Online learning of neural networks based on a model-free control algorithm
We explore the possibilities of using a model-free-based control law in order to train artificial neural networks. In the supervised learning context, we consider the problem of tuning the synaptic weights as a feedback control tracking problem where…
Authors: Lo"ic Michel
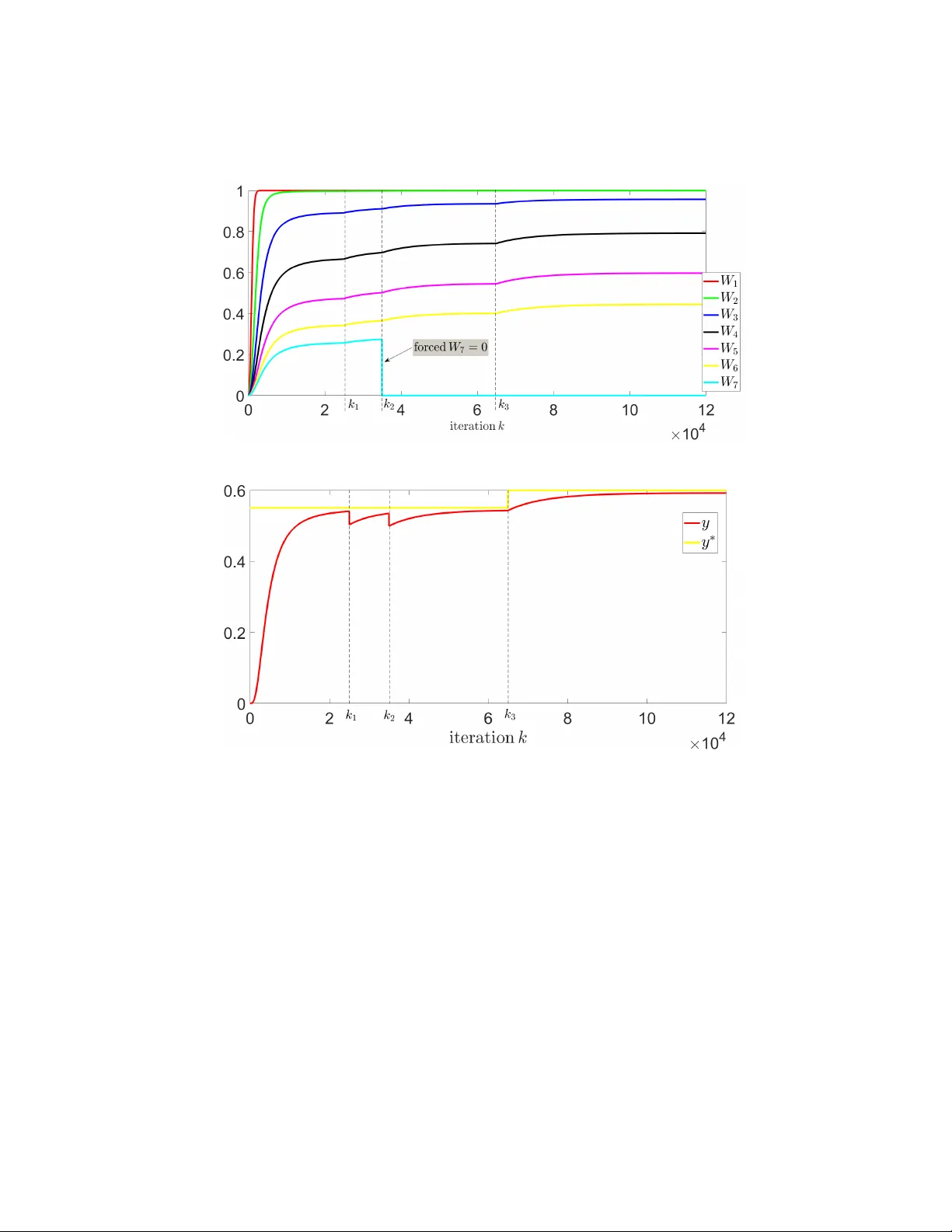
Online learning of neural net w orks based on a mo del-free con trol algorithm Lo ¨ ıc MICHEL ´ Ecole cen trale de Nantes-LS2N, UMR 6004 CNRS, Nan tes, F rance loic.michel@ec-nantes.fr Abstract. W e explore the p ossibilities of using a mo del-free-based con- trol la w in order to train artificial neural netw orks. In the sup ervised learning context, w e consider the problem of tuning the synaptic w eigh ts as a feedback con trol tracking problem where the control algorithm ad- justs the w eights online according to the input-output training data set of the neural netw ork. Numerical results illustrate the dynamical learning pro cess and an example of classifier that show very promising prop erties of our prop osed approac h. Keyw ords: adv anced optimization tec hniques · adv ances in mac hine learning · mo del-free con trol 1 In tro duction T raining a neural net work consists in tuning its in ternal w eights in order to learn a mapping function from inputs to outputs and ev en tually examine what the mo del predicts [1]. Besides classical tuning techniques (see e.g. [2] and a survey in [3] that presents tuning methods to mo del complex manufacturing processes), some connections betw een adaptive con trol and optimization methods ha ve b een p oin ted out recently in [4,5] that highligh t a certain equiv alence b et ween using to ols from the adaptiv e control field and solving problems in the machine learning field. In this line of thinking, the motiv ation of this work is to propose a strategy to tune neural netw orks using the so-called mo del-free control algorithm in the con text of sup ervised learning. The model-free con trol methodology , originally proposed b y [6], has b een de- signed to control a priori an y ”unknown” dynamical system in a ”robust” man- ner, and can b e considered as an alternativ e to standard PI and PID con trol [7] as it does not need an y prior kno wledge of the plan t to con trol. Its usefulness has b een demonstrated through successful applications 1 , and in particular, an appli- cation dedicated to the supply c hain management [9] has b een recently prop osed. A deriv ative-free-based v ersion of this control algorithm has b een prop osed by the author in [10], for which some in teresting capabilities of online optimization ha ve b een highlighted. 1 See e.g. the references in [6,8,9] and the references therein for an ov erview of the applications. 