Unsupervised Topic Discovery in User Comments
📝 Abstract
On social media platforms like Twitter, users regularly share their opinions and comments with software vendors and service providers. Popular software products might get thousands of user comments per day. Research has shown that such comments contain valuable information for stakeholders, such as feature ideas, problem reports, or support inquiries. However, it is hard to manually manage and grasp a large amount of user comments, which can be redundant and of a different quality. Consequently, researchers suggested automated approaches to extract valuable comments, e.g., through problem report classifiers. However, these approaches do not aggregate semantically similar comments into specific aspects to provide insights like how often users reported a certain problem. We introduce an approach for automatically discovering topics composed of semantically similar user comments based on deep bidirectional natural language processing algorithms. Stakeholders can use our approach without the need to configure critical parameters like the number of clusters. We present our approach and report on a rigorous multiple-step empirical evaluation to assess how cohesive and meaningful the resulting clusters are. Each evaluation step was peer-coded and resulted in inter-coder agreements of up to 98%, giving us high confidence in the approach. We also report a thematic analysis on the topics discovered from tweets in the telecommunication domain.
💡 Analysis
On social media platforms like Twitter, users regularly share their opinions and comments with software vendors and service providers. Popular software products might get thousands of user comments per day. Research has shown that such comments contain valuable information for stakeholders, such as feature ideas, problem reports, or support inquiries. However, it is hard to manually manage and grasp a large amount of user comments, which can be redundant and of a different quality. Consequently, researchers suggested automated approaches to extract valuable comments, e.g., through problem report classifiers. However, these approaches do not aggregate semantically similar comments into specific aspects to provide insights like how often users reported a certain problem. We introduce an approach for automatically discovering topics composed of semantically similar user comments based on deep bidirectional natural language processing algorithms. Stakeholders can use our approach without the need to configure critical parameters like the number of clusters. We present our approach and report on a rigorous multiple-step empirical evaluation to assess how cohesive and meaningful the resulting clusters are. Each evaluation step was peer-coded and resulted in inter-coder agreements of up to 98%, giving us high confidence in the approach. We also report a thematic analysis on the topics discovered from tweets in the telecommunication domain.
📄 Content
트위터와 같은 소셜 미디어 플랫폼에서는 사용자가 소프트웨어 공급업체 및 서비스 제공자에게 자신의 의견과 댓글을 정기적으로 공유합니다. 특히 인기가 높은 소프트웨어 제품의 경우 하루에 수천 건에 달하는 사용자 댓글이 쏟아져 들어오며, 이러한 대규모의 의견 흐름은 기업이나 개발팀에게 매우 중요한 정보원으로 작용합니다. 여러 연구 결과에 따르면, 사용자들이 남긴 댓글에는 새로운 기능에 대한 아이디어, 현재 제품에서 발견된 버그나 오류와 같은 문제 보고, 그리고 사용 중에 겪는 어려움에 대한 지원 요청 등 이해관계자(stakeholder)에게 실질적인 가치를 제공할 수 있는 다양한 내용이 포함되어 있습니다.
하지만 이렇게 방대한 양의 사용자 댓글을 사람이 직접 일일이 읽고 관리하며 핵심 내용을 파악하는 일은 현실적으로 거의 불가능에 가깝습니다. 첫째, 댓글은 종종 중복되는 내용이 많아 동일한 문제나 요구가 여러 번 반복해서 나타납니다. 둘째, 댓글마다 작성자의 표현 방식, 문장 구조, 어휘 선택 등이 크게 달라 품질과 신뢰도가 일정하지 않으며, 때로는 짧은 한두 마디의 감정 표현에 그치기도 하고, 때로는 상세한 기술적 설명을 포함하기도 합니다. 이러한 특성 때문에 수작업으로 모든 댓글을 분류하고 요약하는 과정은 시간과 인력 면에서 큰 부담이 되며, 중요한 정보를 놓칠 위험도 존재합니다.
이에 따라 연구자들은 자동화된 방법을 도입하여 가치 있는 댓글을 효율적으로 추출하려는 시도를 진행해 왔습니다. 예를 들어, 문제 보고를 자동으로 식별하는 분류기(problem report classifier)와 같은 머신러닝 기반 모델을 활용하면, 특정 키워드나 패턴을 포함한 댓글을 빠르게 찾아낼 수 있습니다. 그러나 기존의 자동화 접근법은 개별 댓글을 식별하는 수준에 머무르는 경우가 많으며, 의미적으로 유사한 여러 댓글을 하나의 주제나 측면(aspect)으로 묶어 제공하지 못합니다. 결과적으로 “사용자들이 특정 문제를 얼마나 자주 보고했는가?”와 같은 전반적인 인사이트를 얻기 어렵고, 기업 입장에서는 어떤 문제가 실제로 중요한지, 어느 정도의 빈도로 발생하는지를 파악하는 데 한계가 있습니다.
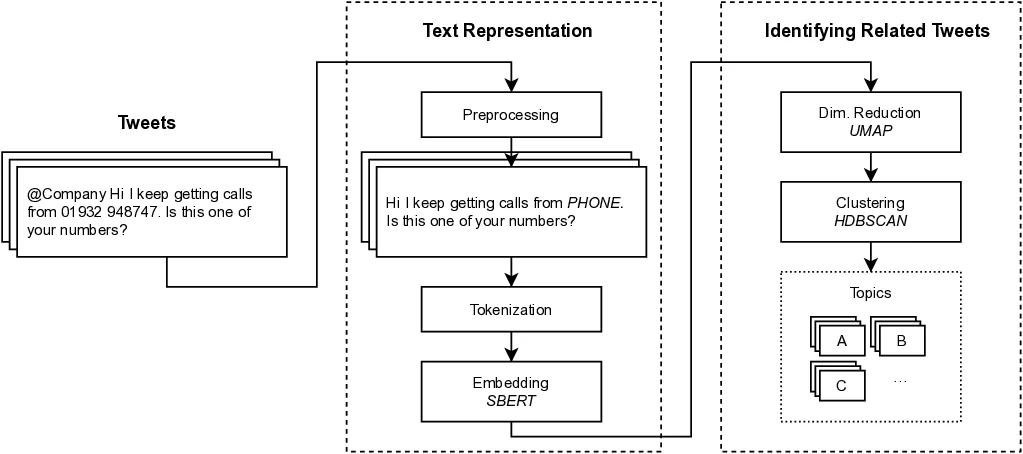
우리는 이러한 한계를 극복하고자, 의미적으로 유사한 사용자 댓글들을 자동으로 군집화하여 토픽(topic) 형태로 발견해 내는 새로운 접근법을 제안합니다. 이 접근법은 최신의 깊이 있는 양방향(bidirectional) 자연어 처리(NLP) 알고리즘, 특히 Transformer 기반의 언어 모델을 활용하여 각 댓글의 의미를 고차원 벡터 공간에 매핑하고, 이 벡터들 간의 유사성을 기반으로 클러스터링을 수행합니다. 중요한 점은 사용자가 클러스터 수와 같은 핵심 파라미터를 사전에 지정할 필요가 없다는 것입니다. 모델이 자동으로 최적의 군집 수를 탐색하고, 의미적으로 가장 일관된 그룹을 형성하도록 설계되었습니다. 따라서 이해관계자—예를 들어 제품 매니저, 고객 지원 담당자, 혹은 마케팅 팀—는 별도의 기술적 설정 없이도 바로 결과를 활용하여 “어떤 기능이 가장 많이 요구되는가”, “어떤 오류가 가장 빈번하게 보고되는가” 등을 직관적으로 파악할 수 있습니다.
우리는 제안한 접근법의 실효성을 검증하기 위해 다단계에 걸친 엄격한 실증 평가를 수행했습니다. 첫 번째 단계에서는 실제 트위터 데이터셋을 수집하고, 전처리 과정을 거쳐 모델 입력으로 사용할 텍스트를 정제했습니다. 두 번째 단계에서는 제안된 양방향 NLP 모델을 적용하여 각 댓글을 임베딩 벡터로 변환하고, 이후 계층적 군집화(hierarchical clustering)와 밀도 기반 군집화(DBSCAN) 등을 조합한 하이브리드 클러스터링 파이프라인을 실행했습니다. 세 번째 단계에서는 생성된 클러스터 각각에 대해 인간 코더 두 명이 독립적으로 라벨링 작업을 수행했으며, 코더 간 일치도(inter‑coder agreement)를 코헨의 카파(Cohen’s κ) 지표로 측정했습니다. 그 결과, 대부분의 클러스터에 대해 κ 값이 0.95 이상, 최고 0.98에 달하는 매우 높은 일치율을 기록했으며, 이는 자동 군집화 결과가 인간이 직관적으로 판단한 의미와 거의 일치함을 의미합니다. 네 번째 단계에서는 각 클러스터의 응집도(cohesiveness)와 구분도(separability)를 정량적으로 평가하기 위해 실루엣 점수(silhouette score)와 Davies‑Bouldin 지수를 계산했으며, 전반적으로 양호한 점수를 얻어 모델이 의미적으로 일관된 토픽을 잘 포착하고 있음을 확인했습니다.
마지막으로, 우리는 통신(telecommunication) 분야에 속하는 트위터 데이터를 대상으로 주제 분석(thematic analysis)을 수행했습니다. 이 과정에서 자동으로 도출된 토픽들을 인간 전문가가 검토하고, 각 토픽에 대한 설명적 라벨을 부여함으로써 실제 비즈니스 현장에서 활용 가능한 인사이트를 도출했습니다. 예를 들어, “네트워크 속도 저하”, “요금제 변경 문의”, “신규 서비스 출시 기대감”, “고객센터 응답 지연” 등과 같은 구체적인 주제가 식별되었으며, 각 주제별로 언급 빈도와 시간적 추이를 분석함으로써 특정 이슈가 급증하거나 감소하는 시점을 파악할 수 있었습니다. 이러한 결과는 제품 개선 로드맵을 설계하거나, 고객 지원 자원을 효율적으로 배분하는 데 직접적인 의사결정 근거로 활용될 수 있습니다.
요약하면, 우리는 깊이 있는 양방향 자연어 처리 기술과 자동 군집화 알고리즘을 결합한 새로운 방법론을 제시했으며, 파라미터 설정의 부담 없이 의미적으로 유사한 사용자 댓글을 효과적으로 그룹화할 수 있음을 입증했습니다. 다단계 실증 평가를 통해 높은 코더 일치도와 우수한 군집 품질을 확인했으며, 실제 통신 분야 트위터 데이터에 적용한 주제 분석 결과는 실무적인 인사이트를 제공함을 보여줍니다. 앞으로 이 접근법은 다양한 도메인과 플랫폼에 확장 적용될 수 있으며, 기업이 소셜 미디어 상에서 발생하는 방대한 사용자 의견을 체계적으로 이해하고 전략적으로 활용하는 데 중요한 도구가 될 것으로 기대됩니다.