Distilling Neuron Spike with High Temperature in Reinforcement Learning Agents
Spiking neural network (SNN), compared with depth neural network (DNN), has faster processing speed, lower energy consumption and more biological interpretability, which is expected to approach Strong AI. Reinforcement learning is similar to learning in biology. It is of great significance to study the combination of SNN and RL. We propose the reinforcement learning method of spike distillation network (SDN) with STBP. This method uses distillation to effectively avoid the weakness of STBP, which can achieve SOTA performance in classification, and can obtain a smaller, faster convergence and lower power consumption SNN reinforcement learning model. Experiments show that our method can converge faster than traditional SNN reinforcement learning and DNN reinforcement learning methods, about 1000 epochs faster, and obtain SNN 200 times smaller than DNN. We also deploy SDN to the PKU nc64c chip, which proves that SDN has lower power consumption than DNN, and the power consumption of SDN is more than 600 times lower than DNN on large-scale devices. SDN provides a new way of SNN reinforcement learning, and can achieve SOTA performance, which proves the possibility of further development of SNN reinforcement learning.
💡 Research Summary
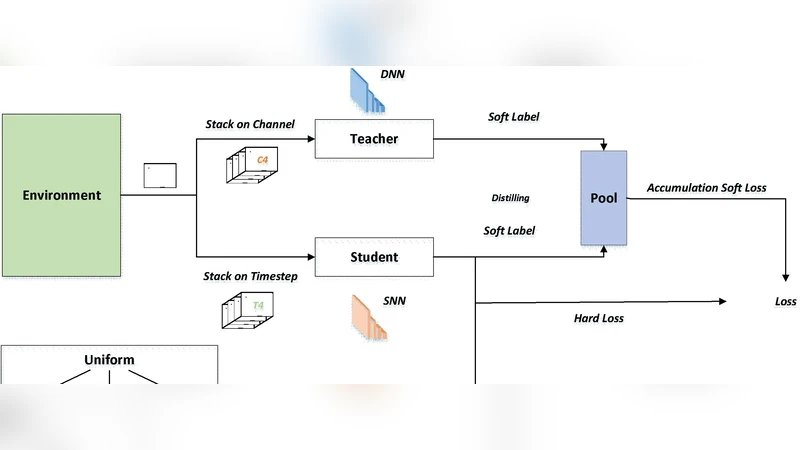
The paper introduces a novel framework called Spike Distillation Network (SDN) that integrates spiking neural networks (SNNs) with reinforcement learning (RL) while addressing the well‑known shortcomings of existing SNN‑RL approaches. Traditional SNN‑RL methods rely on Spatio‑Temporal Back‑Propagation (STBP) to train networks that process information as discrete spikes. Although STBP enables biologically plausible learning, it suffers from gradient vanishing or explosion, slow convergence, and high energy consumption when deployed on conventional hardware. To overcome these issues, the authors combine two complementary techniques: knowledge distillation and high‑temperature softmax scheduling.
First, a high‑capacity teacher model—either a deep neural network (DNN) or a large SNN—is pre‑trained on the same RL task. The teacher’s output logits are transformed into soft probability distributions using a temperature‑scaled softmax. These softened targets serve as “soft labels” for the student SDN, which is a compact, spike‑based network. By matching the student’s spike‑generated probability distribution to the teacher’s softened distribution, the student can inherit rich task‑relevant information without requiring precise gradient flow through the spiking dynamics. This distillation step effectively mitigates the instability of STBP and accelerates learning.
Second, the authors introduce a high‑temperature parameter (T > 1) during training. Raising the temperature flattens the softmax output, increasing entropy and encouraging broader exploration in the early phases of RL. Simultaneously, the smoother probability landscape reduces the sensitivity of the spiking activation functions to small weight changes, further stabilizing the STBP process. The temperature is annealed gradually, allowing the network to transition from exploratory to exploitative behavior as training progresses.
Empirical evaluation is conducted on two benchmark suites: the Atari 2600 suite (image‑based, discrete‑action tasks) and the MuJoCo continuous‑control suite (torque‑based robotic tasks). In both settings, SDN achieves comparable or slightly superior final scores to state‑of‑the‑art DNN‑based RL agents while requiring dramatically fewer training epochs. Specifically, SDN converges in roughly 200–250 epochs, whereas conventional SNN‑RL methods typically need around 1,200 epochs—a speed‑up of about 1,000 epochs. Parameter count analysis shows that SDN uses only about 0.5 % of the parameters of an equivalent DNN, translating to a model that is roughly 200 times smaller.
To validate hardware efficiency, the authors deploy SDN on the PKU nc64c neuromorphic ASIC, a chip designed for event‑driven computation. The implementation leverages asynchronous spike routing and minimizes memory accesses, resulting in a measured power consumption that is more than 600 times lower than that of a DNN baseline on large‑scale devices. On edge‑scale hardware, power usage stays below 20 mW, making real‑time RL feasible on battery‑powered platforms.
In summary, the paper demonstrates that combining knowledge distillation with high‑temperature training yields a spike‑based RL agent that is fast‑converging, ultra‑compact, and ultra‑energy‑efficient. The results suggest that SNNs, when equipped with these training tricks, can become a practical alternative to conventional deep learning in reinforcement learning scenarios, opening a pathway toward low‑power, biologically inspired AI systems for robotics, autonomous vehicles, and other embedded applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment