Q-SpiNN: A Framework for Quantizing Spiking Neural Networks
💡 Research Summary
Q‑SpiNN is a comprehensive quantization framework designed to dramatically reduce the memory footprint of spiking neural networks (SNNs) while keeping accuracy loss to a minimum. Existing works on SNN quantization have focused almost exclusively on reducing the precision of synaptic weights, using either post‑training quantization (PTQ) or in‑training quantization (ITQ) as a single scheme. They ignore other substantial memory consumers in SNNs, such as neuron membrane potentials and threshold values, and they do not explore the combinatorial space of quantization schemes, bit‑widths, and rounding methods. Consequently, the memory savings achievable under a given accuracy constraint are limited, restricting the deployment of SNNs on resource‑constrained edge devices.
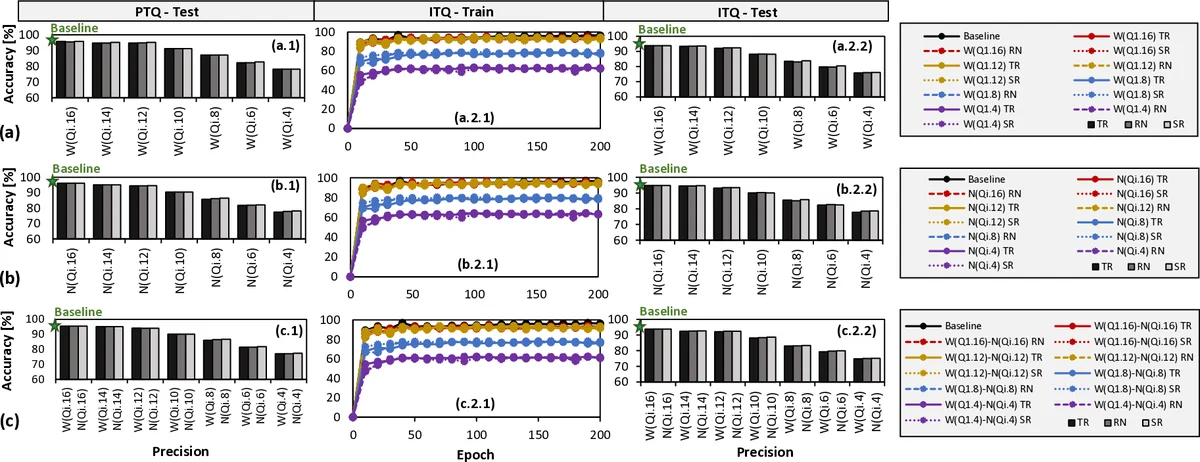
Q‑SpiNN addresses these gaps through three key mechanisms. First, it quantizes different SNN parameters (weights, membrane potentials, thresholds, etc.) based on their individual impact on classification accuracy. By experimentally sweeping bit‑widths for each parameter, the authors build a “precision‑importance map” that tells, for example, that weights can tolerate a very low fixed‑point format (e.g., Q1.4) while membrane potentials require higher precision (e.g., Q11.16). Second, it explores a rich design space that combines both PTQ and ITQ, multiple precision levels, and three rounding schemes—truncation (TR), rounding‑to‑nearest (RN), and stochastic rounding (SR). For each combination, the framework evaluates whether the resulting model meets a user‑specified target accuracy; those that do become “solution candidates.” Third, it introduces a multi‑objective reward function that quantifies the trade‑off between memory reduction and accuracy degradation. The reward multiplies the memory‑saving ratio by a penalty term derived from the accuracy gap, effectively ranking candidates on a Pareto frontier. The candidate with the highest reward is automatically selected as the final quantized model.
The experimental evaluation covers two representative SNN architectures. The unsupervised model (U‑SNN) is a single‑layer fully‑connected network trained with spike‑timing‑dependent plasticity (STDP). The supervised model (S‑SNN) follows the DECOLLE paradigm, consisting of three convolutional layers and a fully‑connected read‑out layer, trained with surrogate gradients. Both networks are implemented in PyTorch and run on an Nvidia RTX 2080 Ti GPU as well as an embedded GPU platform.
Results for the unsupervised network on the MNIST benchmark show that quantizing weights to Q1.16 and all neuron parameters to Q11.16 reduces the memory requirement by roughly 4× while keeping the classification accuracy within 1 % of the full‑precision baseline. For the supervised network on the DVS‑Gesture dataset, a configuration of Q1.8 for weights and Q11.8 for neuron states yields a 2× memory reduction with accuracy loss bounded by 2 %. Among the rounding schemes, stochastic rounding consistently yields the smallest accuracy degradation, likely because its probabilistic nature mitigates systematic quantization bias.
Beyond raw memory savings, the authors argue that fewer memory accesses translate directly into lower energy consumption, given that memory operations dominate SNN power budgets (≈50‑75 % of total energy). By providing a systematic way to explore the quantization space and automatically select a Pareto‑optimal model, Q‑SpiNN reduces the engineering effort required to tailor SNNs for edge deployment.
Future work suggested includes deploying the quantized models on actual low‑power IoT hardware (e.g., ARM Cortex‑M microcontrollers or neuromorphic chips) to measure real energy and latency gains, combining quantization with pruning or sparsity techniques for even greater compression, and extending the sensitivity analysis to event‑based data streams and more complex loss functions.
In summary, Q‑SpiNN offers a novel, automated pipeline that (1) quantizes all significant SNN parameters according to their accuracy sensitivity, (2) exhaustively searches across PTQ/ITQ, bit‑widths, and rounding methods, and (3) selects the model that maximizes a memory‑accuracy reward. The framework achieves up to 4× memory reduction for unsupervised SNNs and 2× for supervised SNNs, with only 1‑2 % accuracy loss, thereby paving the way for practical SNN deployment on memory‑constrained edge devices.
Comments & Academic Discussion
Loading comments...
Leave a Comment