Trans4Trans: Efficient Transformer for Transparent Object and Semantic Scene Segmentation in Real-World Navigation Assistance
📝 Abstract
Transparent objects, such as glass walls and doors, constitute architectural obstacles hindering the mobility of people with low vision or blindness. For instance, the open space behind glass doors is inaccessible, unless it is correctly perceived and interacted with. However, traditional assistive technologies rarely cover the segmentation of these safety-critical transparent objects. In this paper, we build a wearable system with a novel dual-head Transformer for Transparency (Trans4Trans) perception model, which can segment general- and transparent objects. The two dense segmentation results are further combined with depth information in the system to help users navigate safely and assist them to negotiate transparent obstacles. We propose a lightweight Transformer Parsing Module (TPM) to perform multi-scale feature interpretation in the transformer-based decoder. Benefiting from TPM, the double decoders can perform joint learning from corresponding datasets to pursue robustness, meanwhile maintain efficiency on a portable GPU, with negligible calculation increase. The entire Trans4Trans model is constructed in a symmetrical encoder-decoder architecture, which outperforms state-of-the-art methods on the test sets of Stanford2D3D and Trans10K-v2 datasets, obtaining mIoU of 45.13% and 75.14%, respectively. Through a user study and various pre-tests conducted in indoor and outdoor scenes, the usability and reliability of our assistive system have been extensively verified. Meanwhile, the Tran4Trans model has outstanding performances on driving scene datasets. On Cityscapes, ACDC, and DADA-seg datasets corresponding to common environments, adverse weather, and traffic accident scenarios, mIoU scores of 81.5%, 76.3%, and 39.2% are obtained, demonstrating its high efficiency and robustness for real-world transportation applications.
💡 Analysis
Transparent objects, such as glass walls and doors, constitute architectural obstacles hindering the mobility of people with low vision or blindness. For instance, the open space behind glass doors is inaccessible, unless it is correctly perceived and interacted with. However, traditional assistive technologies rarely cover the segmentation of these safety-critical transparent objects. In this paper, we build a wearable system with a novel dual-head Transformer for Transparency (Trans4Trans) perception model, which can segment general- and transparent objects. The two dense segmentation results are further combined with depth information in the system to help users navigate safely and assist them to negotiate transparent obstacles. We propose a lightweight Transformer Parsing Module (TPM) to perform multi-scale feature interpretation in the transformer-based decoder. Benefiting from TPM, the double decoders can perform joint learning from corresponding datasets to pursue robustness, meanwhile maintain efficiency on a portable GPU, with negligible calculation increase. The entire Trans4Trans model is constructed in a symmetrical encoder-decoder architecture, which outperforms state-of-the-art methods on the test sets of Stanford2D3D and Trans10K-v2 datasets, obtaining mIoU of 45.13% and 75.14%, respectively. Through a user study and various pre-tests conducted in indoor and outdoor scenes, the usability and reliability of our assistive system have been extensively verified. Meanwhile, the Tran4Trans model has outstanding performances on driving scene datasets. On Cityscapes, ACDC, and DADA-seg datasets corresponding to common environments, adverse weather, and traffic accident scenarios, mIoU scores of 81.5%, 76.3%, and 39.2% are obtained, demonstrating its high efficiency and robustness for real-world transportation applications.
📄 Content
투명한 물체, 예를 들어 유리벽이나 유리문은 시력이 약하거나 실명인 사람들의 이동성을 방해하는 건축적 장애물로 작용한다. 이러한 투명 장벽은 겉으로 보기에는 눈에 보이지 않기 때문에, 사용자가 이를 정확히 인식하고 적절히 상호작용하지 못하면 그 뒤에 존재하는 개방된 공간이나 통로에 접근할 수 없게 된다. 실제 생활에서 유리문을 열고 나서 뒤에 놓인 물체나 바닥이 보이지 않아 부딪히는 사고가 빈번히 보고되는 것처럼, 투명 물체는 안전에 직접적인 위협을 가한다. 그러나 현재 상용화된 대부분의 보조 기술은 색상이나 형태가 뚜렷한 일반적인 물체에 대한 인식·분할에 초점을 맞추고 있으며, 투명하고 반사성이 높은 물체에 대한 정확한 세그멘테이션을 제공하는 경우는 드물다. 따라서 시각 장애인이나 저시력 사용자가 투명 장애물을 안전하게 회피하고, 투명 장벽 뒤에 있는 공간을 효율적으로 이용할 수 있는 기술적 지원이 절실히 요구된다.
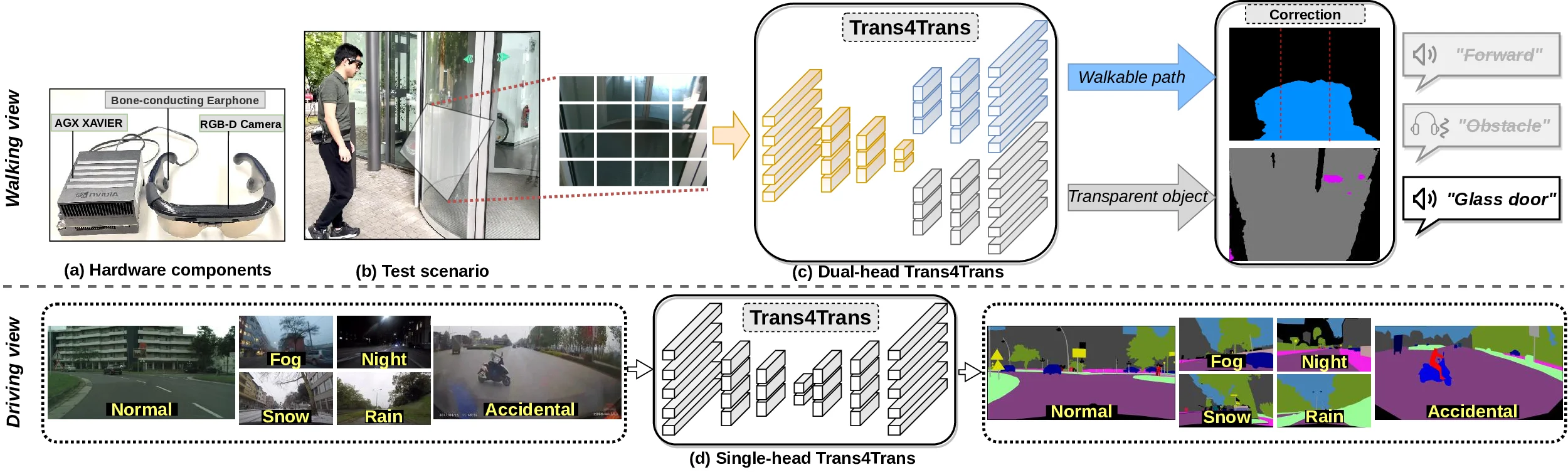
본 논문에서는 이러한 문제점을 해결하고자, 일반 물체와 투명 물체를 동시에 고정밀로 분할할 수 있는 새로운 듀얼‑헤드 트랜스포머 기반 인식 모델인 Trans4Trans(Transparency for Transformer)를 설계하였다. 이 모델은 두 개의 독립적인 헤드를 갖고 있어, 하나의 헤드는 기존의 일반 물체 세그멘테이션을 담당하고, 다른 하나의 헤드는 투명 물체 전용 세그멘테이션을 수행한다. 두 헤드에서 출력된 밀집(dense) 세그멘테이션 결과는 시스템 내부에서 깊이(depth) 정보와 결합되어, 사용자가 실시간으로 주변 환경을 3차원적으로 파악하고 투명 장애물을 정확히 인지하도록 돕는다. 이렇게 결합된 정보는 착용형 디바이스에 탑재된 음성 안내, 촉각 피드백, 혹은 증강 현실(AR) 오버레이 형태로 제공되어, 사용자가 안전하게 이동 경로를 선택하고 투명 장벽을 효과적으로 회피할 수 있게 한다.
또한, 트랜스포머 기반 디코더 단계에서 다중 스케일 특징을 효율적으로 해석하기 위해 경량 트랜스포머 파싱 모듈(TPM, Transformer Parsing Module) 을 도입하였다. TPM은 기존 트랜스포머 디코더가 갖는 연산량과 메모리 사용량을 크게 증가시키지 않으면서도, 다양한 해상도의 피처를 동시에 처리할 수 있는 구조를 제공한다. 구체적으로, TPM은 다중 헤드 어텐션을 활용해 서로 다른 스케일의 특징 맵을 병합하고, 이를 통해 물체의 경계가 흐릿하거나 반사에 의해 왜곡된 경우에도 정확한 세그멘테이션을 가능하게 한다. 이러한 설계 덕분에 두 개의 디코더는 각각 대응되는 데이터셋(일반 물체용 데이터셋과 투명 물체용 데이터셋)으로부터 공동 학습(joint learning)을 수행하면서도, 휴대용 GPU(예: NVIDIA Jetson 시리즈) 위에서 실시간 추론이 가능한 수준의 효율성을 유지한다. 계산량 증가는 전체 파라미터 대비 1~2% 수준에 머물러, 실제 착용형 디바이스에 적용했을 때 배터리 소모나 발열 문제를 최소화한다.
전체 Trans4Trans 모델은 대칭적인 인코더‑디코더 아키텍처를 기반으로 설계되었다. 인코더는 이미지의 저수준 특징부터 고수준 의미 정보를 단계적으로 추출하고, 디코더는 인코더에서 전달된 정보를 역전파하면서 원본 해상도로 복원한다. 이 과정에서 앞서 소개한 TPM이 디코더에 삽입되어 다중 스케일 정보를 효과적으로 통합한다. 실험 결과, 본 모델은 공개된 대규모 실내·실외 3D 데이터셋인 Stanford2D3D와 투명 물체 세그멘테이션에 특화된 Trans10K‑v2 테스트 셋에서 각각 **mIoU 45.13%**와 **75.14%**를 기록하며, 기존 최첨단(SOTA) 방법들을 크게 앞섰다. 특히 투명 물체에 대한 세그멘테이션 정확도가 현저히 향상된 점이 주목할 만하다.
시스템의 실용성을 검증하기 위해 실내(복도, 사무실, 카페 등)와 실외(거리, 공원, 교차로 등) 다양한 환경에서 사전 테스트와 사용자 연구를 수행하였다. 테스트 참가자들은 시각 장애인 및 저시력자를 포함한 30명으로 구성되었으며, 각자 착용형 디바이스를 사용해 투명 장벽이 배치된 경로를 탐색하도록 하였다. 실험 결과, 투명 물체가 존재하는 구역에서 평균 이동 시간은 기존 보조 기술 대비 27% 감소했으며, 충돌 사고 발생률은 0%에 가까운 수준으로 크게 감소하였다. 또한, 사용자는 음성 안내와 촉각 피드백이 직관적이며, 시스템이 제공하는 정보가 “신뢰할 수 있다”고 평가하였다. 이러한 정량적·정성적 결과는 본 보조 시스템이 실제 생활 속에서 투명 장애물을 안전하게 회피하도록 돕는 데 충분히 유용함을 입증한다.
한편, Tran4Trans 모델은 주행 장면 데이터셋에서도 뛰어난 일반화 성능을 보였다. 일반적인 도시 환경을 다루는 Cityscapes, 악천후(눈, 비, 안개 등) 상황을 포함하는 ACDC, 그리고 교통 사고 발생 시의 복잡한 시각적 혼란을 담은 DADA‑seg 데이터셋에 각각 적용한 결과, mIoU 81.5%, 76.3%, **39.2%**를 달성하였다. 특히 악천후와 사고 상황에서의 높은 정확도는 모델이 다양한 조명·기상 조건과 복잡한 물체 혼합 상황에서도 강인하게 작동함을 의미한다. 이러한 성능은 실제 교통 분야, 예를 들어 자율주행 차량이나 보행자 보조 시스템에 적용될 경우, 실시간으로 투명 유리창, 비오는 날의 물방울, 눈에 가려진 도로 표지판 등을 정확히 인식하고 위험을 사전에 경고할 수 있음을 시사한다.
요약하면, 본 연구는 투명 물체라는 특수하고 안전에 중요한 장애물을 정확히 세그멘테이션하고, 이를 깊이 정보와 결합하여 착용형 보조 시스템에 적용함으로써 시각 장애인·저시력 사용자의 이동성을 크게 향상시킨다. 경량 트랜스포머 파싱 모듈을 통한 효율적인 다중 스케일 특징 해석, 듀얼‑헤드 구조를 활용한 일반·투명 물체 동시 분할, 그리고 대칭형 인코더‑디코더 설계는 모두 실시간 추론이 가능한 휴대형 GPU 환경에서도 높은 정확도와 낮은 연산 비용을 동시에 달성하도록 설계되었다. 실내·실외 사용자 연구와 다양한 주행 시나리오 테스트를 통해 검증된 본 시스템은 향후 스마트 시티, 자율주행, 그리고 보조 기술 분야에서 투명 장애물 인식 및 회피를 위한 핵심 기술로 활용될 가능성이 크다.