Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data
In many applications, one works with neural network models trained by someone else. For such pretrained models, one may not have access to training data or test data. Moreover, one may not know details about the model, e.g., the specifics of the training data, the loss function, the hyperparameter values, etc. Given one or many pretrained models, it is a challenge to say anything about the expected performance or quality of the models. Here, we address this challenge by providing a detailed meta-analysis of hundreds of publicly-available pretrained models. We examine norm based capacity control metrics as well as power law based metrics from the recently-developed Theory of Heavy-Tailed Self Regularization. We find that norm based metrics correlate well with reported test accuracies for well-trained models, but that they often cannot distinguish well-trained versus poorly-trained models. We also find that power law based metrics can do much better – quantitatively better at discriminating among series of well-trained models with a given architecture; and qualitatively better at discriminating well-trained versus poorly-trained models. These methods can be used to identify when a pretrained neural network has problems that cannot be detected simply by examining training/test accuracies.
💡 Research Summary
The paper tackles a practical problem that arises when users are handed pretrained neural network models without any access to the original training or test datasets, nor any detailed knowledge of the training protocol, loss function, or hyper‑parameter settings. The authors ask whether it is possible to predict the quality of such models solely from their weight matrices. To answer this, they conduct a large‑scale meta‑analysis of several hundred publicly available pretrained models, primarily from computer‑vision (VGG, ResNet, DenseNet) and natural‑language‑processing (GPT, GPT‑2) families.
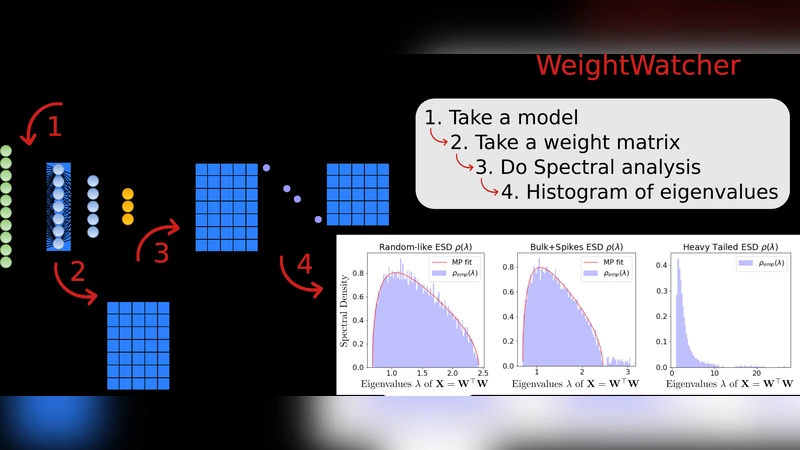
Two families of metrics are evaluated. The first consists of traditional norm‑based measures: Frobenius norm, spectral norm, and the α‑norm (a generalized Schatten norm). For each layer the chosen norm is computed, then an average of the logarithms across layers is taken, yielding a scalar “log‑norm” that serves as a proxy for model complexity C≈∏ₗ‖Wₗ‖. The second family derives from the Heavy‑Tailed Self‑Regularization (HT‑SR) theory. Here the authors form the uncentered correlation matrix X = WᵀW for each layer, compute its eigenvalue spectrum, and fit the bulk of the spectrum to a truncated power‑law ρ(λ)∝λ⁻ᵅ over a range
Comments & Academic Discussion
Loading comments...
Leave a Comment