Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
💡 Research Summary
This paper presents a comprehensive performance and energy analysis of Google’s commercial Edge Tensor Processing Unit (TPU) when running a diverse set of 24 state‑of‑the‑art edge neural network (NN) models. The models span four major NN families—convolutional neural networks (CNNs), long short‑term memory networks (LSTMs), transducers, and recurrent convolutional neural networks (RCNNs)—and are used in real Google mobile applications such as image classification, object detection, speech recognition, and image captioning. By measuring each model at the granularity of individual layers, the authors uncover three fundamental shortcomings of the Edge TPU’s monolithic design.
First, the TPU operates at only about 24 % of its peak computational throughput on average, with some LSTM and transducer layers utilizing less than 1 % of the available processing elements (PEs). This under‑utilization stems from a fixed 64 × 64 PE array and a static dataflow (output‑stationary) that cannot adapt to the wide variation in layer compute intensity and data‑reuse patterns.
Second, the TPU achieves merely 37 % of its theoretical energy efficiency (TFLOP/J). Large on‑chip SRAM buffers, which occupy a substantial portion of static and dynamic power (≈48 % static, 36 % dynamic during CNN inference), are insufficient to hold all model parameters. Consequently, frequent off‑chip memory accesses dominate energy consumption and throttle memory bandwidth, further starving the PEs.
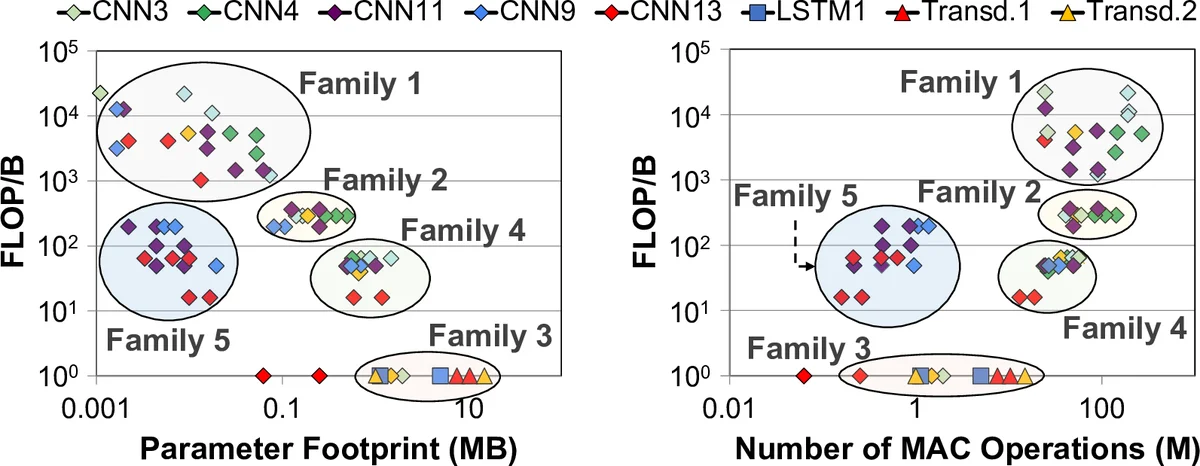
Third, the memory subsystem itself becomes a dominant bottleneck. Layer‑wise characteristics such as FLOP‑per‑byte ratio, parameter footprint, and intra‑layer dependencies vary by up to two orders of magnitude both across models and within a single model. A one‑size‑fits‑all buffer and bandwidth provision therefore leads to severe inefficiencies: compute‑centric layers waste buffer space, while memory‑centric layers suffer from bandwidth saturation and low PE utilization.
To address these issues, the authors propose Mensa, a novel hardware/software composable framework for edge ML acceleration. Mensa’s key insight is that, despite the apparent heterogeneity, the 24 models’ layers naturally cluster into a small number of groups based on a few salient characteristics (memory boundedness and reuse opportunities). Mensa therefore employs a handful of specialized, small accelerators—named Pascal, Pavlov, and Jacquard—each optimized for a specific cluster.
- Pascal targets compute‑centric layers (standard convolutions, depthwise separable convolutions). It retains a high‑utilization PE array but adopts an optimized dataflow that reduces on‑chip buffer size by 16× and cuts inter‑PE network traffic.
- Pavlov is designed for LSTM‑like, data‑centric layers. It introduces a temporal dataflow that enables output activation reduction across time steps and maximizes parameter reuse, dramatically lowering off‑chip memory traffic.
- Jacquard handles other data‑centric layers (e.g., pointwise, fully‑connected). It shrinks the parameter buffer by 32× and uses a dataflow that exposes parameter reuse opportunities.
Both Pavlov and Jacquard are placed in the logic layer of a 3‑D‑stacked memory, allowing them to use much smaller PE arrays than Pascal while still achieving high performance and energy efficiency.
A runtime scheduler orchestrates layer execution across the heterogeneous accelerators, taking into account (1) the accelerator that best matches the layer’s characteristics and (2) the communication cost between consecutive layers. Because the layer clustering is small, the scheduler’s overhead remains modest.
Experimental results show that Mensa‑G (the concrete implementation of Mensa with the three accelerators) reduces total inference energy by 66 % relative to the Edge TPU, improves energy efficiency (TFLOP/J) by 3.0×, and boosts computational throughput (TFLOP/s) by 3.1× on average across all 24 models. Compared with Eyeriss v2, a leading reconfigurable accelerator, Mensa‑G achieves 2.4× better energy efficiency and 4.3× higher throughput.
The paper’s contributions are threefold: (1) the first in‑depth, per‑layer characterization of the Edge TPU on a broad set of modern edge models, revealing severe under‑utilization and memory bottlenecks; (2) the identification that layer heterogeneity, both across and within models, is the root cause of these inefficiencies; and (3) the design of the Mensa framework and its concrete Mensa‑G implementation, which demonstrates that a small set of heterogeneous, purpose‑built accelerators combined with intelligent scheduling can dramatically improve edge AI performance and energy consumption. The work suggests a new design paradigm for future edge ML accelerators: co‑design of PE arrays, dataflows, and memory subsystems that are tailored to the specific characteristics of the workload rather than relying on a monolithic, one‑size‑fits‑all architecture.
Comments & Academic Discussion
Loading comments...
Leave a Comment