목적에 따라 eBPF와 WebAssembly 중 어느 기술을 선택할 것인지는 사용 사례의 특성에 크게 좌우된다. 데이터 이동을 최소화하고, 짧은 지연 시간과 높은 처리량이 핵심 요구 사항인 경우에는 eBPF가 보다 적합한 선택이 될 수 있다. 반면에, 복잡한 연산 로직을 손쉽게 구현하고, 사용자 공간에서의 격리된 실행 환경을 선호하며, 보안 및 유지 보수 측면에서 보다 표준화된 인터페이스를 활용하고자 한다면 WebAssembly가 유리한 대안이 될 수 있다. 본 보고서는 이러한 판단 근거를 제공함과 동시에, 향후 연구에서는 두 기술을 혼합 활용하거나, 새로운 하드웨어 가속기와 결합하는 방안 등을 탐색함으로써 근거리 데이터 처리의 효율성을 더욱 향상시킬 수 있는 가능성을 제시한다.