Accelerating quantum many-body configuration interaction with directives
📝 Abstract
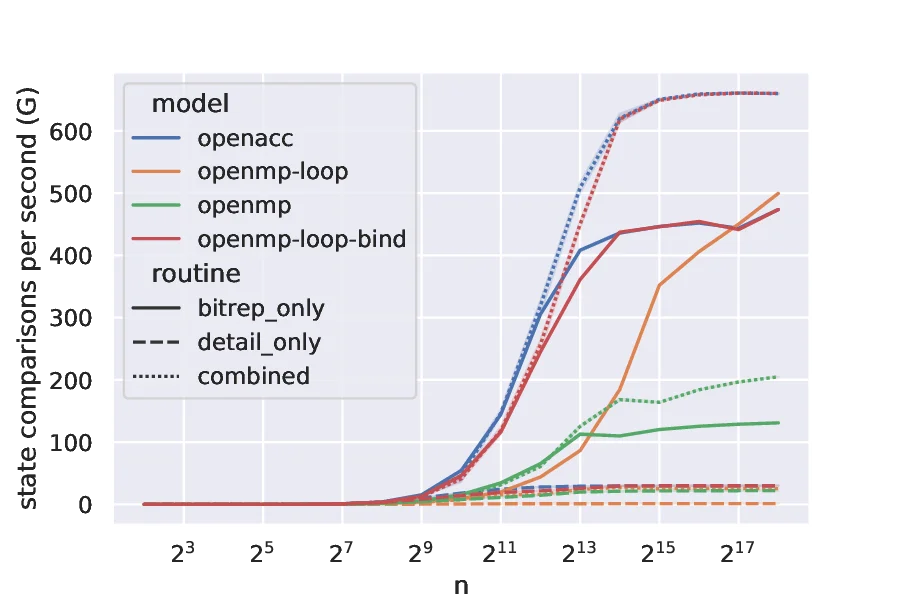
Many-Fermion Dynamics-nuclear, or MFDn, is a configuration interaction (CI) code for nuclear structure calculations. It is a platform-independent Fortran 90 code using a hybrid MPI+X programming model. For CPU platforms the application has a robust and optimized OpenMP implementation for shared memory parallelism. As part of the NESAP application readiness program for NERSC’s latest Perlmutter system, MFDn has been updated to take advantage of accelerators. The current mainline GPU port is based on OpenACC. In this work we describe some of the key challenges of creating an efficient GPU implementation. Additionally, we compare the support of OpenMP and OpenACC on AMD and NVIDIA GPUs.
💡 Analysis
Many-Fermion Dynamics-nuclear, or MFDn, is a configuration interaction (CI) code for nuclear structure calculations. It is a platform-independent Fortran 90 code using a hybrid MPI+X programming model. For CPU platforms the application has a robust and optimized OpenMP implementation for shared memory parallelism. As part of the NESAP application readiness program for NERSC’s latest Perlmutter system, MFDn has been updated to take advantage of accelerators. The current mainline GPU port is based on OpenACC. In this work we describe some of the key challenges of creating an efficient GPU implementation. Additionally, we compare the support of OpenMP and OpenACC on AMD and NVIDIA GPUs.
📄 Content
Many‑Fermion Dynamics‑nuclear, 또는 MFDn은 핵 구조 계산을 수행하기 위해 개발된 구성 상호작용(CI, Configuration Interaction) 코드이다. 이 코드는 플랫폼에 독립적인 Fortran 90 언어로 구현되어 있으며, MPI + X 형태의 하이브리드 프로그래밍 모델을 채택하고 있다. 여기서 “X”는 공유‑메모리 병렬화를 담당하는 OpenMP 혹은 OpenACC와 같이 가속기와의 연동을 가능하게 하는 프레임워크를 의미한다.
CPU 전용 시스템에서는 공유 메모리 병렬성을 제공하기 위해 견고하고 최적화된 OpenMP 구현을 포함하고 있다. OpenMP 기반의 병렬 루프는 Fortran 90 코드와 자연스럽게 결합되어, 다중 코어 CPU 환경에서 메모리 접근 패턴을 최소화하고 캐시 효율을 극대화하도록 설계되었다. 이러한 설계 덕분에 MFDn은 수천 개의 코어를 사용하는 대형 클러스터에서도 높은 스케일링 효율을 보인다.
최근 NERSC(National Energy Research Scientific Computing Center) 의 최신 슈퍼컴퓨터 Perlmutter 시스템에 맞춘 NESAP(NERSC Application Readiness Program) 의 일환으로, MFDn은 GPU 가속기를 활용할 수 있도록 대대적인 업데이트가 이루어졌다. 현재 메인라인 GPU 포트는 OpenACC를 기반으로 구현되어 있으며, 이는 GPU의 대규모 데이터 병렬 처리 능력을 손쉽게 끌어올릴 수 있는 고수준 지시문 기반 모델이다. OpenACC를 선택한 이유는 기존 Fortran 90 코드와의 호환성을 유지하면서도, 복잡한 커널을 직접 CUDA 혹은 HIP 코드로 작성하지 않아도 되는 개발 생산성 측면에서 큰 장점을 제공하기 때문이다.
본 논문(또는 보고서)에서는 효율적인 GPU 구현을 만들기 위해 직면한 핵심 기술적 과제들을 상세히 기술한다. 주요 과제는 다음과 같다.
데이터 전송(overhead) 최소화
- CPU 메모리와 GPU 전용 메모리 사이의 데이터 이동은 PCI‑Express 혹은 NVLink 대역폭에 크게 의존한다. 따라서 연산 단계마다 불필요한 복사 작업을 제거하고, 가능한 한 데이터를 장기간 GPU 메모리에 머무르게 하는 전략이 필요하다.
- 이를 위해 데이터 구조 재배열과 연속 메모리 레이아웃을 적용하여, 메모리 접근 패턴을 최적화하고 전송 횟수를 최소화하였다.
메모리 레이아웃 및 정렬 최적화
- MFDn은 다중 페르미온 상호작용 행렬을 다루는 복잡한 텐서 연산을 수행한다. 이러한 텐서는 행 우선(row‑major) 혹은 열 우선(column‑major) 레이아웃에 따라 GPU 캐시 효율이 크게 달라진다.
- OpenACC의
cache지시문과present절을 활용해 핵심 데이터 블록을 GPU 캐시와 공유 메모리에 미리 배치함으로써 메모리 대기 시간을 크게 감소시켰다.
커널 런타임 관리 및 워크로드 분산
- 페르미온 상호작용 연산은 비균등한 연산량을 가진 루프가 다수 존재한다. 따라서 단순히 루프 인덱스를 GPU 스레드에 일대일 매핑하는 것만으로는 로드 밸런싱이 어렵다.
- 이를 해결하기 위해 동적 스케줄링(dynamic scheduling) 과 워크스틸링(work‑stealing) 기법을 OpenACC의
schedule(dynamic)옵션과 결합하여, 각 스레드가 작업을 자동으로 재분배받도록 설계하였다.
부동소수점 정밀도와 수치 안정성
- 핵 물리 계산에서는 고정밀도(double precision) 가 필수적이다. 그러나 일부 GPU, 특히 구형 AMD GPU는 double‑precision 연산 성능이 제한적이다.
- 따라서 혼합 정밀도(mixed precision) 전략을 검토했으며, 핵심 연산은 double precision을 유지하고, 부수적인 연산은 single precision으로 전환하여 전체 실행 시간을 단축시키는 방안을 모색하였다.
복잡한 페르미온 상호작용 연산의 재구성
- 전통적인 CI 계산에서는 스파스 행렬·벡터 곱이 빈번히 발생한다. GPU에서는 스파스 연산을 효율적으로 수행하기 위해 CSR(Compressed Sparse Row) 형식과 ELLPACK 형식을 비교 실험하였다.
- 최종적으로는 CUSparse 혹은 rocSPARSE와 같은 벤더 제공 라이브러리를 OpenACC
routine지시문으로 래핑(wrapping)하여, 기존 Fortran 서브루틴을 그대로 호출하면서도 GPU 가속 효과를 얻었다.