2 L. Mic hel A t the intersection b et ween control, optimization and machine learning, in this w ork, we consider the training of a neural netw ork as a trac king con trol problem, where the proposed ”para-model” control technique [10] is exp erimented as a derivative-fr e e le arning algorithm to tune the weigh ts of the netw ork in order to fit online the training data. The pap er is organized as follow. Section 2 reviews the para-model approach. In Section 3, a preliminary example illustrates how a mo del-free-based distributed con trol could b e implemen ted in order to control multiple systems. Section 4 presen ts the application of the para-mo del control to train a simple neural net- w ork and numerical results are presen ted in Section 5 to illustrate the dynamical ev olution of the learning pro cess as w ell as an example of classifier. Section 6 giv es some concluding remarks. 2 Principle of the para-model control Consider a nonlinear SISO dynamical system f : u 7→ y to control ˙ x = f ( x , u ) y = g ( x ) (1) where f is the function describing the b eha vior of a nonlinear system and x ∈ I R is the state vector; the para-mo del con trol is an application C π : ( y, y ∗ ) 7→ u whose purp ose is to con trol the output y of (1) following an output reference y ∗ . In simulation, the system (1) is controlled in its ”original form ulation” without an y mo dification or linearization. F or any discrete momen t t k , k ∈ I N ∗ , one defines the discrete controller C π : ( y , y ∗ ) 7→ u as an integrator asso ciated to a numerical series ( Ψ k ) k ∈ I N suc h as sym b olically u k = C { K p ,K i ,k α ,k β } π ( y k , y ∗ k ) = Ψ k . Z t 0 K i ( y ∗ k − y k − 1 ) d τ (2) with the recursiv e term Ψ k = Ψ k − 1 + K p ( k α e − k β k − y k − 1 ) , where y ∗ is the output (or tracking) reference tra jectory; K p and K i are real p ositiv e tuning gains; ε k − 1 = y ∗ k − y k − 1 is the tracking error; k α e − k β k is an initialization function where k α and k β are real positive constants; practically , the in tegral part is discretized using e.g. Riemann sums. Online learning of neural netw orks based on a model-free control algorithm 3 Fig. 1. Prop osed para-mo del scheme to control a nonlinear system. Define the set of the C π -parameters of the con troller as the set of the tuning coef- ficien ts { K p , K i , k α , k β } 2 . The implementation of the control scheme is depicted in Fig. 1 where C π is the prop osed para-mo del controller. In the next section, an example is presented to illustrate how mo del-free-based distributed control can b e implemen ted in order to introduce the metho dology to train neural net works by controlling the corresp onding neural weigh ts. 3 Example of distributed mo del-free-based con trol : an amazing w a y to solv e Ax = b T o illustrate the prop erties of the prop osed para-mo del algorithm, consider the follo wing linear system Ax = b to solve 3 0 . 5 8 4 7 4 . 5 1 9 3 x 1 x 2 x 3 = 7 . 95 6 . 30 3 . 80 (3) where we denote x ∗ = x ∗ 1 x ∗ 2 x ∗ 3 T the solution of (3). Considering the controlled sub-system deriv ed from (3) x 7→ y : Ax , (4) the goal is to solve the system (3) as a tracking problem in such manner that in the sub-system (4), the con trolled y tracks y ∗ = b . Hence, if y is kept ”close” to b , then the con trolled x is ”close” to the solution x ∗ . Eac h v ariable x j , j = 1 ... 3 of (4) is driv en b y an autonomous C π j con troller, with resp ect to the tracking reference b j , j = 1 ... 3 such as ideally | y − b | → 0 in a finite time. The asso ciated con trol law C π j , that is asso ciated to each v ariable x j , j = 1 ... 