PIRM: Processing In Racetrack Memories
The growth in data needs of modern applications has created significant challenges for modern systems leading a “memory wall.” Spintronic Domain Wall Memory (DWM), related to Spin-Transfer Torque Memory (STT-MRAM), provides near-SRAM read/write performance, energy savings and nonvolatility, potential for extremely high storage density, and does not have significant endurance limitations. However, DWM’s benefits cannot address data access latency and throughput limitations of memory bus bandwidth. We propose PIRM, a DWM-based in-memory computing solution that leverages the properties of DWM nanowires and allows them to serve as polymorphic gates. While normally DWM is accessed by applying spin polarized currents orthogonal to the nanowire at access points to read individual bits, transverse access along the DWM nanowire allows the differentiation of the aggregate resistance of multiple bits in the nanowire, akin to a multilevel cell. PIRM leverages this transverse reading to directly provide bulk-bitwise logic of multiple adjacent operands in the nanowire, simultaneously. Based on this in-memory logic, PIRM provides a technique to conduct multi-operand addition and two operand multiplication using transverse access. PIRM provides a 1.6x speedup compared to the leading DRAM PIM technique for query applications that leverage bulk bitwise operations. Compared to the leading PIM technique for DWM, PIRM improves performance by 6.9x, 2.3x and energy by 5.5x, 3.4x for 8-bit addition and multiplication, respectively. For arithmetic heavy benchmarks, PIRM reduces access latency by 2.1x, while decreasing energy consumption by 25.2x for a reasonable 10% area overhead versus non-PIM DWM.
💡 Research Summary
**
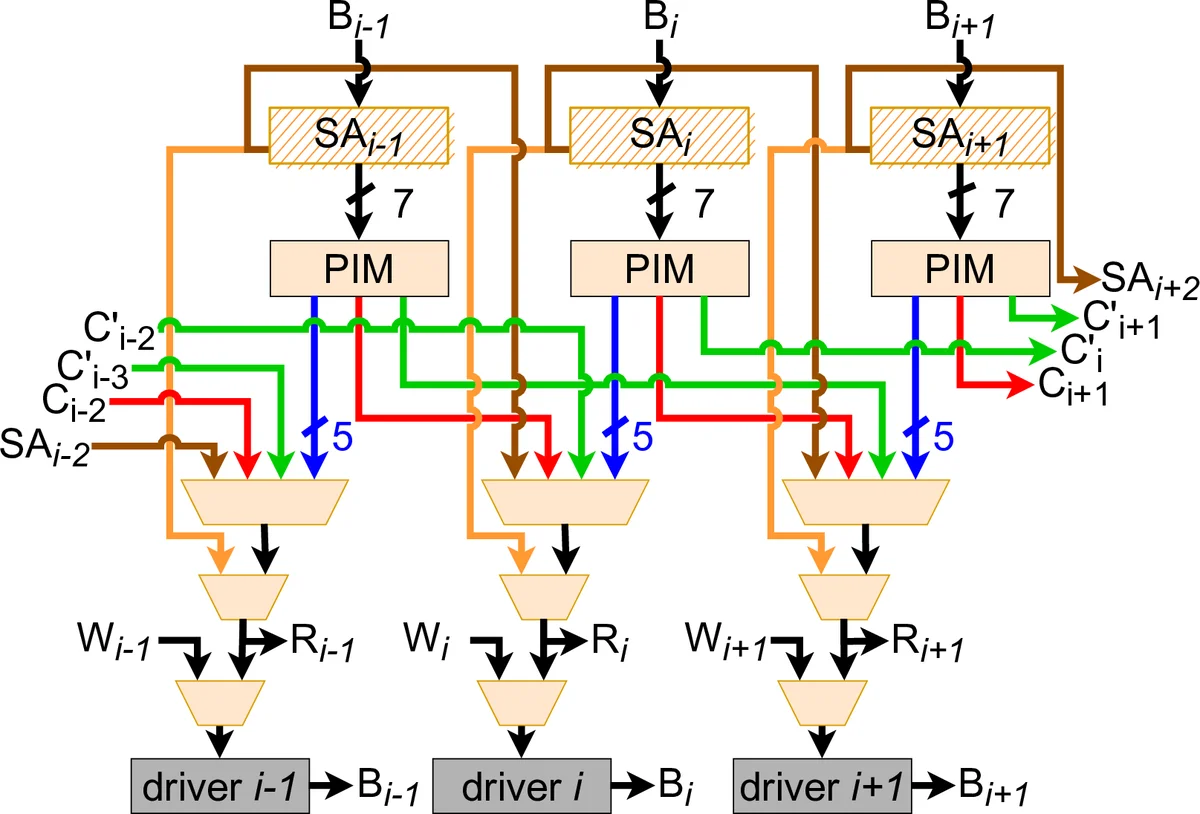
The paper introduces PIRM (Processing In Racetrack Memories), a novel in‑memory computing (IMC) approach that exploits the unique physics of Domain‑Wall Memory (DWM), also known as Racetrack Memory, to perform bulk‑bitwise and arithmetic operations directly inside the memory array. Traditional DWM reads individual bits by applying a spin‑polarized current orthogonal to the nanowire. PIRM instead uses two closely spaced access heads to drive a current along the nanowire (Transverse Read, TR) and to write/shift a segment in a single step (Transverse Write, TW).
TR measures the aggregate resistance of a contiguous group of magnetic domains, effectively counting the number of “1” bits present between the heads without revealing their positions. By mapping this count to a pre‑computed truth table, PIRM can realize any basic Boolean function across up to seven operands in a single cycle. Building on this capability, the authors design a multi‑operand adder that produces both sum and carry simultaneously using a combination of TR output, a pre‑charge sense amplifier, and a comparator. The adder supports five‑operand addition, which is then leveraged to implement 8‑bit multiplication via shift‑and‑add: one operand is shifted multiple times, each shifted version is fed to the multi‑operand adder, and the partial sums are accumulated in parallel.
At the architectural level, the memory is organized into Domain‑Block Clusters (DBCs). Each DBC contains X parallel nanowires (e.g., 512) and Y rows of domains (typically 32–64). A DBC shares local sensing circuitry and write drivers, and the two heads required for transverse operations are placed close enough to keep the TR distance (TRD) within the sensing margin. The overall organization mirrors conventional DRAM banks, sub‑arrays, and tiles, preserving the standard I/O interface and facilitating drop‑in adoption.
The evaluation compares PIRM against the leading DRAM‑based bulk‑bitwise schemes (Ambit, ELP²‑IM), the PCM bulk‑bitwise technique (Pinatubo), and two prior DWM‑based PIM proposals (DW‑NN and SPIM). For 8‑bit addition, PIRM achieves a 6.9× speedup and 5.5× energy reduction over the best existing DWM PIM (DW‑NN). For 8‑bit multiplication, it delivers a 2.3× speedup and 3.4× energy saving. Against the best DRAM bulk‑bitwise method, PIRM is 1.6× faster on query‑type workloads that rely heavily on bulk bitwise operations. In arithmetic‑heavy benchmarks, PIRM reduces average access latency by 2.1× and cuts energy consumption by 25.2×, while incurring only about a 10 % area overhead relative to a non‑PIM DWM implementation.
The authors acknowledge limitations: the number of domains that can be included in a TR is bounded by the sense‑margin, making the technique sensitive to process variation and temperature. TW requires fast, high‑current switching circuits, which add power and design complexity. Future work is suggested to extend the TR distance via multi‑level sensing, incorporate error‑correction schemes, and improve current‑efficiency of the write path.
In summary, PIRM demonstrates that by treating a DWM nanowire as a polymorphic gate through transverse operations, it is possible to execute multi‑operand bulk‑bitwise logic, multi‑operand addition, and efficient multiplication entirely within memory. This dramatically mitigates the memory‑wall bottleneck, offers superior performance and energy efficiency over existing DRAM, PCM, and DWM PIM approaches, and paves the way for high‑density, non‑volatile main memories that natively support general‑purpose computation.
Comments & Academic Discussion
Loading comments...
Leave a Comment