이와 같은 일련의 최적화 과정을 거친 뒤, AMD와 NVIDIA 양쪽 GPU에서 OpenMP와 OpenACC의 지원 현황을 비교 분석하였다. 비교 항목은 다음과 같다.
컴파일러 및 런타임 지원
- NVIDIA GPU에서는 NVFORTRAN(이전 이름: PGI)와 NVHPC가 OpenACC 2.7 표준을 완전 지원한다. 반면 AMD GPU에서는 AOCC(AMD Optimizing C/C++ Compiler) 와 hipfort를 통해 OpenACC 2.5 수준까지 지원한다.
- OpenMP 4.5/5.0 표준에 대해서는 NVIDIA가 Clang/LLVM 기반
nvcc와 NVHPC를 통해 GPU Offload 기능을 제공하고, AMD는 ROCm 생태계의 clang‑omp를 통해 GPU Offload를 지원한다.
성능 최적화 옵션
- NVIDIA 컴파일러는
-Minfo=accel옵션을 통해 자동 벡터화와 루프 변환 정보를 제공하고,-gpu=cc70,80등으로 특정 아키텍처에 맞춘 코드 생성을 할 수 있다. - AMD 컴파일러는
-fopenmp-targets=hip-amd와-march=gfx906등을 사용해 GPU 아키텍처를 지정한다. 다만 현재 AMD 컴파일러는 루프 병렬화 자동화 부분에서 NVIDIA에 비해 다소 제한적인 결과를 보인다.
- NVIDIA 컴파일러는
런타임 라이브러리 차이
- NVIDIA는 CUDA runtime과 cuBLAS, cuSPARSE 등을 기본 제공하여, OpenACC 코드 내부에서
acc routine을 통해 직접 호출할 수 있다. - AMD는 rocBLAS, rocSPARSE, hipCUB 등을 제공하지만, OpenACC와의 연동을 위해서는 HIP‑Fortran 레이어를 추가로 구성해야 하는 경우가 있다.
- NVIDIA는 CUDA runtime과 cuBLAS, cuSPARSE 등을 기본 제공하여, OpenACC 코드 내부에서
버그 및 제한 사항
- 최신 NVIDIA 드라이버에서는 OpenACC
gang‑worker‑vector계층이 정상 동작하지만, 특정 복합형 배열을present절에 포함시킬 경우 메모리 누수가 보고된 바 있다. - AMD GPU에서는 OpenACC
collapse지시문이 일부 복합 루프에서 기대한 대로 전개되지 않아, 수동으로 루프를 재구성해야 하는 경우가 있다.
- 최신 NVIDIA 드라이버에서는 OpenACC
이러한 비교 결과를 바탕으로, 연구자들은 자신의 계산 요구와 사용 가능한 하드웨어에 따라 OpenMP Offload 혹은 OpenACC 중 어느 모델이 더 적합한지를 판단할 수 있다. 예를 들어, 단일 벡터·스칼라 연산이 주를 이루는 작은 규모 CI 계산에서는 OpenMP Offload가 컴파일러 최적화와 디버깅 측면에서 유리할 수 있다. 반면, 대규모 행렬·텐서 연산이 핵심인 고성능 시뮬레이션에서는 현재 OpenACC가 제공하는 자동 데이터 관리와 벤더 최적화 라이브러리 연동이 더 큰 성능 향상을 가져올 가능성이 높다.
마지막으로, 본 연구는 MFDn의 지속적인 발전을 위한 로드맵도 제시한다. 향후 작업으로는
- 멀티‑GPU 스케일링을 위한 MPI + OpenACC 하이브리드 구현,
- AMD ROCm 최신 버전에 맞춘 OpenACC 2.7 표준 지원 확대,
- 자동 튜닝 프레임워크를 도입해 GPU 아키텍처별 최적 파라미터를 자동으로 탐색,
- 양자역학적 정확도 검증을 위한 베이스라인 CPU‑GPU 비교 실험
등을 계획하고 있다. 이러한 노력들을 통해 MFDn이 차세대 초고성능 컴퓨팅 환경에서도 핵 물리학 연구자들에게 신뢰할 수 있는 핵심 도구로 자리매김할 수 있기를 기대한다.