3, reads 2 An interesting property that has b een observed with para-mo del con trol throughout the ov erall applications is the relative flexibilit y of the C π -parameters to obtain go od trac king p erformances while ”prototyping” a new pro cess to control. In particular, w e highlight the case of the exp erimen tal v alidation [11] for which no mathematical represen tative mo del of the nonlinear pro cess w as av ailable and the control has been tested under several w orking conditions using indeed the C π -parameters adjusted for the corresp onding simplified simulation. 4 L. Mic hel x j = C { K p j ,K i j ,k α j ,k β j } π j ( y j , b j ) (5) where the set of parameters { K p j , K i j , k α j , k β j } is asso ciated to the j th C π con troller. Figure 2 illustrates the evolution of the con trolled x v ersus the iterations that con verges to the solution x ∗ . Fig. 2. Evolution of the controlled vector x v ersus the iterations. 4 Application to the training of neural netw orks 4.1 Problem statement In the context of sup ervised learning, let us consider a neural net work describ ed as a ”blac k-b o x” mo del E E ( x 1 , x 2 , · · · , x n , y , W 1 , W 2 , · · · , W q ) = 0 (6) that is composed of n inputs x 1 , x 2 , · · · , x n ; an output y ; q synaptic w eights W 1 , W 2 , · · · , W q and a sigmoid activ ation function of the form y = tanh( . ) that defines the output of eac h neuron (no de). Giv en training data x train 1 , x train 2 , · · · , x train n and y train asso ciated resp ectiv ely to the inputs and to the output of E , w e assume that the algorithm (2) up dates eac h synaptic weigh t such as Online learning of neural netw orks based on a model-free control algorithm 5 W 1 = C { K p 1 ,K i 1 ,k α 1 ,k β 1 } π ( y , y train ) , W 2 = C { K p 2 ,K i 2 ,k α 2 ,k β 2 } π ( y , y train ) , . . . W q = C { K p q ,K i q ,k α q ,k β q } π ( y , y train ) . (7) and therefore, allo ws ”configuring” the neural netw ork (updates of the W i for all i = 1 ...q ) in suc h manner that asymptotically , the output y remains ”as close as p ossible” to y train . Since the neural netw ork do es not include any in ternal dynamic, a filter is asso ciated to each W i in order to include a dynamic regarding the prop er use of the C π con trollers (Fig. 1). R emark 1: Dep ending on the exp ected closed lo op transien t dynamic, a p ossible c hoice of the C π -parameters is to consider e.g. a decrease of the con trol amplifi- cation gains according to the q th no de i.e. K p q +1 < K p q , K i q +1 < K i q in order to obtain a goo d dynamic resp onse regarding possible changes of the model E and the rejection of external disturbances, like changes in the training data set. 4.2 Simple example of training T o illustrate our proposed training strategy , consider a three-node net work 3 , depicted in Fig. 3 including t wo inputs x 1 and x 2 and an output y . Fig. 3. Example of simple neural netw ork defined by E : ( x 1 , x 2 ) 7→ y . The strategy (7) is applied to calculate online the weigh ts W 1 , W 2 , · · · , W 7 giv en the training v alues x train 1 , x train 2 and y train (the latter corresponds to the output reference). A first order filter (with a small time constant) is added to include a dynamic to eac h controller. 3 Suc h small netw ork is still mathematically interesting to inv estigate [12]. 6 L. Mic hel 5 Numerical results T o present some preliminary prop erties, the follo wing test b enc h hav e b een p er- formed considering the initial set of training data x train 1 = 0 . 2, x train 2 = 0 . 6 and y train = 0 . 55. The C π -parameters hav e not b een optimized regarding the transien t responses and the W i are b ounded such as | W i | ≤ 1 for all i = 1 ... 7. All W i , i = 1 ... 7 are initialized to zero. Evolution of online mo dific ations of the network top olo gy and the tr aining data In formula (2), set K p = 1, K i = 1 / 100, k α = 333 / 2 and k β = 40 including a first order filter with a time constant of 10 − 5 s; the simulation time-step is 10 − 5 s. Figure 4 shows respectively the ev olution of the weigh ts and the controlled output y , when the netw ork is sub jected to an arbitrary change of its top ology (the weigh t W 7 is for example forced to zero at an arbitrary time) as w ell as arbitrary c hanges of the training data. As a result, a great tracking of the output y has been observ ed despite the differen t c hanges of the training data as well as the top ology of the net work, whic h is referred to as the ”Drop out” concept in e.g. [13,14]. A classifier example Consider training the three-no de net work as a classifier with the follo wing data training set x train 1 x train 2 y train = b ool( ( x train 1 + x train 2 ) < 0 . 8) 0.133 0.65 1 0.160 0.72 0 0.152 0.7 0 0.120 0.6 1 where y train is the b oolean test of ( x train 1 + x train 2 ) < 0 . 8. The following table illustrates a simple classification test and the resulting a v- erage of all output v alues y = 0 . 19 defines the output partition of the classifier ( i.e. classify the particular input v alues that pro duce a ”0” in output and vic e versa ). x 1 x 2 y b ool( ( x 1 + x 2 ) > y ) 0.23 0.75 0.44 1 -0.14 0.42 0.01 0 -0.24 0.3 -0.16 0 0.62 1.1 0.48 1 The set of data is prop erly classified according to the b oolean comparison with y . Remark that since the prop osed control-based training algorithm deals with dynamical systems and sweeps the training data through low pass filtering, the partition of the classifier via y corresp onds indeed to the ’filtered’ a v eraged v alue of the output training data. Online learning of neural netw orks based on a model-free control algorithm 7 (a) W eights W i (b) Output y and output reference y ∗ Fig. 4. Evolution of the weigh ts W i and the controlled output y versus iterations when the netw ork is sub jected to the changes x train 1 = 0 . 15 , x train 2 = 0 . 8 at k = k 1 and then y train = 0 . 6 at k = k 3 as well as also sub jected to a mo dification of the neural netw ork top ology (setting W 7 = 0) at k = k 2 . 6 Conclusion and p erspectives This pap er presented an application of the mo del-free-based control metho dology in the field of artificial neural netw orks. Encouraging results show promising trac king performances taking in to account online mo difications of the training data set as w ell as mo difications of the top ology of the studied net work. F urther 8 L. Mic hel w orks will include the formalization of our prop osed approac h (based e.g. on the implicit framew ork prop osed in [15]), as well as as inv estigations regarding the application of our prop osed algorithm to large scale neural netw orks including sp ecific netw orks used e.g. in decision supp ort systems [16]. References 1. G. Monta v on, W. Samek, and K.-R. M ¨ uller. Metho ds for interpreting and under- standing deep neural netw orks. Digital Signal Pr o c essing , 73:1–15, 2018. 2. C. C. Aggarwal. Neural Networks and De ep L e arning . Springer, 2018. 3. W. Sukthomy a and J. T anno c k. The training of neural netw orks to mo del man u- facturing pro cesses. Journal of Intel ligent Manufacturing , 16:39–51, 02 2005. 4. J. E. Gaudio, T. E. Gibson, A. M. Annaswam y, M. A. Bolender, and E. La vretsky. Connections b et ween adaptive control and optimization in mac hine learning. In 2019 IEEE 58th Confer enc e on De cision and Contr ol (CDC) , pages 4563–4568, 2019. 5. N. Matni, A. Proutiere, A. Ran tzer, and S. T u. F rom self-tuning regulators to reinforcemen t learning and bac k again. In 2019 IEEE 58th Confer enc e on De cision and Control (CDC) , pages 3724–3740, 2019. 6. M. Fliess and C. Join. Mo del-free con trol. International Journal of Contr ol , 86(12):2228–2252, 2013. 7. M. Fliess and C. Join. An alternativ e to prop ortional-in tegral and prop ortional- in tegral-deriv ative regulators: Intelligen t prop ortional-deriv ative regulators. Int J R obust Nonline ar Contr ol , pages 1–13, 2021. 8. O. Bara, M. Fliess, C. Join, J. Day , and S. M. Djouadi. T o ward a mo del-free feedbac k control synthesis for treating acute inflammation. Journal of The or etic al Biolo gy , 448:26 – 37, 2018. 9. K. Hamic he, M. Fliess, C. Join, and H. Ab oua ¨ ıssa. Bullwhip effect atten uation in supply chain management via control-theoretic to ols and short-term forecasts: A preliminary study with an application to p erishable inv entories. In 2019 6th Inter- national Confer enc e on Contr ol, De cision and Information T echnolo gies (CoDIT) , pages 1492–1497, 2019. 10. L. Michel. A para-mo del agen t for dynamical systems. pr eprint arXiv:1202.4707 , 2018. 11. L. Michel, O. Ghibaudo, O. Messal, A. Kedous-Leb ouc, C. Boudinet, F. Blache, and A. Labonne. Mo del-free based digital control for magnetic measurements. pr eprint arXiv:1703.05395 , 2017. 12. A. L. Blum and R. L. Rivest. T raining a 3-no de neural net work is np-complete. Neur al Networks , 5(1):117–127, 1992. 13. N. Sriv astav a, G. Hinton, A. Krizhevsky , I. Sutsk ever, and R. Salakhutdino v. Drop out: A simple w ay to prev ent neural netw orks from ov erfitting. J. Mach. L e arn. R es. , 15(1):1929–1958, 2014. 14. A. Labach, H. Salehinejad, and S. V alaee. Surv ey of dropout methods for deep neural net works. pr eprint arXiv:1904.13310 , 2019. 15. L. El Ghaoui, F. Gu, B. T rav acca, A. Ask ari, and A. Y. Tsai. Implicit deep learning. pr eprint arXiv:1908.06315 , 2020. 16. D. Delen and R. Sharda. A rtificial Neur al Networks in De cision Support Systems , pages 557–580. Springer Berlin Heidelb erg, Berlin, Heidelb erg, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment