Adopting Automated Bug Assignment in Practice -- A Registered Report of an Industrial Case Study
📝 Abstract
[Background/Context] The continuous inflow of bug reports is a considerable challenge in large development projects. Inspired by contemporary work on mining software repositories, we designed a prototype bug assignment solution based on machine learning in 2011-2016. The prototype evolved into an internal Ericsson product, TRR, in 2017-2018. TRR’s first bug assignment without human intervention happened in 2019. [Objective/Aim] Our exploratory study will evaluate the adoption of TRR within its industrial context at Ericsson. We seek to understand 1) how TRR performs in the field, 2) what value TRR provides to Ericsson, and 3) how TRR has influenced the ways of working. Secondly, we will provide lessons learned related to productization of a research prototype within a company. [Method] We design an industrial case study combining interviews with TRR developers and users with analysis of data extracted from the bug tracking system at Ericsson. Furthermore, we will analyze sprint planning meetings recorded during the productization. Our data analysis will include thematic analysis, descriptive statistics, and Bayesian causal analysis.
💡 Analysis
[Background/Context] The continuous inflow of bug reports is a considerable challenge in large development projects. Inspired by contemporary work on mining software repositories, we designed a prototype bug assignment solution based on machine learning in 2011-2016. The prototype evolved into an internal Ericsson product, TRR, in 2017-2018. TRR’s first bug assignment without human intervention happened in 2019. [Objective/Aim] Our exploratory study will evaluate the adoption of TRR within its industrial context at Ericsson. We seek to understand 1) how TRR performs in the field, 2) what value TRR provides to Ericsson, and 3) how TRR has influenced the ways of working. Secondly, we will provide lessons learned related to productization of a research prototype within a company. [Method] We design an industrial case study combining interviews with TRR developers and users with analysis of data extracted from the bug tracking system at Ericsson. Furthermore, we will analyze sprint planning meetings recorded during the productization. Our data analysis will include thematic analysis, descriptive statistics, and Bayesian causal analysis.
📄 Content
[배경/맥락]
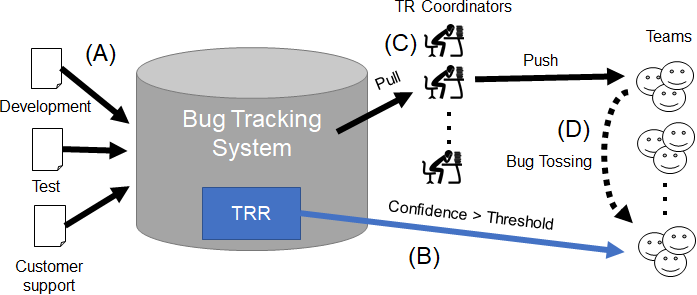
지속적인 버그 보고서의 유입은 대규모 소프트웨어 개발 프로젝트에서 매우 큰 도전 과제로 작용한다. 버그가 끊임없이 쌓여 가면서 이를 적절히 분류하고 담당 개발자에게 할당하는 작업은 인적 자원과 시간 모두를 크게 소모하게 된다. 이러한 문제점을 해결하고자 2010년대 초반부터 소프트웨어 저장소(Repository)를 마이닝하는 최신 연구들이 활발히 진행되었으며, 특히 머신러닝 기법을 활용한 자동화된 버그 할당 방법론에 대한 관심이 급증하였다. 이러한 학술적 흐름에 영감을 받아, 우리는 2011년부터 2016년까지 머신러닝 기반 프로토타입 버그 할당 솔루션을 설계·구현하였다. 초기 프로토타입은 여러 공개 데이터셋을 이용해 알고리즘의 정확도와 효율성을 검증하는 단계에 머물렀지만, 동시에 실제 산업 현장에서 적용 가능성을 탐색하기 위한 파일럿 프로젝트도 병행하였다.
그 결과, 2017년에서 2018년 사이에 이 프로토타입은 에릭슨(Ericsson) 내부에서 **TRR(자동 버그 할당 시스템, “Ticket Routing Robot”)**이라는 정식 제품 형태로 전환되었다. TRR은 에릭슨이 보유한 방대한 버그 트래킹 시스템과 연동되어, 새로운 버그가 보고될 때마다 자동으로 해당 버그의 특성을 분석하고, 가장 적합한 담당 팀이나 엔지니어에게 할당하는 기능을 제공한다. 특히, 인간의 개입 없이 최초로 버그를 자동 할당한 사례는 2019년에 발생했으며, 이는 TRR이 실제 운영 환경에서 실질적인 가치를 창출하기 시작했음을 의미한다.
[목표/목적]
본 탐색적 연구는 에릭슨이라는 대규모 글로벌 통신 장비 제조업체의 산업 현장에서 TRR이 어떻게 채택되고 활용되는지를 체계적으로 평가하는 것을 주요 목표로 설정한다. 구체적으로는 다음과 같은 세 가지 핵심 질문에 답하고자 한다.
- 현장 성능 평가 – 실제 운영 환경(Production Environment)에서 TRR이 보여주는 정확도(Precision), 재현율(Recall), 처리 속도(Throughput) 등 정량적 성능 지표는 어떠한가? 또한, 기존의 수동 할당 프로세스와 비교했을 때 시간 절감 효과와 오류 감소 효과는 어느 정도인가?
- 비즈니스 가치 파악 – TRR이 에릭슨에 제공하는 직접적인 경제적 가치(예: 인건비 절감, 버그 해결 시간 단축)와 간접적인 조직 문화적 가치(예: 개발자 만족도 향상, 협업 효율성 증대)는 무엇인가? 특히, 제품 출시 주기(Time‑to‑Market)에 미치는 영향을 정량화하고자 한다.
- 업무 방식 변화 분석 – TRR 도입 이후 개발팀, QA팀, 운영팀 등 다양한 이해관계자들의 업무 흐름이 어떻게 변했는지, 새로운 역할(예: “TRR 관리자”, “자동 할당 검증 담당자”)이 생겨났는지, 그리고 기존 프로세스와의 충돌이나 조정 과정에서 나타난 조직적 저항 혹은 수용 사례는 무엇인지 파악한다.
두 번째 목표는 연구 프로토타입을 기업 내 상용 제품으로 전환(productization)하는 과정에서 얻은 교훈을 정리하고, 향후 유사한 기술 이전 사례에 적용 가능한 베스트 프랙티스와 함정(pitfall)을 도출하는 것이다. 이를 통해 학계와 산업계가 협업하여 연구 성과를 실제 비즈니스 가치로 전환하는 데 필요한 전략적 인사이트를 제공하고자 한다.
[방법]
본 연구는 산업 현장 사례 연구(Industrial Case Study) 설계에 기반한다. 구체적인 데이터 수집 및 분석 절차는 다음과 같다.
심층 인터뷰(Deep Interviews) – TRR을 직접 개발한 엔지니어(알고리즘 개발자, 데이터 엔지니어, 시스템 통합 담당자)와 TRR을 실제 업무에 활용하고 있는 최종 사용자(버그 트래커, 개발 팀 리더, QA 매니저)들을 대상으로 반구조화된 인터뷰를 진행한다. 인터뷰 가이드는 TRR의 설계 의도, 구현 과정, 도입 초기 문제점, 현재 사용상의 장점·단점, 향후 개선 요구사항 등을 포괄하도록 설계한다. 각 인터뷰는 최소 60분 이상 진행되며, 녹음 후 전문 전사(Transcription) 과정을 거쳐 텍스트 데이터로 변환한다.
버그 트래킹 시스템 데이터 추출(Bug Tracking System Data Extraction) – 에릭슨이 운영하는 내부 버그 트래킹 툴(JIRA, Bugzilla 등)에서 2019년부터 현재까지의 버그 보고서, 할당 기록, 해결 시간, 담당자 변경 로그 등을 추출한다. 추출된 원시 데이터는 개인정보 및 보안 정책에 따라 익명화(Anonymization) 처리한 뒤, 구조화된 데이터베이스 형태로 정제한다.
스프린트 플래닝 회의 녹화 분석(Sprint Planning Meeting Recording Analysis) – TRR 제품화 과정 중에 진행된 스프린트 플래닝 회의(Planning Meeting)와 리뷰 회의(Review Meeting)의 녹화 영상을 확보하고, 회의록과 함께 내용 분석을 수행한다. 회의 내용에서는 요구사항 정의, 우선순위 결정, 구현 진행 상황, 테스트 결과, 배포 전략 등에 대한 논의가 포함된다.
데이터 분석 방법
- 주제 분석(Thematic Analysis) – 인터뷰 전사본과 회의록을 코딩(Coding)하고, 주요 테마(예: “자동 할당 정확도”, “조직 문화 변화”, “기술적 장애물”)를 도출한다. 코딩 작업은 두 명 이상의 연구자가 독립적으로 수행하고, 상호 검증(inter‑coder reliability)을 통해 신뢰성을 확보한다.
- 기술 통계(Descriptive Statistics) – 버그 트래킹 데이터에 대해 평균, 중앙값, 표준편차, 분포 등을 계산하고, TRR 도입 전후의 KPI(Key Performance Indicator) 변화를 시각화한다. 특히, 버그 해결 평균 소요 시간(MTTD, Mean Time To Diagnose)과 평균 해결 시간(MTTR, Mean Time To Resolve)의 변화를 중점적으로 분석한다.
- 베이지안 인과 분석(Bayesian Causal Analysis) – TRR 도입이 버그 처리 효율성에 미친 인과적 효과를 추정하기 위해 베이지안 구조 방정식 모델(Bayesian Structural Equation Modeling, BSEM)을 적용한다. 사전 분포(prior distribution)는 기존 문헌과 사전 인터뷰 결과를 바탕으로 설정하고, 마르코프 체인 몬테 카를로(MCMC) 샘플링을 통해 사후 분포(posterior distribution)를 추정한다. 이를 통해 TRR의 효과 크기(effect size)와 신뢰 구간(credible interval)을 정량적으로 제시한다.
통합 해석(Integrated Interpretation) – 정성적 주제 분석 결과와 정량적 통계·베이지안 인과 분석 결과를 교차 검증(cross‑validation)하고, 서로 보완하는 형태로 종합적인 인사이트를 도출한다. 최종적으로는 TRR의 현장 성과, 비즈니스 가치, 조직 문화 변화를 체계적으로 정리하고, 제품화 과정에서 발견된 성공 요인과 위험 요인을 도표와 사례 중심으로 제시한다.
이와 같은 다각적인 연구 설계와 분석 절차를 통해, 우리는 에릭슨 내에서 TRR이 실제로 어떻게 작동하고 있는지, 그리고 연구 단계에서 상용 제품으로 전환되는 과정에서 어떤 교훈을 얻을 수 있는지를 심도 있게 밝히고자 한다. 이러한 결과는 향후 다른 대규모 소프트웨어 기업이 머신러닝 기반 자동화 도구를 도입·운영하는 데 있어 실질적인 가이드라인을 제공할 것으로 기대한다.