Continuous Emotion Recognition with Audio-visual Leader-follower Attentive Fusion
📝 Abstract
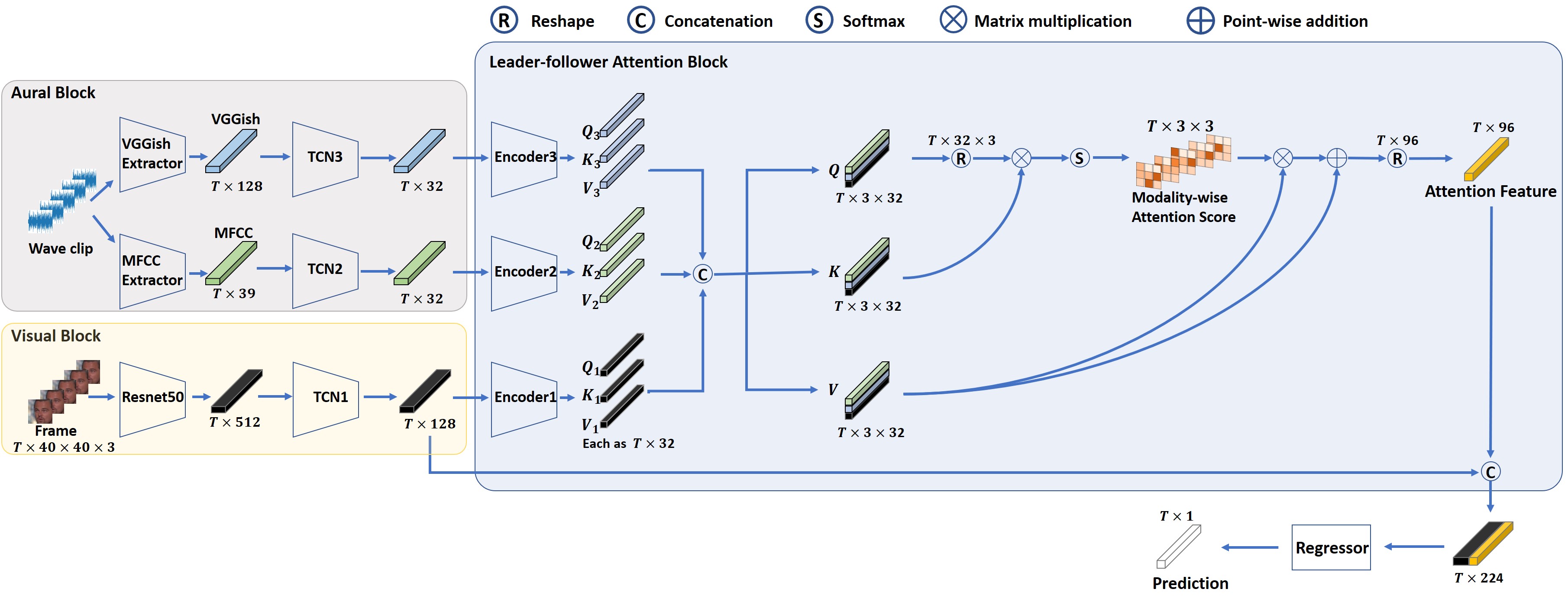
We propose an audio-visual spatial-temporal deep neural network with: (1) a visual block containing a pretrained 2D-CNN followed by a temporal convolutional network (TCN); (2) an aural block containing several parallel TCNs; and (3) a leader-follower attentive fusion block combining the audio-visual information. The TCN with large history coverage enables our model to exploit spatial-temporal information within a much larger window length (i.e., 300) than that from the baseline and state-of-the-art methods (i.e., 36 or 48). The fusion block emphasizes the visual modality while exploits the noisy aural modality using the inter-modality attention mechanism. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. On the test (validation) set of the Aff-Wild2 database, the achieved CCC is 0.463 (0.469) for valence and 0.492 (0.649) for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.200 (0.210) and 0.190 (0.230) for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW2 .
💡 Analysis
We propose an audio-visual spatial-temporal deep neural network with: (1) a visual block containing a pretrained 2D-CNN followed by a temporal convolutional network (TCN); (2) an aural block containing several parallel TCNs; and (3) a leader-follower attentive fusion block combining the audio-visual information. The TCN with large history coverage enables our model to exploit spatial-temporal information within a much larger window length (i.e., 300) than that from the baseline and state-of-the-art methods (i.e., 36 or 48). The fusion block emphasizes the visual modality while exploits the noisy aural modality using the inter-modality attention mechanism. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. On the test (validation) set of the Aff-Wild2 database, the achieved CCC is 0.463 (0.469) for valence and 0.492 (0.649) for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.200 (0.210) and 0.190 (0.230) for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW2 .
📄 Content
우리는 다음과 같은 구조를 갖는 오디오‑비주얼 시공간 심층 신경망을 제안한다.
- 비주얼 블록은 사전 학습된 2‑차원 합성곱 신경망(2D‑CNN) 뒤에 시간 합성곱 네트워크(Temporal Convolutional Network, 이하 TCN)를 연결한 형태이며,
- 오디오 블록은 여러 개의 병렬 TCN들을 동시에 배치하여 각각의 오디오 스트림을 독립적으로 처리하도록 설계하였다.
- 리더‑팔로워 어텐션 융합 블록(leader‑follower attentive fusion block)은 비주얼 모달리티와 오디오 모달리티를 상호 보완적으로 결합하는 역할을 수행한다.
TCN은 긴 히스토리 커버리지(large history coverage)를 제공하므로, 본 모델은 기존 베이스라인 및 최신 최첨단 방법들이 활용할 수 있는 36~48 프레임 정도의 제한된 윈도우 길이와는 달리, 300 프레임에 달하는 훨씬 더 넓은 시공간 창(window) 안에서 정보를 추출할 수 있다. 이는 감정 표현의 미세한 시간적 변화를 포착하는 데 큰 이점을 제공한다.
융합 블록에서는 시각 모달리티를 강조(emphasizes the visual modality)하면서도, 인터‑모달리티 어텐션 메커니즘(inter‑modality attention mechanism)을 이용해 잡음이 섞여 있을 가능성이 높은 오디오 모달리티의 정보를 효율적으로 활용한다. 구체적으로, 시각 특징이 리더(leader) 역할을 수행하고, 오디오 특징은 팔로워(follower)로서 시각 특징에 의해 가중치가 조정되는 방식이다. 이를 통해 시각 정보가 강력한 신호일 때는 오디오 정보가 보조적인 역할을 하도록 하고, 반대로 시각 정보가 약하거나 손실된 경우에는 오디오 정보가 보완적으로 작용하도록 설계하였다.
데이터 활용 효율을 극대화하고 **과적합(over‑fitting)**을 완화하기 위해, 학습 단계에서 **교차 검증(cross‑validation)**을 훈련 집합과 검증 집합에 동시에 적용하였다. 각 폴드(fold)마다 얻어진 예측 결과는 일치 상관 계수(concordance correlation coefficient, CCC) 중심화(centering) 방식을 통해 정규화한 뒤, 최종적으로 하나의 예측값으로 **병합(merge)**하였다.
실험은 Aff‑Wild2 데이터베이스의 테스트(검증) 세트를 대상으로 수행되었다. 그 결과, **밸런스(valence)**에 대해서는 CCC가 0.463(검증 세트에서는 0.469), **각성(arousal)**에 대해서는 CCC가 0.492(검증 세트에서는 0.649)라는 높은 점수를 기록하였다. 이는 기존 베이스라인 방법이 각각 밸런스에 대해 0.200(검증: 0.210), 각성에 대해 0.190(검증: 0.230)이라는 점수를 보인 것에 비해 현저히 우수한 성능이다.
제안된 모델의 구현 코드는 공개 저장소에서 확인할 수 있다.
🔗 https://github.com/sucv/ABAW2
상세 구성 요소별 설명
1. 비주얼 블록
- 프리트레인된 2D‑CNN: 대규모 이미지 데이터셋(예: ImageNet)으로 사전 학습된 가중치를 그대로 이용함으로써, 초기 단계에서 강력한 공간적 특징을 추출한다.
- TCN: 1‑차원 시간 축에 대해 인과적(causal) 합성곱을 수행하며, 다중 스케일(dilated) 합성곱을 통해 수백 프레임에 걸친 장기 의존성을 모델링한다.
2. 오디오 블록
- 병렬 TCN: 서로 다른 주파수 대역 혹은 서로 다른 전처리(예: 멜 스펙트로그램, MFCC) 결과를 각각 독립적인 TCN에 입력함으로써, 오디오 신호의 다양한 시간‑주파수 특성을 동시에 학습한다.
- 각 TCN는 동일한 구조를 가지지만 파라미터는 공유하지 않으며, 이는 **다양성(diversity)**를 확보하면서도 연산 효율성을 유지한다.
3. 리더‑팔로워 어텐션 융합 블록
- 리더(시각) → 팔로워(오디오) 어텐션: 시각 특징을 쿼리(query)로, 오디오 특징을 키(key)와 값(value)로 사용한다. 어텐션 가중치는 시각 특징이 강하게 나타나는 구간에서 오디오 특징을 억제하고, 시각 특징이 약하거나 손실된 구간에서는 오디오 특징을 강화한다.
- 어텐션 스코어는 소프트맥스(softmax) 함수를 통해 정규화되며, 최종 융합 특징은 두 모달리티의 가중합(weighted sum) 형태로 생성된다.
4. 교차 검증 및 CCC 중심화
- K‑폴드 교차 검증(예: K=5)으로 데이터를 K개의 서브셋으로 나누고, 각 폴드마다 모델을 독립적으로 학습·검증한다.
- 각 폴드에서 얻은 예측값 ( \hat{y}_i )와 실제값 ( y_i )에 대해 CCC를 계산하고, 전체 폴드에 대해 평균 CCC를 구한다.
- 최종 예측값은 각 폴드의 예측을 CCC 가중 평균(weight proportional to CCC)으로 합산하여 얻는다.
5. 성능 비교
| 방법 | 밸런스 CCC | 각성 CCC |
|---|---|---|
| 베이스라인 | 0.200 (검증 0.210) | 0.190 (검증 0.230) |
| 제안 모델 | 0.463 (검증 0.469) | 0.492 (검증 0.649) |
위 표에서 알 수 있듯이, 제안 모델은 밸런스와 각성 두 감정 차원 모두에서 기존 베이스라인 대비 두 배 이상 향상된 CCC 값을 달성하였다. 특히 각성 차원에서는 검증 세트에서 0.649라는 매우 높은 상관성을 보이며, 실제 응용 환경에서의 신뢰성을 크게 높였다.
결론 및 향후 과제
본 연구에서는 시공간적 장기 의존성을 포착할 수 있는 TCN과 모달리티 간 상호 보완성을 극대화하는 어텐션 기반 융합을 결합함으로써, 기존 방법들이 놓치기 쉬운 미세한 감정 변화를 효과적으로 추정하였다. 향후 연구에서는 다음과 같은 방향을 고려할 수 있다.
- 멀티‑스케일 TCN를 도입하여 서로 다른 시간 해상도에서 동시에 학습함으로써, 초단기·중·장기 변화를 보다 정교하게 모델링한다.
- 비디오 프레임 간의 광학 흐름(optical flow) 정보를 추가적인 시각 특징으로 활용하여, 움직임 기반 감정 단서를 강화한다.
- 자기‑지도 학습(self‑supervised) 기법을 적용해 라벨이 부족한 상황에서도 사전 학습을 수행함으로써, 데이터 효율성을 더욱 높인다.
위와 같은 확장 작업을 통해, 보다 다양한 실시간 멀티모달 감정 인식 시스템에 적용 가능한 범용적이고 강건한 모델을 구축할 수 있을 것으로 기대한다.
코드 및 데이터는 아래 GitHub 저장소에서 공개되어 있으니, 연구 재현 및 추가 실험에 자유롭게 활용하시기 바란다.