Structural Inductive Biases in Emergent Communication
In order to communicate, humans flatten a complex representation of ideas and their attributes into a single word or a sentence. We investigate the impact of representation learning in artificial agents by developing graph referential games. We empir…
Authors: Agnieszka S{l}owik, Abhinav Gupta, William L. Hamilton
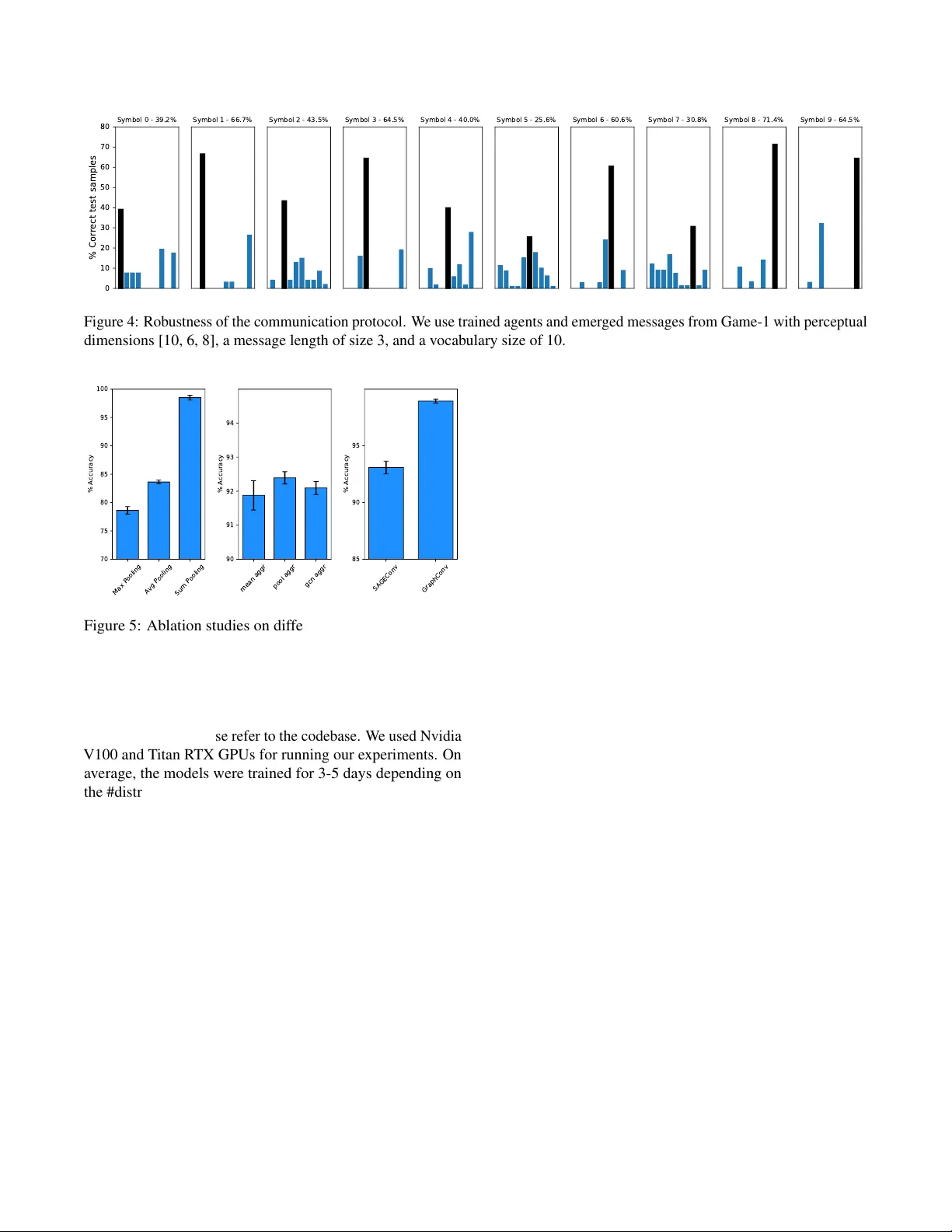
Structural Inductiv e Biases in Emergent Communication Agnieszka Słowik * Department of Computer Science and T echnology , Univ ersity of Cambridge agnieszka.slowik@cl.cam.ac.uk Abhinav Gupta * MILA abhinavg@nyu.edu William L. Hamilton School of Computer Science, McGill Univ ersity Mateja Jamnik Department of Computer Science and T echnology , Univ ersity of Cambridge Sean B. Holden Department of Computer Science and T echnology , Univ ersity of Cambridge Christopher Pal Polytechnique Montr ´ eal ServiceNow Abstract In order to communicate, humans flatten a complex represen- tation of ideas and their attributes into a single word or a sen- tence. W e in v estigate the impact of representation learning in artificial agents by dev eloping graph referential games. W e empirically show that agents parametrized by graph neural net- works develop a more compositional language compared to bag-of-words and sequence models, which allo ws them to sys- tematically generalize to new combinations of familiar features. Keyw ords: emergent communication; graph neural networks; language compositionality Introduction Human language is characterized by the ability to generate a potentially infinite number of sentences from a finite set of words. In principle, humans can use this ability to express and understand complex hierarchical and relational concepts, such as kinship relations and logical deduction chains. Existing multi-agent communication systems fail to compositionally generalize ev en on constrained symbolic data [Kottur et al., 2017]. For instance, if a person knows the meaning of utter- ances such as ‘red circle’ and ‘blue square’, she can easily understand the utterance ‘red square’ ev en if she has not en- countered this particular combination of shape and color in the past. This type of generalization capacity is referred to as compositionality [Smith et al., 2003, Andreas, 2019, Baroni, 2020] or systematic generalization [Bahdanau et al., 2019]. The ability to represent complex concepts and the relation- ships between them in the manner of a mental graph was found to be one of the ke y factors behind kno wledge generalization and prolonged learning in humans [Bellmund et al., 2018]. Through communication, humans flatten the non-Euclidean representation of ideas into a sequence of words. Advances in graph representation learning [Kipf and W elling, 2017] and sequence decoding [Sutske v er et al., 2014, Cho et al., 2014] provide the means for simulating this graph linearization pro- cess in the artificial agents. In emer gent communication studies, learning agents de velop a communication protocol from scratch through solving a * Equal Contribution. shared task, most commonly a refer ential game [Lazaridou et al., 2018, Guo et al., 2020]. Modelling communication as an interactiv e, goal-dri ven problem mitigates some of the issues observed in supervised training, such as sample inef ficiency and memorizing superficial signals rather than discovering the real factors of v ariation in the data [Lake et al., 2017, Baroni, 2020]. In this work, we analyze the effect of varying the input representation and the corresponding representation learning method on compositional generalization in referential games. Giv en the recent resurgence of strong structural bias in neural networks, we ev aluate the hypothesis that graph representa- tions encourage compositional generalization [Battaglia et al., 2018] in emergent communication. Related work In prior work using referential games, input data is repre- sented as sequences and bags-of-words [Lazaridou et al., 2018, Bouchacourt and Baroni, 2018] with few instances of using images as input [Lazaridou et al., 2018, Evtimova et al., 2018] and one instance of using graph encoders without a sequence decoder [Słowik et al., 2020, Gupta et al., 2020]. Notably , more information in the input does not necessarily lead to a more compositional language or higher generalization as sho wn in [Lazaridou et al., 2018]. Battaglia et al. [2018] claim that graph representations induce stronger compositional gen- eralization across a v ariety of reasoning and classification tasks. Recent work in relational reasoning [Sinha et al., 2019] supports this claim. En vironment Referential games A referential game in v olves two agents of fixed roles: the speaker and the listener . The speaker has access to the input data ( tar get ), which the listener cannot directly observ e. The speaker sends a message describing the target and the listener learns to recognize the target based on the message. In the referential games studied in this work, the listener receives the message and a set consisting of the tar get and distractor s , Graph Sequence Bag-of-wor ds Game-1 Game-2 A2 B7 C3 A2 B7 C3 A2 B7 C3 2 3 4 2 3 2 4 3 2 3 2 4 3 2 3 Figure 1: Structural biases in the input. Baselines of sequences and bags-of-words are constructed similarly as in the exist- ing work on emergent communication [K ottur et al., 2017, Lazaridou et al., 2018]. ne w objects sampled without replacement from the target data distribution. The agents are re warded if and only if the receiv er recognizes the target, and not for the messages sent. In the existing w ork, tar get and distractors are represented as bags- of-words, sequences or images. See the T raining section for details on training. Graph refer ential games W e extend existing referential games by dev eloping graph referential games: Game-1 and Game-2 . W e include corre- sponding representations of a lo wer degree of structure in order to study the effect of varying the input representation (Figure 1). Game-1: hierarch y of concepts and properties In this game, we construct a tree from a vector of [ p 1 , p 2 , . . . , p n ] (which we will refer to as perceptual dimensions ) where n corresponds to the number of properties and p 1 , p 2 , . . . , p n denote the number of possible types per property . Each tree has the same number of properties n and they only differ in the property values. Formally , each tree is an undirected graph G ( V , E ) where V is the set of all nodes representing unique properties along with a ‘central’ node, and E is the set of edges. The central node corresponds to a conceptually more abstract representation of the input, which is initially empty and then learned by a graph agent based on the object properties. The node features consist of a concatenation of the property encoding and the type encoding (represented as one-hot vectors). Game-2: relational concepts In this game, we ev aluate the graph agents using arbitrary undirected graphs of varying edges. Such graphs can be used to represent relations between arbitrary entities, e.g. connections between users of a social media platform. In Game-2, each undirected graph G ( V , E ) is defined ov er the set of nodes V and the set of edges E . In a given instance of the game, | V | is fixed for all targets and distractors. The number of edges varies across the graphs. W e add a self-loop to each node to include its own features in the node representation aggregated through message passing. W e use node degrees con verted to one-hot vectors as the initial node features. Baseline agents In each instance of the game, the speaker is parametrized by an encoder-decoder architecture and the listener is implemented as a classifier over the set consisting of the target and distractors. W e use generic Bag-of-W ords2Sequence and Sequence2Sequence (Seq2Seq) [Sutske ver et al., 2014] models ov er the node features as base- line speakers, and corresponding classifiers as listeners. Graph agents In order to handle graph input, the speaker and the listener are parametrized using a graph encoder . The speaker additionally uses a sequence decoder to generate a message. The graph encoder first generates node embeddings for each node, and then it uses them to construct an embed- ding of the entire graph. The sequence decoder takes the graph embedding as input and generates a message. A graph encoder consists of a node representation learning method and a graph pooling method. Node representations are com- puted for each node v i through neighborhood aggregation that follows the general formula h ( l + 1 ) v i = ReLU ∑ j ∈ N i h ( l ) v j W ( l ) , where l corresponds to the layer index, h v i are the features of the node v i , W refers to the weight matrix, and N i denotes the neighborhood of the node v i . W e compare a Graph Con- volutional Network (GCN) [Kipf and W elling, 2017]) with GraphSA GE [Hamilton et al., 2017], an extension of GCN which allo ws modifying the trainable aggregation function beyond a simple con volution. A graph embedding is obtained through a linear transformation of the node features. A graph embedding v ector in our graph-to-sequence implementation of the speaker corresponds to the conte xt vector in the Seq2Seq implementation. Similarly as in Seq2Seq architectures, the sequence decoder in graph-to-sequence outputs a probability distribution over the whole v ocabulary for a fixed message length which is then discretized to produce the message. T raining The speaker produces a softmax distrib ution ov er the v ocabu- lary V , where V refers to the finite set of all distinct words that can be used in the sequence generated by the speaker . Similar to [Sukhbaatar et al., 2016, Mordatch and Abbeel, 2018], we use the ‘straight through’ v ersion of Gumbel-Softmax [Jang et al., 2017, Maddison et al., 2017] during training to make the message discrete and propagate the gradients through the non-differentiable communication channel. At test time, we take the argmax over the whole v ocab ulary . In our graph referential games, the listener recei ves the discretized message m sent by the speaker along with the set of distractors K and the target graph d ∗ . The listener then outputs a softmax distribution over the | K | + 1 embeddings representing each graph. The speaker f θ and the listener g φ are parametrized using graph neural networks. W e formally Graph Seq BoW 70 80 90 100 96 . 3 95 94 90 . 5 89 88 . 9 Accuracy (%) T est OOD generalization (a) 9 distractors Graph Seq BoW 70 80 90 100 95 . 1 93 93 . 2 90 . 6 85 84 . 3 Accuracy (%) T est OOD generalization (b) 19 distractors Graph Seq BoW 70 80 90 100 95 . 1 90 . 1 87 . 7 88 . 6 82 . 3 75 . 5 Accuracy (%) T est OOD generalization (c) 49 distractors Figure 2: Standard test accuracy (T est) and out-of-domain (OOD) generalization in Game-2. Number of nodes, message length and vocab ulary size are equal to 25. W e report mean and standard deviation of three runs. define it as follows: m ( d ∗ ) = Gumbel-Softmax ( f θ ( d ∗ )) o ( m , { K , d ∗ } ) = g φ ( m , { K , d ∗ } ) W e used Deep Graph Library [W ang et al., 2019], EGG [Kharitonov et al., 2019] and PyT orch [Paszke et al., 2019] to build graph referential games. W e generate 40000 train samples, 5000 validation samples and 5000 test samples in each game. Experiments & Analysis W e in vestigate three questions: • What is the effect of data representation and the correspond- ing representation learning models on the compositionality of the emerged language ( T opographic similarity )? • What is the effect of structural biases on the ability to gener- alize to pre viously unseen combinations of familiar features ( Out-of-domain generalization )? • Can the listener identify the target if it receives a distorted message? ( Do agents rely on the communication chan- nel in solving the game? ). Qualitative analysis Sample input data Data repr esentation Bag-of-wor ds Sequence Graph A2 B4 C6 [1 4 4] [5 1 3] [7 1 4] A2 B4 C5 [1 0 0] [8 3 2] [4 7 2] A2 B2 C6 [6 4 1] [9 9 1] [9 4 1] A5 B4 C6 [8 8 9] [3 5 2] [6 6 1] T able 1: Qualitati ve samples of messages. In T able 1, we sho w sample messages generated in Game-1. Similarly as in Figure 1, we represent input properties using capital letters and property types using numbers. W e see that in the messages generated by a Graph2Seq model varying one input property (e.g. replacing C6 with C5) changes only one symbol in the message (the speaker replaces the w ord 1 with 2 in the utterance). In Seq2Seq, changing one symbol leads to a change of two symbols on average in the transmitted mes- sages. In the example, the vocab ulary size is 10 with message of fixed length 3 and the perceptual dimensions being [ 10 , 6 , 8 ] . When using lar ger input in Game-1, we experimented with the message length-to-v ocabulary size trade-off (details in the Hy- perparameters section) and we found that longer messages are less compositional. In Game-2 (Figure 2), the speaker learns to describe 25 properties in 25 words. W e found that for messages of the length 25, sample messages are difficult to interpret qualitativ ely , as all representations lead to languages that are order in v ariant with respect to words (see T able 1). T opographic similarity W e use topogr aphic similarity as a measure of language com- positionality , following a common practice in the domain of referential games [Lazaridou et al., 2018, Li and Bowling, 2019]. W e compute a negati v e Spearman correlation between all the possible pairs of target objects and the corresponding pairs of emerged messages. W e use cosine similarity in the input space and Lev enshtein distance in the message space. For graph representations we concatenate the node features in the same order as in sequences and bags-of-words for a fair comparison. Figure 3 shows topographic similarity (TS) of all three data representations in Game-1. All representations lead to positi v e values of TS, which implies that there is a positive correla- tion between the input features and the messages emerging in the game. On av erage, graph representations lead to a more compositional language (measured by greater TS) than bag-of-words and sequence representations. This ef fect is observed for instances of Game-1 with different numbers of distractors (19, 29, 49). W e hypothesize that in more difficult communication scenarios (e.g., if the number of distractors in- creases), structured representations are needed for emergence of a compositional language. 19 29 49 0 . 08 0 . 10 0 . 12 0 . 14 0 . 16 0 . 18 Number of distractors T opographic similarity Graph Seq BoW Figure 3: T opographic similarity in Game-1 with perceptual dimensions [10, 6, 8, 9, 10], a message length of size 3, and a vocab ulary size of 50. W e report mean and standard deviation across fiv e random seeds. Out-of-domain generalization In Game-2, we compare sequences, bag-of-w ords and graph representations in terms of test accurac y (using a 60% / 20% / 20% train/v alid/test split) and compositional gener alization (OOD generalization). In ev aluating OOD generalization, the agent sees an unseen graph/sequence/bag-of-w ords with a new combination of seen features. Intuiti vely , the agents only learn a “red dotted circle”, “blue dotted square”,“yellow dashed star” during training, and at test time we check if they can correctly identify the target: “red dashed square”. Since both the target and distractors are new to the agents, both agents are tested for their ability to disentangle input properties. W e in vestigated test accuracy and OOD generalization for an increasing number of distractors (9, 19, 49). Accuracy of a random guess in these games is, respecti v ely , 10%, 5% and 2%. Consequently , the game becomes significantly more com- plex as the number of distractors increases. Figure 2 shows the effect of structural priors on test accuracy and composi- tional generalization. Graph representations consistently lead to a better generalization to new combinations of familiar features, and this ef fect increases with the complexity of the game. Since for each representation we use generic agents of a comparable expression po wer , we hypothesize that graph rep- resentations lead to a more compositional language, especially in more difficult communication scenarios. Do agents rely on the communication channel in solving the game? W e analyzed whether the communication channel is crucial in learning to recognize the target among distractors. Figure 4 shows the results of this analysis over the entire set of tar gets and messages de veloped by graph learning agents. W e show the results for messages in the form of { m 1 , m 2 , m 3 } (message length ml = 3 , m i corresponds to individual symbols in the message, i = 1 , 2 , 3 ) and vocabulary size vs = 10 . In each subplot, the title corresponds to the symbol m 1 in the original message dev eloped through playing the game. The dark bar corresponds to the number of correctly classified samples giv en the original message (also included in the subplot title, e.g. Symbol 0: 39.2%). W e generate the remaining results by replacing the first symbol m 1 in the messages with each of the remaining symbols from the vocab ulary . The rest of the message (symbols m 2 and m 3 ) remains fixed. W e observ e that in all emerged messages distorting 1 / 3 of the symbols leads to a decrease in test accuracy . In all cases, the highest test accuracy is dependent on the target encoding produced by the graph speaker through playing the game. Ablation studies on Graph Neural Networks GraphSA GE learns aggre gator functions that can induce the embedding of a ne w node gi ven its features and the neigbor - hood, without re-training on the entire graph. The GraphSA GE encoders are thus able to learn dynamic graphs. In this paper , we experiment with commonly used ‘mean’, ‘pool’ and ‘gcn’ aggregator types. P ooling methods: In order to compute the graph embedding, we experimented with the standard graph pooling methods: mean, sum and max functions. W e found that the sum pooling gav e a significant boost in performance, and thus we use sum pooling throughout the experiments presented in this paper . Encoder networks: W e also experimented with two popular graph neural netw orks to compute the graph encoding, namely GraphCon v and SAGECon v . W e did not find a significant difference in performance between the tw o models. Aggr egator types: Another axis of variation is the aggre- gator type used in GraphSA GE and we found that the effect of all types- ‘mean’, ‘pool’ and ‘gcn’ is the same across both games. Hyperparameters In this work, we studied generic architectures and the main axis of v ariation was the degree of structure in the input representation and the corresponding representation learning method. In the experiments reported in this paper, we used the a range of hyperparameters listed below (bold indicates the ones used for the charts abo ve) that were manually tuned using accuracy as the selection criterion: • Number of distractors: 1, 2, 4, 9, 19, 29, 49 • V ocab Size of the message: 10, 25, 50 , 100 • Max length of the message: 3 , 4, 5, 10, 25 • Number of layers in Graph NN: 1, 2 , 3 • Size of the hidden layer: 100, 200 • Size of the message embedding: 50 , 100 • Learning Rate: 0.01, 0.001 • Gumbel-Softmax temperature: 1.0 0 10 20 30 40 50 60 70 80 % Correct test samples Symbol 0 - 39.2% Symbol 1 - 66.7% Symbol 2 - 43.5% Symbol 3 - 64.5% Symbol 4 - 40.0% Symbol 5 - 25.6% Symbol 6 - 60.6% Symbol 7 - 30.8% Symbol 8 - 71.4% Symbol 9 - 64.5% Figure 4: Robustness of the communication protocol. W e use trained agents and emerged messages from Game-1 with perceptual dimensions [10, 6, 8], a message length of size 3, and a vocab ulary size of 10. Max Pooling Avg Pooling Sum Pooling 70 75 80 85 90 95 100 % Accuracy mean aggr pool aggr gcn aggr 90 91 92 93 94 % Accuracy SAGEConv GraphConv 85 90 95 % Accuracy Figure 5: Ablation studies on different parameters of Graph Neural Network. The y-axis represent the test accuracy . All the runs are av eraged across three different random seeds and standard error bars are shown. For more details, please refer to the codebase. W e used Nvidia V100 and T itan R TX GPUs for running our experiments. On av erage, the models were trained for 3-5 days depending on the # distractors and the type of data representation used with Graph2Sequence models taking the longest and Bag2Sequence models the shortest time. Conclusion and future w ork W e analyzed the ef fect of structural inductiv e biases (bags-of- words, sequences, graphs) on compositional generalization in referential games. W e found that graph representations induce a stronger compositional prior measured by topographic simi- larity and out-of-domain generalization. Graph agents learn messages that lead to the highest accuracy in solving the task. Giv en the adv ancements in using graphs in natural language processing [V aswani et al., 2017], a future direction could be to train graph speakers to generate sentences closer to natural language [Lowe et al., 2020]. References Jacob Andreas. Measuring compositionality in representa- tion learning. In International Confer ence on Learning Repr esenations , 2019. URL https://openreview . net/ forum?id=HJz05o0qK7 . Dzmitry Bahdanau, Shikhar Murty , Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. Systematic generalization: What is required and can it be learned? In International Confer ence on Learning Repr esenations , 2019. URL https://openreview . net/ forum?id=HkezXnA9YX . Marco Baroni. Linguistic generalization and compositionality in modern artificial neural networks. Philosophical T rans- actions of the Royal Society B: Biological Sciences , 375: 20190307, 02 2020. doi: 10 . 1098/rstb . 2019 . 0307. Peter W . Battaglia, Jessica B. Hamrick, V ictor Bapst, Alvaro Sanchez-Gonzalez, V in ´ ıcius Flores Zambaldi, Mateusz Ma- linowski, Andrea T acchetti, David Raposo, Adam Santoro, Ryan Faulkner , C ¸ aglar G ¨ ul c ¸ ehre, H. Francis Song, An- drew J. Ballard, Justin Gilmer , Geor ge E. Dahl, Ashish V aswani, K else y R. Allen, Charles Nash, V ictoria Langston, Chris Dyer , Nicolas Heess, Daan W ierstra, Pushmeet K ohli, Matthew Botvinick, Oriol V inyals, Y ujia Li, and Razvan Pascanu. Relational inductive biases, deep learning, and graph networks. CoRR , abs/1806.01261, 2018. URL http://arxiv . org/abs/1806 . 01261 . Jacob L. S. Bellmund, Peter G ¨ ardenfors, Edvard I. Moser, and Christian F . Doeller . Na vigating cognition: Spatial codes for human thinking. Science , 362(6415), 2018. ISSN 0036-8075. doi: 10 . 1126/science . aat6766. URL https://science . sciencemag . org/content/362/ 6415/eaat6766 . Diane Bouchacourt and Marco Baroni. Ho w agents see things: On visual representations in an emergent language game. arXiv:1808.10696 [cs] , August 2018. URL http: //arxiv . org/abs/1808 . 10696 . arXiv: 1808.10696. Kyungh yun Cho, Bart v an Merri ¨ enboer , Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Y oshua Bengio. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Pr o- ceedings of the 2014 Confer ence on Empirical Methods in Natural Language Pr ocessing (EMNLP) , pages 1724– 1734, Doha, Qatar , October 2014. Association for Com- putational Linguistics. doi: 10 . 3115/v1/D14- 1179. URL https://www . aclweb . org/anthology/D14- 1179 . Katrina Evtimov a, Andrew Drozdov , Douwe Kiela, and Kyungh yun Cho. Emergent communication in a multi- modal, multi-step referential game. In ICLR , 2018. Shangmin Guo, Y i Ren, Agnieszka Słowik, and K ory Mathe w- son. Inductive bias and language expressivity in emer gent communication. arXiv preprint , 2020. Abhinav Gupta, Agnieszka Słowik, William L Hamilton, Mateja Jamnik, Sean B Holden, and Christopher Pal. An- alyzing structural priors in multi-agent communication. 2020. W ill Hamilton, Zhitao Y ing, and Jure Leskov ec. In- ductiv e representation learning on large graphs. In I. Guyon, U. V . Luxburg, S. Bengio, H. W allach, R. Fer- gus, S. V ishwanathan, and R. Garnett, editors, NIPS , pages 1024–1034. Curran Associates, Inc., 2017. URL http://papers . nips . cc/paper/6703- inductive- representation- learning- on- large- graphs . pdf . Eric Jang, Shixiang Gu, and Ben Poole. Categorical Repa- rameterization with Gumbel-Softmax. In International Confer ence on Learning Represenations , 2017. URL https://openreview . net/forum?id=rkE3y85ee . Eugene Kharitonov , Rahma Chaabouni, Diane Bouchacourt, and Marco Baroni. EGG: a toolkit for research on emer- gence of lanGuage in games. In Pr oceedings of the 2019 Confer ence on Empirical Methods in Natural Language Pr ocessing and the 9th International Joint Conference on Natural Language Pr ocessing (EMNLP-IJCNLP) , pages 55– 60, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10 . 18653/v1/D19- 3010. URL https://www . aclweb . org/anthology/D19- 3010 . Thomas N. Kipf and Max W elling. Semi-supervised clas- sification with graph con volutional networks. In Interna- tional Confer ence on Learning Repr esenations , 2017. URL https://openreview . net/forum?id=SJU4ayYgl . Satwik Kottur , Jos ´ e Moura, Stefan Lee, and Dhruv Ba- tra. Natural language does not emerge ‘naturally’ in multi-agent dialog. In Proceedings of the 2017 Confer- ence on Empirical Methods in Natural Langua ge Pro- cessing (EMNLP) , pages 2962–2967, Copenhagen, Den- mark, September 2017. Association for Computational Linguistics. doi: 10 . 18653/v1/D17- 1321. URL https: //www . aclweb . org/anthology/D17- 1321 . Brenden M. Lake, T omer D. Ullman, Joshua B. T enenbaum, and Samuel J. Gershman. Building machines that learn and think like people. Behavioral and Brain Sciences , 40:e253, 2017. doi: 10 . 1017/S0140525X16001837. Angeliki Lazaridou, Karl Moritz Hermann, Karl Tuyls, and Stephen Clark. Emergence of linguistic communication from referential games with symbolic and pixel input. In ICLR , 2018. Fushan Li and Michael Bowling. Ease-of-teaching and language structure from emergent communication. In H. W allach, H. Larochelle, A. Beygelzimer , F . d Alch ´ e-Buc, E. Fox, and R. Garnett, editors, Advances in Neur al Infor- mation Pr ocessing Systems , pages 15825–15835. Curran Associates, Inc., 2019. URL http://papers . nips . cc/ paper/9714- ease- of- teaching- and- language- structure- from- emergent- communication . pdf . Ryan Lowe, Abhinav Gupta, Jakob Foerster , Douwe Kiela, and Joelle Pineau. On the interaction between supervi- sion and self-play in emergent communication. In Interna- tional Confer ence on Learning Repr esenations , 2020. URL https://openreview . net/forum?id=rJxGLlBtwH . Chris J. Maddison, Andriy Mnih, and Y ee Whye T eh. The Concrete Distribution: A Continuous Relaxation of Discrete Random V ariables. In International Confer- ence on Learning Repr esenations , 2017. URL https: //openreview . net/forum?id=S1jE5L5gl . Igor Mordatch and Pieter Abbeel. Emergence of grounded compositional language in multi-agent popu- lations. In AAAI Confer ence on Artificial Intelligence , 2018. URL https://aaai . org/ocs/index . php/AAAI/ AAAI18/paper/view/17007 . Adam Paszke, Sam Gross, Francisco Massa, et al. Pytorch: An imperative style, high-performance deep learning library . In H. W allach, H. Larochelle, A. Beygelzimer , F . d’Alch ´ e Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Pr ocessing Systems , pages 8024–8035. Curran Associates, Inc., 2019. URL http://papers . nips . cc/ paper/9015- pytorch- an- imperative- style- high- performance- deep- learning- library . pdf . K oustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and W illiam L. Hamilton. CLUTRR: A diagnostic bench- mark for inductiv e reasoning from text. In Proceedings of the 2019 Confer ence on Empirical Methods in Natu- ral Language Pr ocessing and the 9th International J oint Confer ence on Natural Languag e Pr ocessing (EMNLP- IJCNLP) , pages 4506–4515, Hong Kong, China, Novem- ber 2019. Association for Computational Linguistics. doi: 10 . 18653/v1/D19- 1458. URL https://www . aclweb . org/ anthology/D19- 1458 . Agnieszka Słowik, Abhinav Gupta, William L Hamilton, Mateja Jamnik, and Sean B Holden. T o wards graph repre- sentation learning in emergent communication. 2020. Kenn y Smith, Simon Kirby , and Henry Brighton. Iterated learning: A framework for the emer gence of language. Artif. Life , 9(4):371–386, September 2003. ISSN 1064- 5462. doi: 10 . 1162/106454603322694825. URL http: //dx . doi . org/10 . 1162/106454603322694825 . Sainbayar Sukhbaatar, Arthur Szlam, and Rob Fergus. Learning multiagent communication with backpropagation. In D. D. Lee, M. Sugiyama, U. V . Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Pr ocessing Systems , pages 2244–2252. Curran Associates, Inc., 2016. URL http://papers . nips . cc/paper/ 6398- learning- multiagent- communication- with- backpropagation . pdf . Ilya Sutsk ev er , Oriol V inyals, and Quoc V Le. Sequence to Se- quence Learning with Neural Networks. In Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q. W ein- berger , editors, Advances in Neural Information Pr ocessing Systems , pages 3104–3112. Curran Associates, Inc., 2014. URL http://papers . nips . cc/paper/5346- sequence- to- sequence- learning- with- neural- networks . pdf . Ashish V aswani, Noam Shazeer, Niki Parmar , et al. At- tention is all you need. In I. Guyon, U. V . Luxbur g, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, editors, Advances in Neural Information Pro- cessing Systems , pages 5998–6008. Curran Associates, Inc., 2017. URL http://papers . nips . cc/paper/7181- attention- is- all- you- need . pdf . Minjie W ang, Lingfan Y u, Da Zheng, et al. Deep graph library: T o wards ef ficient and scalable deep learning on graphs. In- ternational Confer ence on Learning Repr esenations W ork- shop on Representation Learning on Gr aphs and Manifolds , 2019. URL https://arxiv . org/abs/1909 . 01315 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment