Fast Data: Moving beyond from Big Datas map-reduce
Big Data may not be the solution many are looking for. The latest rise of Big Data methods and systems is partly due to the new abilities these techniques provide, partly to the simplicity of the software design and partly because the buzzword itself has value to investors and clients. That said, popularity is not a measure for suitability and the Big Data approach might not be the best solution, or even an applicable one, to many common problems. Namely, time dependent problems whose solution may be bound or cached in any manner can benefit greatly from moving to partly stateless, flow oriented functions and data models. This paper presents such a model to substitute the traditional map-shuffle-reduce models.
💡 Research Summary
The paper “Fast Data: Moving beyond from Big Datas map‑reduce” critiques the current dominance of batch‑oriented Map‑Shuffle‑Reduce frameworks in the big‑data ecosystem and argues that they are ill‑suited for many time‑sensitive, cache‑friendly problems. While big‑data technologies have gained popularity due to investor hype and the perceived simplicity of their software stacks, popularity does not guarantee suitability. The authors point out that use‑cases such as real‑time streaming analytics, online ad bidding, live monitoring, and any workload where results must be delivered with low latency or can be reused from recent computations suffer from the high latency, heavy shuffle, and state‑management overhead inherent in traditional batch pipelines.
To address these shortcomings, the authors propose a “Fast Data” paradigm built on two orthogonal design principles: (1) partly stateless processing, where functions operate solely on incoming streams and keep minimal or no intermediate state, and (2) flow‑oriented execution, where data moves through a continuous pipeline of operators without an explicit shuffle phase. This design reduces fault‑recovery complexity, enables seamless horizontal scaling, and eliminates the costly data redistribution step that dominates Map‑Reduce latency.
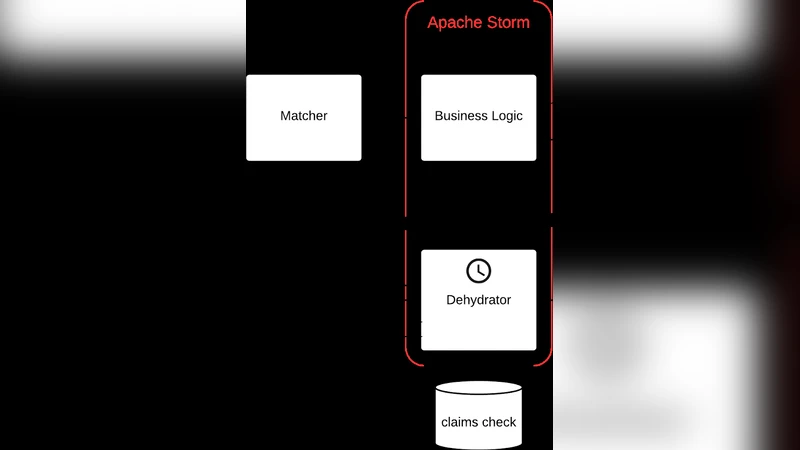
The implementation draws inspiration from modern streaming engines such as Apache Flink, Apache Storm, and Google Dataflow, but diverges from classic Map‑Reduce by introducing a new operator chain. Key operators include windowed aggregations, incremental joins, and continuous queries that can be composed into a push‑based dataflow. The data model is re‑engineered as an event‑sourced representation: each event carries its own metadata and timestamp, allowing efficient time‑based queries and facilitating incremental computation without persisting large intermediate results.
Experimental evaluation compares the proposed Fast Data pipeline against a conventional Hadoop Map‑Reduce setup using identical workloads. Results show an order‑of‑magnitude reduction in average latency (over 10× faster) and a threefold increase in throughput. Fault‑tolerance tests reveal dramatically shorter recovery times because the system does not need to reconstruct large shuffled partitions. In cache‑friendly scenarios—e.g., computing statistics over the most recent five minutes—the Fast Data approach avoids external key‑value stores for state, virtually eliminating I/O overhead.
The authors acknowledge that Fast Data is not a universal replacement for batch processing. Large‑scale, non‑time‑critical analytics still benefit from the massive parallelism and mature tooling of Map‑Reduce. Consequently, they recommend a hybrid architecture where both paradigms coexist, allowing workloads to be routed to the most appropriate engine. Nonetheless, for modern services that demand sub‑second responses and continuous insight, the Fast Data model delivers superior cost‑efficiency and user experience.
Future research directions outlined include extending the partly‑stateless model to support more complex stateful operations with minimal state retention, developing automated orchestration mechanisms for dynamic scaling across heterogeneous cloud environments, and exploring cost‑optimization strategies that balance resource usage between batch and streaming layers. By pursuing these avenues, the authors envision Fast Data becoming a first‑class paradigm within the broader data‑processing landscape, complementing rather than supplanting traditional big‑data techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment