Converting Cascade-Correlation Neural Nets into Probabilistic Generative Models
Humans are not only adept in recognizing what class an input instance belongs to (i.e., classification task), but perhaps more remarkably, they can imagine (i.e., generate) plausible instances of a desired class with ease, when prompted. Inspired by this, we propose a framework which allows transforming Cascade-Correlation Neural Networks (CCNNs) into probabilistic generative models, thereby enabling CCNNs to generate samples from a category of interest. CCNNs are a well-known class of deterministic, discriminative NNs, which autonomously construct their topology, and have been successful in giving accounts for a variety of psychological phenomena. Our proposed framework is based on a Markov Chain Monte Carlo (MCMC) method, called the Metropolis-adjusted Langevin algorithm, which capitalizes on the gradient information of the target distribution to direct its explorations towards regions of high probability, thereby achieving good mixing properties. Through extensive simulations, we demonstrate the efficacy of our proposed framework.
💡 Research Summary
The paper introduces a novel framework that converts a deterministic, discriminative Cascade‑Correlation Neural Network (CCNN) into a probabilistic generative model capable of sampling from a desired class. Human cognition can not only classify but also imagine novel instances of a concept; the authors aim to endow CCNNs with a similar generative capacity.
CCNNs are a classic self‑organizing architecture that starts with only input and output layers and incrementally adds hidden units, each trained to maximize correlation with the current residual error. This autonomous topology construction mirrors developmental processes and has been used to model various cognitive phenomena. However, because CCNNs are purely feed‑forward classifiers, they lack a mechanism to produce new inputs that would be classified into a particular category.
To bridge this gap, the authors adopt the Metropolis‑adjusted Langevin (MAL) algorithm, a Markov Chain Monte Carlo (MCMC) technique that leverages gradient information of the target distribution to propose new states. For a current state X(i), MAL draws a proposal X* from a Gaussian centered at X(i) + τ∇log π(X(i)) with covariance 2τI, where τ is a step‑size parameter. The proposal is then accepted or rejected using the standard Metropolis–Hastings acceptance probability, guaranteeing convergence to the target distribution π.
The key contribution lies in defining π in terms of the trained CCNN’s output. Let f(X; W*) denote the input‑output mapping after training, and let L_j be a target output vector that encodes the desired class j (e.g., +0.5 for the j‑th output unit and –0.5 for all others). The authors set
π̃(X) ∝ exp(–β‖L_j – f(X; W*)‖²)
where β>0 controls how sharply deviations from the desired label are penalized. This formulation treats the squared prediction error as an energy function, yielding a Gibbs‑type distribution over inputs. Importantly, the normalizing constant Z is never required because MAL’s acceptance ratio cancels it out.
The gradient needed for MAL is
∇log π̃(X) = –2β (f(X; W*) – L_j) · ∇_X f(X; W*)
which can be computed efficiently by back‑propagation through the fixed network parameters W*. For low‑dimensional inputs, a finite‑difference approximation is also possible, but back‑propagation is preferred for scalability.
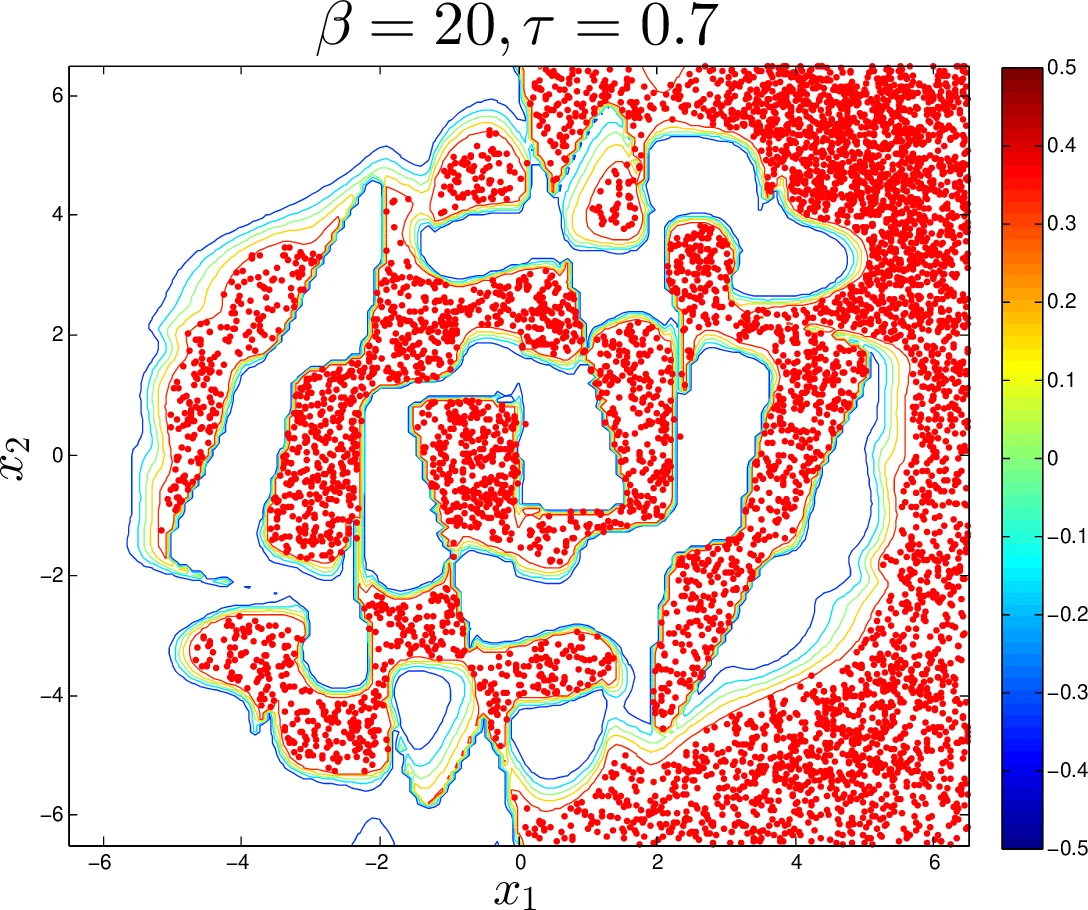
The authors validate the framework on a continuous XOR classification task. The dataset consists of 100 points uniformly sampled in the unit square, labeled +0.5 (positive) or –0.5 (negative). After training, a CCNN with six hidden layers is obtained, producing a highly non‑linear decision surface. Using MAL, the authors generate samples that the network would classify as positive. They explore three settings of τ (step size) and β (penalty):
- τ = 5×10⁻⁵, β = 1 – proposals are tiny, leading to slow exploration and low coverage of the target region.
- τ = 5×10⁻³, β = 1 – exploration is adequate, but the weak penalty allows many proposals to drift into low‑probability zones, yielding an acceptance rate of 75 % and only 57 % of samples in the desired region.
- τ = 5×10⁻³, β = 10 – a balanced step size with a strong penalty produces rapid mixing while strongly discouraging moves away from the target class. In this configuration, 99.55 % of 2000 generated points fall inside the positive region, and the acceptance rate remains high.
Visualization of the learned mapping and the generated points confirms that the framework successfully steers the sampler toward high‑probability input zones corresponding to the chosen class.
Beyond the empirical demonstration, the paper highlights several broader implications. By converting a CCNN into a generative model, researchers gain a tool to probe “what the network knows” at any training stage, especially in high‑dimensional spaces where inspection is otherwise difficult. The use of MAL also connects to prior work suggesting that Langevin‑type dynamics could be implemented in cortical circuits, offering a potential neuro‑computational interpretation of the method.
Limitations are acknowledged: the experiments focus on low‑dimensional, continuous inputs; extending the approach to high‑dimensional images, text, or other structured data will require careful design of the proposal covariance and efficient gradient computation. Future work may explore multi‑class extensions, adaptive τ schedules, and integration with modern deep generative architectures.
In summary, the paper provides a clear, mathematically grounded procedure to endow classic self‑organizing CCNNs with probabilistic generative capabilities, demonstrating its feasibility on a benchmark task and opening avenues for both cognitive modeling and practical generative applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment