HiMA: A Fast and Scalable History-based Memory Access Engine for Differentiable Neural Computer
Memory-augmented neural networks (MANNs) provide better inference performance in many tasks with the help of an external memory. The recently developed differentiable neural computer (DNC) is a MANN that has been shown to outperform in representing complicated data structures and learning long-term dependencies. DNC’s higher performance is derived from new history-based attention mechanisms in addition to the previously used content-based attention mechanisms. History-based mechanisms require a variety of new compute primitives and state memories, which are not supported by existing neural network (NN) or MANN accelerators. We present HiMA, a tiled, history-based memory access engine with distributed memories in tiles. HiMA incorporates a multi-mode network-on-chip (NoC) to reduce the communication latency and improve scalability. An optimal submatrix-wise memory partition strategy is applied to reduce the amount of NoC traffic; and a two-stage usage sort method leverages distributed tiles to improve computation speed. To make HiMA fundamentally scalable, we create a distributed version of DNC called DNC-D to allow almost all memory operations to be applied to local memories with trainable weighted summation to produce the global memory output. Two approximation techniques, usage skimming and softmax approximation, are proposed to further enhance hardware efficiency. HiMA prototypes are created in RTL and synthesized in a 40nm technology. By simulations, HiMA running DNC and DNC-D demonstrates 6.47 × and 39.1 × higher speed, 22.8 × and 164.3 × better area efficiency, and 6.1 × and 61.2 × better energy efficiency over the state-of-the-art MANN accelerator. Compared to an Nvidia 3080Ti GPU, HiMA demonstrates speedup by up to 437 × and 2,646 × when running DNC and DNC-D, respectively.
💡 Research Summary
The paper introduces HiMA, a novel hardware engine designed to accelerate the Differentiable Neural Computer (DNC), a memory‑augmented neural network that combines content‑based and history‑based attention mechanisms. While DNC’s history‑based mechanisms dramatically improve the ability to model long‑term dependencies, they also introduce a set of new primitives—sorting, matrix transposition, usage‑vector updates, linkage matrix expansion, and several state memories—that are not supported by existing neural‑network or MANN accelerators.
HiMA addresses these challenges through a tiled, distributed architecture. Memory is partitioned into many tiles, each containing a local memory bank, a set of state variables (usage, precedence, linkage, etc.), and a compute unit. By keeping most operations local, HiMA eliminates the serialization bottlenecks of centralized designs and enables high parallelism.
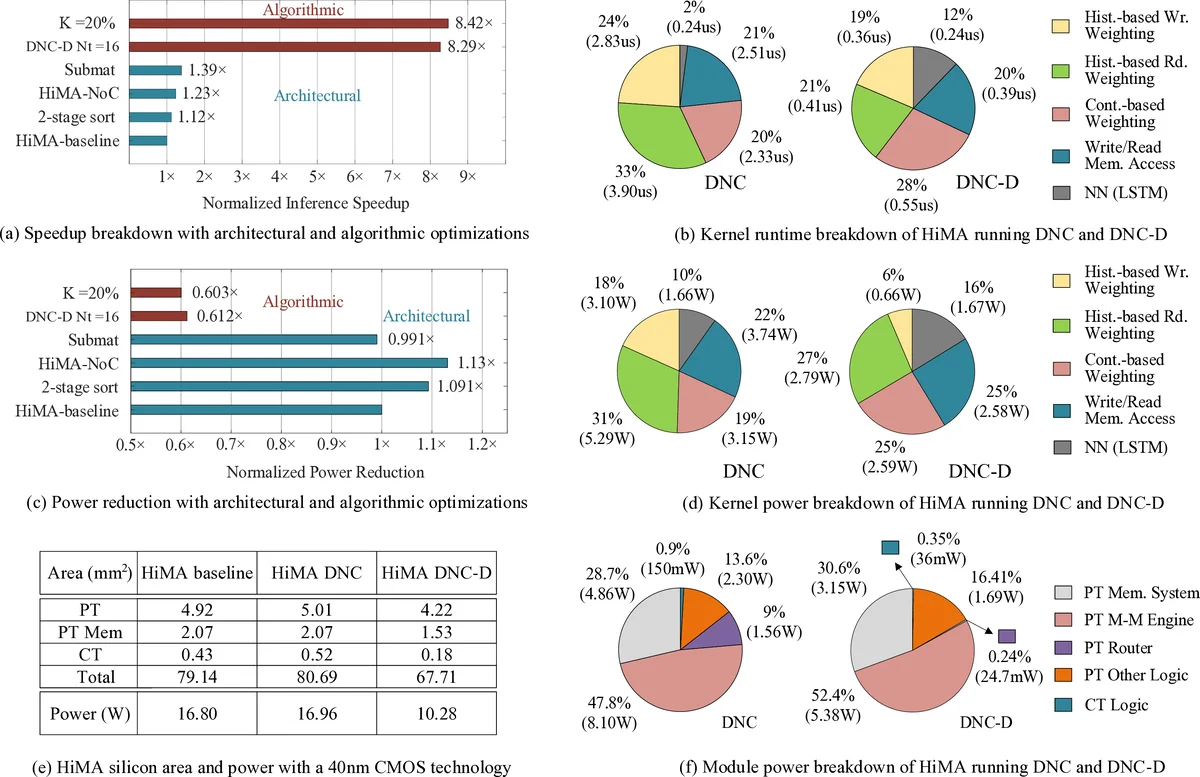
A key contribution is the multi‑mode Network‑on‑Chip (NoC). The authors analyze DNC’s traffic patterns and observe two distinct phases: (1) fine‑grained packet exchanges for content‑based weighting, and (2) bulk transfers of large matrices (e.g., expanded linkage) required by history‑based steps. The NoC can dynamically switch between a low‑latency packet mode and a high‑bandwidth matrix‑transfer mode, reducing latency and improving scalability as the number of tiles grows.
Memory partitioning is performed at the sub‑matrix level rather than simple row or column splits. This “submatrix‑wise” strategy aligns with the mixed access patterns of DNC, minimizing inter‑tile traffic for both content‑based and history‑based operations.
To further reduce communication and computation, the authors propose a distributed version of DNC called DNC‑D. In DNC‑D, each tile independently computes its portion of the write/read weightings, usage updates, and linkage updates. The global read/write vectors are then obtained by a trainable weighted sum across tiles. This design pushes almost all memory operations to local memories, dramatically cutting global synchronization overhead.
Algorithmic optimizations complement the hardware design: (i) a two‑stage usage sort (local partial sort followed by a global merge) reduces the O(N log N) sorting cost to O(N log (N/T)), where T is the number of tiles; (ii) “usage skimming” discards low‑usage slots early, avoiding unnecessary arithmetic; (iii) a softmax approximation replaces expensive exponentials with a log‑sigmoid based estimator, lowering both latency and hardware area.
The authors implement HiMA in RTL and synthesize it in a 40 nm CMOS process. Evaluation against the state‑of‑the‑art MANN accelerator MANNA shows up to 6.47× (DNC) and 39.1× (DNC‑D) speedup, 22.8× and 164.3× improvements in area efficiency, and 6.1× and 61.2× gains in energy efficiency, respectively. Compared with an Nvidia RTX 3080 Ti GPU, HiMA achieves up to 437× speedup for the original DNC and an astonishing 2,646× speedup for DNC‑D.
These results demonstrate that the primary bottlenecks of DNC—large‑scale sorting, usage vector management, and linkage matrix expansion—can be effectively mitigated through a combination of distributed memory, adaptive NoC, submatrix partitioning, and algorithmic approximations. While the prototype is built in 40 nm, the authors argue that moving to advanced nodes (7 nm/5 nm) would further amplify absolute performance and energy savings.
Future work suggested includes automated exploration of tile counts and NoC topologies for different memory sizes, extending the architecture to other memory‑augmented models (e.g., Transformer‑based memories), and evaluating HiMA on real‑world workloads such as large‑scale graph reasoning, navigation, and reinforcement‑learning tasks. Overall, HiMA represents a significant step toward scalable, high‑performance hardware for history‑aware memory‑augmented neural networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment