The Audio Auditor: User-Level Membership Inference in Internet of Things Voice Services
With the rapid development of deep learning techniques, the popularity of voice services implemented on various Internet of Things (IoT) devices is ever increasing. In this paper, we examine user-level membership inference in the problem space of voi…
Authors: Yuantian Miao, Minhui Xue, Chao Chen
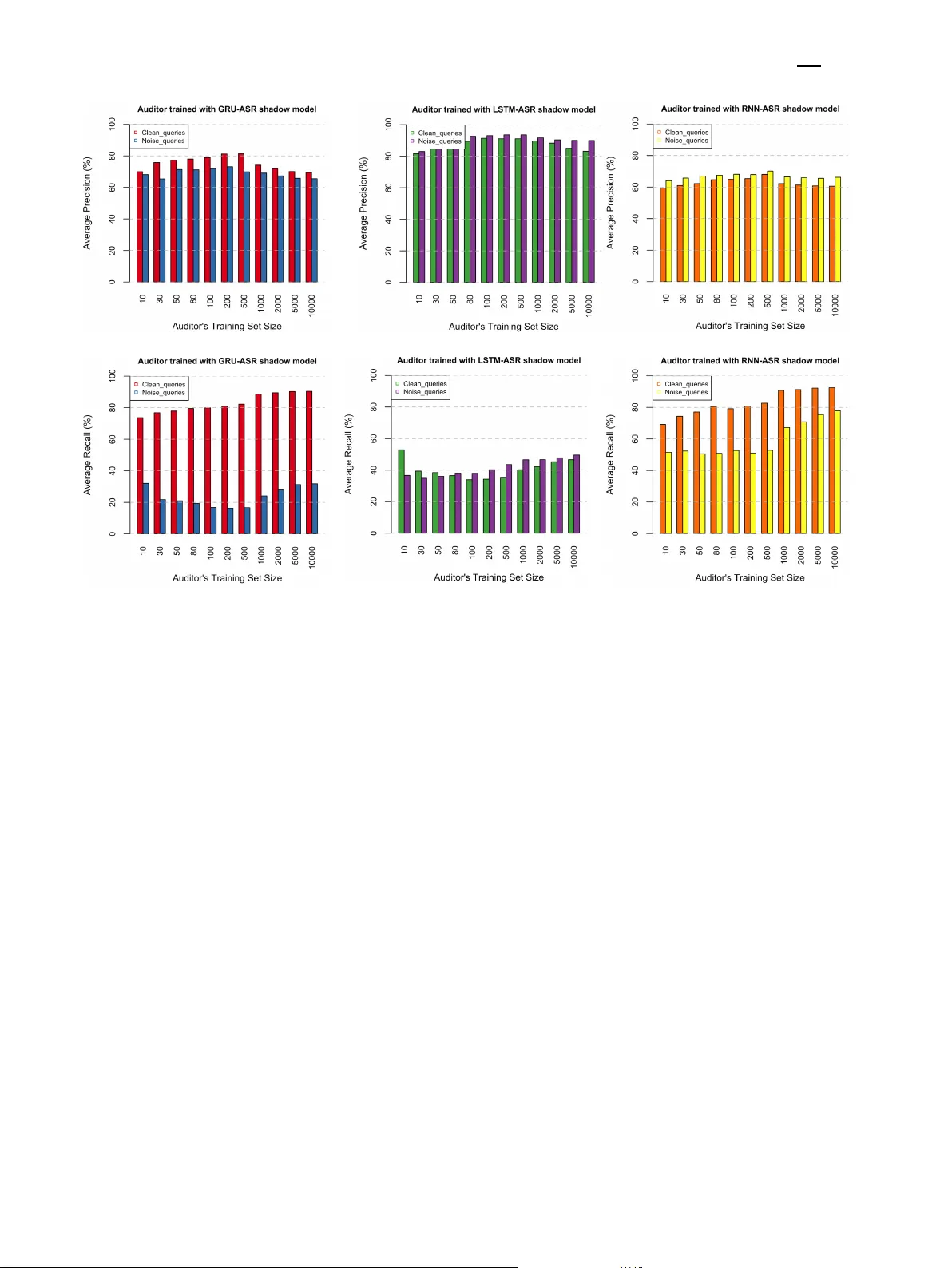
Proceedings on Privacy Enhancing T echnologies 2021 Y uantian Miao, Minhui Xue, Chao Chen*, Lei P an, Jun Zhang, Benjamin Zi Hao Zhao, Dali Kaafa r, and Y ang Xiang The A udio A udito r: User-Level Memb ership Inference in Internet of Things V oice Services Abstract: With the rapid dev elopment of deep learning tec hniques, the popularity of voice services implemen ted on v arious In ternet of Things (IoT) devices is ever in- creasing. In this pap er, we examine user-level member- ship inference in the problem space of v oice services, b y designing an audio auditor to verify whether a sp ecific user had un willingly contributed audio used to train an automatic speech recognition (ASR) model under strict blac k-b ox access. With user representation of the in- put audio data and their corresp onding translated text, our trained auditor is effectiv e in user-level audit. W e also observe that the auditor trained on specific data can be generalized w ell regardless of the ASR model arc hitecture. W e v alidate the auditor on ASR mo dels trained with LSTM, RNNs, and GRU algorithms on t wo state-of-the-art pip elines, the hybrid ASR system and the end-to-end ASR system. Finally , we conduct a real-w orld trial of our auditor on iPhone Siri, achiev- ing an o verall accuracy exceeding 80%. W e hop e the metho dology developed in this pap er and findings can inform priv acy adv o cates to ov erhaul IoT priv acy . Keyw ords: Mem b ership Inference A ttack, ASR, Ma- c hine Learning 1 Intro duction A utomatic sp eec h recognition (ASR) systems are widely adopted on In ternet of Things (IoT) devices [16, 20]. In Y uantian Miao: Swin burne Univ ersity of T echnology , A us- tralia Minh ui Xue: The Universit y of Adelaide, Australia *Corresp onding Author: Chao Chen: James Cook Uni- versit y , Australia. Email: chao.chen@jcu.edu.au. Lei Pan: Deakin Univ ersity , A ustralia Jun Zhang: Swin burne Univ ersity of T echnology , Australia Benjamin Zi Hao Zhao: The Univ ersity of New South W ales and CSIRO-Data61, Australia Dali Kaafar: Macquarie Universit y and CSIRO-Data61, Aus- tralia Y ang Xiang: Swin burne Univ ersity of T echnology , A ustralia the IoT v oice services space, comp etition in the smart sp eak er mark et is heating up b etw een gian ts like Ap- ple, Microsoft, and Amazon [24]. Ho wev er parallel to the release of new pro ducts, consumers are growing in- creasingly aw are and concerned about their priv acy , par- ticularly ab out unauthorized access to user’s audio in these ASR systems. Of late, priv acy p olicies and reg- ulations, such as the General Data Protection Regula- tions (GDPR) [7], the Children’s Online Priv acy Protec- tion Act (COPP A) [19], and the California Consumer Priv acy Act (CCP A) [3], hav e been enforced to reg- ulate p ersonal data pro cessing. Specifically , the Right to b e F orgotten [48] la w allows customers to prev ent third-part y v oice services from con tinuously using their data [2]. How ever, the murky b oundary b etw een priv acy and security can thw art IoT’s trustw orthiness [13, 34] and many IoT devices may attempt to sniff and ana- lyze the audio captured in real-time without a user’s consen t [33]. Most recen tly , on W eChat – a h ugely p op- ular messaging platform within China and W orldwide – a scammer camouflaged their voice to sound like an acquain tance b y spo ofing his or her voice [4]. Addition- ally , in 2019, The Guardian reported a threat regarding the user recordings leakage via Apple Siri [11]. A uditing if an ASR service provider adheres to its priv acy state- men t can help users to protect their data priv acy . It motiv ates us to dev elop tec hniques that enable auditing the use of customers’ audio data in ASR mo dels. Recen tly , researchers hav e sho wn that re c or d-level memb ership infer enc e [10, 32, 39] may exp ose informa- tion ab out the mo del’s training data even with only blac k-b ox access. T o moun t mem b ership inference at- tac ks, Shokri et al. [39] integrate a plethora of shadow mo dels to constitute the attac k model to infer mem- b ership, while Salem et al. [32] further relax this pro- cess and resort to the target mo del’s confidence scores alone. Ho wev er, instead of inferring record-level infor- mation, w e seek to infer user-lev el information to v erify whether a user has any audios within the training set. Therefore, we define user-lev el mem b ership infer- ence as: querying with a user’s data, if this user has any data within tar get mo del’s tr aining set, even if the The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 2 query data ar e not memb ers of the tr aining set, this user is the user-level memb er of this tr aining set. Song and Shmatik ov [40] discuss the application of user-lev el mem b ership inference on text generativ e mod- els, exploiting several top ranked outputs of the model. Considering most ASR systems in the real w orld do not pro vide the confidence score, significan tly differing from text generativ e models lending confidence scores [40], this pap er targets user-level membership inference on ASR systems under strict black-b ox ac c ess , which w e de- fine as no knowledge about the mo del, with only knowl- edge of the mo del’s output excluding c onfidenc e sc or e and r ank information , i.e., only predicted label is kno wn. Unfortunately , user-lev el membership inference on ASR systems with strict black-box access is c halleng- ing. (i) Lac k of information ab out the target mo del is challenging [5]. As strict black-box inference has lit- tle knowledge ab out the target mo del’s performance, it is hard for shadow mo dels to mimic a target model. (ii) User-lev el inference requires a higher level of ro- bustness than record-lev el inference. Unlik e record-lev el, user-lev el inference needs to consider the speaker’s v oice c haracteristics. (iii) ASR systems are complicated due to their learning architectures [5], causing membership inference with shadow models to b e computationally re- source and time consuming. Finally , time-series audio data is significantly more complex than textual data, resulting in v aried feature patterns [6, 38]. In this pap er, we design and ev aluate our audio auditor to help users determine whether their audio records hav e been used to train an ASR mo del with- out their consent. W e inv estigate tw o t yp es of targeted ASR mo dels: a hybrid ASR system and an end-to-end ASR system. With an audio signal input, b oth of the mo dels transcribe speech into written text. The auditor audits the target mo del with an in tent via strict black- b o x access to infer user-level mem b ership. The auditor will b ehav e differen tly dep ending on whether audio is transcrib ed from within its training set or from other datasets. Thus, one can analyze the transcriptions and use the outputs to train a binary classifier as the auditor. As our primary fo cus is to infer user-level mem b ership, instead of using the rank lists of several top output re- sults, we only use one text output, the user’s speed, and the input audio’s true transcription while analyzing the transcription outputs (see details in Section 3). In summary , the main contributions of this pap er are as follows: 1. W e propose the use of user-level membership infer- ence for auditing the ASR model under strict blac k- b o x access. With access to the top predicted label only , our audio achiev es 78.81% accuracy . In com- parison, the b est accuracy for the user-lev el auditor in text generative mo dels with one top-rank ed out- put is 72.3% [40]. 2. Our auditor is effective in user-lev el audit. F or the user who has audios within the target mo del’s training set, the accuracy of our auditor query- ing with these recordings can achiev e more than 80%. In addition, only nine queries are needed for eac h user (regardless of their membership or non- mem b ership) to v erify their presence of recordings in the ASR mo del, at an accuracy of 75.38%. 3. Our strict black-box audit methodology is robust to v arious arc hitectures and pip elines of the ASR mo del. W e inv estigate the auditor by auditing the ASR mo del trained with LSTM, RNNs, and GR U algorithms. In addition, tw o state-of-the-art pip elines in building ASR mo dels are implemented for v alidation. The o verall accuracy of our audi- tor achiev es appro ximately 70% across v arious ASR mo dels on auxiliary and cross-domain datasets. 4. W e conduct a pro of-of-concept test of our auditor on iPhone Siri, under the strict black-box access, ac hieving an o verall accuracy in excess of 80%. This real-w orld trial lends evidence to the comprehensiv e syn thetic audit outcomes observed in this pap er. T o the best of our kno wledge, this is the first pap er to examine user-lev el membership inference in the prob- lem space of voice services. W e hop e the metho dology dev elop ed in this pap er and findings can inform priv acy adv o cates to o verhaul IoT priv acy . 2 Background In this section, w e ov erview the automatic sp eech recog- nition mo dels and membership inference attac ks. 2.1 The Automatic Sp eech Recognition Mo del There are tw o state-of-the-art pip elines used to build the automatic sp eech recognition (ASR) system, including the t ypical h ybrid ASR systems and end-to-end ASR systems [27]. T o test the robustness of our auditor, w e implement both op en-source hybrid and end-to-end The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 3 (a) A hyb rid ASR system. There are three main steps: (i) the prep ro- cessing step extracts features to rep resent the ra w audio data, (ii) the DNN training step trains the acoustic mo del and calculates the pseudo- posteriors, and (iii) the decoding step aims to map the p redicted symb ol combinations to texts and output the transcription results with the high- est sco re. (b) An end-to-end system. There a re four main components: (i) the en- coder transforms the input audio into a high-level rep resentation h n , (ii) the attention mechanism integrates the rep resentation h n with p revious decoder output q n − 1 and gain the context output c n , (iii) the deco der decodes the context output c n with p revious ground truth as q n , and (iv) the Softmax activation like CharDistribution p redicts q n auto-regressively and results in final transcription. Fig. 1. T w o state-of-the-a rt ASR systems ASR systems fo cusing on a sp eech-to-text task as the target mo dels. Hybrid ASR Systems are mainly DNN-HMM- based acoustic mo dels [46]. As shown in Fig. 1a, typ- ically , a hybrid ASR system is comp osed of a prepro- cessing step, a mo del training step, and a deco ding step [35]. During the preprocessing step, features are extracted from the input audio, while the corresp ond- ing text is processed as the audio’s label. The model training step trains a DNN mo del to create HMM class p osterior probabilities. The deco ding step maps these HMM state probabilities to a text sequence. In this w ork, the hybrid ASR system is built using the pytorc h- kaldi speech recognition toolkit [29]. Sp ecifically , fea- ture extraction transforms the audio frame in to the fre- quency domain, as Mel-F requency Cepstral Co efficients (MF CCs) features. F or an additional pro cessing step, feature-space Maxim um Likelihoo d Linear Regression (fMLLR) is used for sp eak er adaptation. Three p op- ular neural net w ork algorithms are used to build the acoustic mo del, including Long Short-T erm Memory (LSTM), Gated Recurrent Units (GR U), and Recurrent Neural Netw orks (RNNs). The deco der inv olv es a lan- guage mo del whic h provides a language probability to re-ev aluate the acoustic score. The final transcription output is the sequence of the most suited language with the highest score. End-to-End ASR Systems are atten tion-based enco der-deco der mo dels [14]. Unlike hybrid ASR sys- tems, the end-to-end system predicts sub-w ord se- quences whic h are conv erted directly as w ord sequences. As shown in Fig. 1b, the end-to-end system is a uni- fied neural netw ork modeling framework containing four comp onen ts: an enco der, an atten tion mec hanism, a de- co der, and a Softmax lay er. The enco der contains fea- ture extraction (i.e., VGG extractor) and a few neu- ral netw ork lay ers (i.e., BiLSTM lay ers), whic h enco de the input audio into high-lev el represen tations. The lo cation-a ware attention mec hanism integrates the rep- resen tation of this time frame with the previous decoder outputs. Then the atten tion mechanism can output the con text vector. The deco der can b e a single lay er neu- ral net work (i.e., an LSTM lay er), deco ding the current con text output with the ground truth of last time frame. Finally , the softmax activ ation, which can b e considered as “CharDistribution”, predicts several outputs and in- tegrates them in to a single sequence as the final tran- scription. 2.2 Memb ership Inference Attack The mem b ership inference attack is considered as a sig- nifican t priv acy threat for mac hine learning (ML) mod- els [22]. The attack aims to determine whether a specific data sample is within the target model’s training set or not. The attack is driven by the different b ehaviors of the target mo del when making predictions on samples within or out of its training set. V arious membership inference attac k metho ds ha ve b een recently prop osed. Shokri et al. [39] train shado w mo dels to constitute the attack model against a target ML mo del with black-box access. The shadow models mimic the target mo del’s prediction b ehavior. T o im- pro ve accuracy , Liu et al. [15] and Ha yes et al. [10] lev er- age Generative Adv ersarial Netw orks (GAN) to gener- ate shadow models with increasingly similar outputs to the target mo del. Salem et al. [32] relax the attack as- sumptions mentioned in the w ork [39], demonstrating that shado w mo dels are not necessary to launch the mem b ership inference attack. Instead, a threshold of the predicted confidence score can b e defined to sub- stitute the attack mo del. Intuitiv ely , a large confidence score indicates the sample as a mem b er of the train- ing set [41]. The attacks mentioned in the work ab ov e are all p erformed on the record lev el, while Song and Shmatik ov [40] study a user-lev el mem b ership inference attac k against text generative mo dels. Instead of us- ing the prediction lab el along with the confidence score, Song and Shmatiko v [40] utilize word’s rank list infor- The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 4 mation of sev eral top-ranked predictions as k ey features to generate the shadow mo del. Apart from the black- b o x access, F arokhi and Kaafar [8] mo del the record- lev el membership inference attack under the white-b ox access. Unlik e image recognition systems or text generative systems, ASR systems presen t additional c hallenges [5]. With strict black-box access, attacks using confidence scores cannot b e applied. With limited discriminativ e p o wer, features can only be extracted from the predicted transcription and its input audio to launch membership inference attacks, i.e., audio auditing in our pap er. 3 A uditing the ASR Mo dels In this section, we first formalize our objective for audit- ing ASR models. Secondly , we present how a user-level ASR auditor can b e constructed and used to audit the target ASR. Finally , w e sho w ho w w e implemen t the auditor. 3.1 Problem Statement W e define user-level memb ership infer enc e as querying a user’s data and trying to determine whether an y data within the target mo del’s training set belongs to this user. Even if the queried data is not members of the training set, but data b elonging to this user is members in the training set, then this user is regarded as the user- lev el member of this training set. Let ( x, y ) ∈ X × Y de- note an audio sample, where x presents the audio com- p onen t, and y is the actual text of x . Assume an ASR mo del is a function F : X → Y . F ( x ) is the mo del’s translated text. The smaller the difference b etw een F ( x ) and y , the b etter the ASR mo del performs. Let D rep- resen t a distribution of audio samples. Assume an audio set A is sampled from D of size N ( A ∼ D N ). Let U b e the speaker set of A of size M ( U ← A ). The ASR mo del trained with the dataset A is denoted as F A . Let A rep- resen t our auditor, and the user-lev el auditing pro cess can b e formalized as: – A speaker u has S = S m i =1 ( x i , y i ) , where u ← S . – Let Y 0 = S m i =1 y 0 i , when y 0 i = F A ( x i ) . – Let “ member ” = 0 and “ nonmember ” = 1 . – Set r = 0 if u ∈ U , or r = 1 if u / ∈ U . – The auditor successes if A ( u, S, Y 0 ) = r ; otherwise it fails. Our auditor, as an application of user-lev el mem- b ership inference, c hecks a sp eaker’s membership of an ASR mo del’s training set. This ASR model is considered as the target model. T o closely mirror the real w orld, we query the target model with strict blac k-b ox access. The mo del only outputs a p ossible text sequence as its tran- scription when submitting an audio sample to the tar- get mo del. This setting reflects the reality , as the auditor ma y not kno w this transcription’s posterior probabilities or other p ossible transcriptions. Additio nally , an y infor- mation ab out the target mo del is unknown, including the model’s parameters, algorithms used to build the mo del, and the mo del’s arc hitecture. T o ev aluate our auditor, we develop our target ASR mo del F tar using an audio set A tar with tw o popular pip elines — hybrid ASR mo del and end-to-end ASR mo del — to represent the ASR mo del in the real w orld. As describ ed in Sec- tion 2, the hybrid ASR mo del and the end-to-end ASR mo del translate the audio in different manners. Under the strict black-box access, the auditor only knows query audio records of a particular user u and its corresp ond- ing output transcription. The goal of the auditor is to build a binary classifier A audit to discriminate whether this user is the member of the user set in which their audio records hav e been used as target model’s training data ( u ∈ U tar , U tar ← A tar ). 3.2 Overview of the Prop osed Audio A udito r The nature of membership inference [39] is to learn the difference of a mo del fed with its actual training sam- ples and other samples. User-lev el membership infer- ence, lik e its record-level v ariant, requires higher robust- ness. Apart from the disparity of the target model’s p er- formance on record-lev el, our auditor needs to consider the speaker’s c haracteristics as w ell. Since the p osterior probabilities (or confidence scores) are not part of the outputs, shadow models are necessary to audit the ASR mo del. Fig. 2 depicts a workflo w of our audio auditor audit- ing an ASR mo del. Generally , there are tw o pro cesses, i.e., training and auditing. The former pro cess is to build a binary classifier as a user-level membership au- ditor A audit using a sup ervised learning algorithm. The latter uses this auditor to audit an ASR model F tar b y querying a few audios spoken b y one user u . In Sec- tion 4.4, w e show that only a small n umber of audios p er user can determine whether u ∈ U tar or u / ∈ U tar . The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 5 Fig. 2. Auditing an ASR mo del. (i) In the training p ro cess, w e sample n datasets from the auxiliary reference dataset D ref to build n ( n > 1 ) shado w models. Each shadow mo del dataset A shdi ∼ D N ref , i = 1 , . . . , n is split to a training set A train shdi and a testing set A test shdi . Then we query the shadow model with A test shdi and A train shdi and lab el their transcriptions as “ member ” o r “ nonmember ” . Then an audit mo del can b e trained with the outputs of shadow mo dels. (ii) In the auditing p ro cess, w e randomly sample a particula r speaker’s ( u ’s) audios A u ∼ D users to query our target ASR model. Feature vectors from outputs of the ta rget ASR mo del can b e passed to the audit model to determine whether u ∈ U tar ← A tar holds. F urthermore, a small num b er of users used to train the auditor is sufficient to provide a satisfying result. T raining Process. The primary task in the training pro cess is to build up shadow mo dels of high qualit y . Shado w mo dels, mimicking the target mo del’s b ehav- iors, try to infer the targeted ASR mo del’s decision b oundary . Due to strict black-box access, a go o d qual- it y shado w mo del p erforms with an approximate test- ing accuracy as the target mo del. W e randomly sample n datasets from the auxiliary reference dataset D ref as A shd 1 , . . . , A shdn to build n shadow models. Each shado w mo del’s audio dataset A shdi , i = 1 , . . . , n is split to a training set A train shdi and a testing set A test shdi . T o build up the ground truth for auditing, we query the shadow mo del with A train shdi and A test shdi . Assume a user’s audio set A u is sampled from users’ audio sets D users . A c- cording to the user-level membership inference defini- tion, the outputs from the audio A u ∈ A test shdi where its sp eak er u / ∈ U train shdi are lab eled as “ nonmember ” . Other- wise, the outputs translated from the audio A u ∈ A train shdi and from the audio A u ∈ A test shdi where its sp eak er u ∈ U train shdi are all lab eled as “ member ” . Herein, U train shdi ← A train shdi . T o simplify the exp eriment, for each shadow mo del, training samples are disjoint from testing sam- ples ( A train shdi ∩ A test shdi = ∅ ). Their user sets are disjoint as w ell ( U train shdi ∩ U test shdi = ∅ ). With some feature extraction (noted b elow), those lab eled records are gathered as the auditor mo del’s training set. F eature extraction is another essential task in the training process. Under the strict black-box access, fea- tures are extracted from the input audio, ground truth transcription, and the predicted transcription. As a user-lev el membership inferrer, our auditor needs to learn the information ab out the target mo del’s p erfor- mance and the speaker’s characteristic s. Comparing the ground truth transcription and the output transcrip- tion, the similarity score is the first feature to repre- sen t the ASR mo del’s p erformance. T o compute the tw o transcriptions’ similarity score, the GloV e model [26] is used to learn the vector space representation of these t wo transcriptions. Then the cosine similarit y distance is calculated as the tw o transcriptions’ similarity score. A dditionally , the input audio frame length and the sp eaking sp eed are selected as tw o features to presen t the sp eaker’s c haracteristics. Because a user almost al- w ays provides several audios to train the ASR mo del, statistical calculation is applied to the three features ab o ve, including sum, maxim um, minimum, a verage, The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 6 T able 1. The audit model’s performance when selecting either 3 features, 5 features, or 5 features with MFCCs for each audio’s query . F1-score Precision Recall Accuracy Feature_Set3 63.89% 68.48% 60.84% 61.13% Feature_Set5 81.66% 81.40% 82.22% 78.81% Feature_Set5 + MF CCs 81.01% 79.72% 82.52% 77.82% median, standard deviation, and v ariance. After the fea- ture extraction, all user-level records are gathered with lab els to train an auditor model using a sup ervised learning algorithm. T o test the quality of the feature set ab ov e, we trained an auditor with 500 user-lev el samples using the Random F orest (RF) algorithm. By randomly selecting 500 samples 100 times, we achiev e an av erage accuracy result o ver 60%. Apart from the three aforementioned features, tw o additional features are added to capture more v ariations in the mo del’s p erformance, including missing c haracters and extra c haracters obtained from the transcriptions. F or example, if (truth tr anscrip- tion, pr e dicte d tr anscription) = (THA T IS KAFF AR’S KNIFE, THA T IS CALF OUR’S KNIFE) , then (miss- ing char acters, extr a char acters) = (KF A, CL OU) . Herein, the blank character in the extra characters means that one w ord was mistranslated as tw o w ords. With these tw o extra features, a total of fiv e features are extracted from record-lev el samples: similarity sc or e, missing char acters, extr a char acters, fr ame length, and sp e e d . The record-level samples are transformed into user-lev el samples using statistical calculation as pre- viously describ ed. W e compare the p erformance of tw o auditors trained with the tw o feature sets. W e also consider adding 13 Mel-F requency Cepstral Co efficients (MF CCs) as the additional audio-sp ecific feature set to accen tuate each user’s records with the av erage statis- tics. As seen in T able 1, the statistical feature set with 5-tuple is the best choice with approximately 80% accu- racy , while the results with additional audio-sp ecific fea- tures are similar, but trail by one percentage. Th us, w e pro ceed with five statistical features to represent eac h user as the outcome of the feature extraction step. A uditing Pro cess. After training an auditor mo del, w e randomly sample a particular sp eaker’s ( u 0 s ) au- dios A u from D users to query our target ASR mo del. With the same feature extraction, the outputs can b e passed to the auditor mo del to determine whether this sp eak er u ∈ U tar . W e assume that our target mo del’s dataset D tar is disjoint from the auxiliary reference dataset D ref ( D tar ∩ D ref = ∅ ). In addition, U ref and U tar are also disjoin t ( U tar ∩ U ref = ∅ ). F or each user, as T able 2. The audit model’s performance trained with different algorithms. F1-sco re Precision Recall A ccuracy DT 68.67% 70.62% 67.29% 64.97% RF 81.66% 81.40% 82.22% 78.81% 3 -NN 58.62% 64.49% 54.69% 56.16% NB 34.42% 93.55% 21.09% 53.96% w e will sho w, only a limited n umber of audios are needed to query the target mo del and complete the whole au- diting phase. 3.3 Implementation In these exp eriments, w e take audios from Lib- riSp eec h [25], TIMIT [9], and TED-LIUM [30] to build our target ASR mo del and the shadow mo del. Detailed information ab out the sp eech corpora and mo del archi- tectures can b e found in the App endix. Since the Lib- riSp eec h corpus has the largest audio sets, we primarily source records from LibriSpeech to build our shadow mo dels. T arget Mo del. Our target mo del is a sp eech-to-text ASR model. The inputs are a set of audio files with their corresp onding transcriptions as lab els, while the outputs are the transcrib ed sequential texts. T o simu- late most of the current ASR mo dels in the real world, w e created a state-of-the-art h ybrid ASR mo del [35] us- ing the PyT orch-Kaldi Sp eech Recognition T oolkit [29] and an end-to-end ASR mo del using the Pytorc h imple- men tation [14]. In the prepro cessing step, fMLLR fea- tures w ere used to train the ASR mo del with 24 training ep o c hs. Then, we trained an ASR mo del using a deep neural net work with four hidden la yers and one Softmax la yer. W e exp erimentally tuned the batch size, learning rate and optimization function to gain a model with b etter ASR p erformance. T o mimic the ASR mo del in the wild, w e tuned the parameters un til the training accuracy exceeded 80%, similar to the results shown in [14, 27]. Additionally , to better contextualize our au- dit results, w e rep ort the ov erfitting level of the ASR mo dels, defined as the difference betw een the predic- tions’ W ord Error Rate (WER) on the training set and the testing set ( O v erf itting = W E R train − W E R test ). The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 7 4 Exp erimental Evaluation and Results The goal of this work is to develop an auditor for users to insp ect whether their audio information is used without consen t by ASR mo dels or not. W e mainly focus on the ev aluation of the auditor, esp ecially in terms of its ef- fectiv eness, efficiency , and robustness. As such, w e p ose the following research questions. – The effe ctiveness of the auditor. W e train our au- ditor using different ML algorithms and select one with the best p erformance. How do es the auditor p erform with differen t sizes of training sets? How do es it p erform in the real-w orld scenario, suc h as auditing iPhone Siri? – The efficiency of the auditor. How many pieces of audios does a user need for querying the ASR model and the auditor to gain a satisfying result? – The data tr ansfer ability of the auditor. If the data distribution of the target ASR mo del’s training set is differen t from that of the auditor, is there any effect on the auditor’s performance? If there is a negativ e effect on the auditor, is there any approac h to mitigate it? – The r obustness of the auditor. How does the auditor p erform when auditing the ASR mo del built with differen t architectures and pip elines? How do es an an auditor p erform when a user queries the auditor with audios recorded in a noisy environmen t (i.e., noisy queries)? 4.1 Effect of the ML Algorithm Choice fo r the Audito r W e ev aluate our audio auditor as a user-lev el mem b er- ship inference mo del against the target ASR system. This inference mo del is p osed as a binary classification problem, which can be trained with a sup ervised ML al- gorithm. W e first consider the effect of different training algorithms on our auditor p erformance. T o test the effect of differen t algorithms on our audit metho dology , we need to train one shadow ASR mo del for training the auditor and one target ASR mo del for the auditor’s auditing phase. W e assume the target ASR mo del is a h ybrid ASR system whose acoustic mo del is trained with a four-lay er LSTM netw ork. The train- ing set used for the target ASR mo del is 100 hours of clean audio sampled from the LibriSp eech corpus [25]. A dditionally , the shadow mo del is trained using a hy- brid ASR structure where GRU netw ork is used to build its acoustic mo del. According to our audit methodol- ogy demonstrated in Fig. 2, we observe the v arious per- formance of the audio auditor trained with four p opu- lar sup ervised ML algorithms listing as Decision T ree (DT), Random F orest (RF), k -Nearest Neighbor where k = 3 ( 3 -NN), and Naive Ba yes (NB). After feature ex- traction, 500 users’ samples from the shado w model’s query results are randomly selected as the auditor’s training set. T o a void p otential bias in the auditor, the n umber of “member” samples and the num b er of “non- mem b er” samples are equal in all training set splits ( # { u ∈ U shd } = # { u / ∈ U shd } ). An additional step tak en to eliminate bias, is that each exp erimental con- figuration is rep eated 100 times. Their a verage result is rep orted as the respective auditor’s final performance in T able 2. As shown in T able 2, our four metrics of accuracy , precision, recall, and F1-score are used to ev aluate the audio auditor. In general, the RF auditor ac hieves the b est performance compared to the other algorithms. Sp ecifically , the accuracy approac hes 80%, with the other three metrics also exceeding 80%. W e note that all auditors’ accuracy results exceed the random guess (50%). Aside from the RF and DT auditors, the au- ditor with other ML algorithms behav es significan tly differen tly in terms of precision and recall, where the gaps of the t wo metrics are abov e 10%. The reason is in part due to the difficulty in distinguishing the “mem b er” and “nonmem b er” as a user’s audios are all transcrib ed w ell at a low speed with short sentences. T ree-based al- gorithms, with righ t sequences of conditions, ma y be more suitable to discriminate the membership. W e re- gard the RF construction of the auditor as b eing the most successful; as suc h, RF is the chosen audio auditor algorithm for the remaining exp eriments. 4.2 Effect of the Numb er of Users Used in T raining Set of the A uditor T o study the effect of the num b er of users, we assume that our target model and shado w mo del are trained using the same arc hitecture (hybrid ASR system). Ho w- ev er, due to the strict black-box access to the tar- get mo del, the shadow mo del and acoustic mo del shall b e trained using differen t netw orks. Sp ecifically , LSTM net works are used to train the acoustic model of the target ASR system, while a GR U netw ork is used for the shado w mo del. As depicted in Fig. 3, eac h training The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 8 Fig. 3. Audito r model performance with va ried training set size. sample ( x i , y i ) is formed b y calculating shadow model’s querying results for each user u j ← S m i =1 ( x i , y i ) . Herein, w e train the audio auditor with a v arying num b er of users ( j = 1 , ..., M ) . The amount of users M we consid- ered in the auditor training set is 10, 30, 50, 80, 100, 200, 500, 1,000, 2,000, 5,000, and 10,000. On the smaller num b ers of users in the auditor’s training set, from Fig. 3, we observ e a rapid increase in p erformance with an increasing num b er of users. Herein, the av erage accuracy of the auditor is 66.24% initially , reac hing 78.81% when the training set size is 500 users. F rom 500 users, the accuracy decreases then plateaus. Ov erall, the accuracy is b etter than the random guess baseline of 50% for all algorithms. Aside from accuracy , the precision increases from 69.99% to 80.40%; the recall is 73.69% initially and even tually approaches approxi- mately 90%; and the F1-score is ab out 80% when the training set size exceeds 200. In summary , we identify the auditor’s p e ak p erformanc e when using a r elatively smal l numb er of users for tr aining. Recall the definition of user-level membership in Section 3.1. W e further consider tw o extreme scenarios in the auditor’s testing set. One extreme case is that the auditor’s testing set only contains member users querying with the unseen audios (excluded from the tar- get mo del’s training set), henceforth denoted as A out mem . The other extreme case is an auditor’s testing set that only contains mem b er users querying with the seen au- dios (exclusiv ely from the target mo del’s training set), herein mark ed as A in mem . Fig. 4 rep orts the accuracy of our auditor on A in mem v ersus A out mem . If an ASR mo del w ere to use a user’s recordings as its training samples ( A in mem ), the auditor can determine the user-lev el mem- b ership with a m uch higher accuracy , when compared to user queries on the ASR mo del with A out mem . Sp ecifically , A in mem has a p eak accuracy of 93.62% when the audi- tor’s training set size M is 5,000. Considering the p eak Fig. 4. Audito r model accuracy on a memb er user querying with the target mo del’s unseen audios ( A out mem ) against the p erfor- mances on the memb er users only querying with the seen reco rd- ings ( A in mem ). p erformance previously shown in Fig. 3, auditing with A in mem still ac hieves go o d accuracy (around 85%) de- spite a relativ ely small training set size. Comparing the results sho wn in Fig. 3 and Fig. 4, w e can infer that the larger the auditor’s training set size is, the more likely nonmem b er users are to b e misclassified. The auditor’s o verall p erformance peak when using a small num ber of the training set is largely due to the high accuracy of the shadow mo del. A large num b er of training sam- ples perhaps con tain the large prop ortion of nonmember users’ records whose translation accuracy is similar to the member users’ . Ov erall, it is b etter for users to choose audios that ha ve a higher likelihoo d of b eing contained within the ASR mo del for audit (for example, the audios once heard by the mo del). 4.3 Effect of the T arget Mo del T rained with Different Data Distributions The previous exp eriment dra ws conclusions based on the assumption that the distributions of training sets for the shadow mo del and the target mo del are the same. That is, these tw o sets were sampled from LibriSp eech corpus D L ( A tar ∼ D L , A shd ∼ D L , A tar ∩ A shd = ∅ ). Aside from the effects that a c hanging num b er of users used to train the auditor, w e relax this distribution as- sumption to ev aluate the data transferabilit y of the au- ditor. T o this end, w e train one auditor using a training set sampled from LibriSpeech D L ( A shd ∼ D L ). Three The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 9 (a) Accuracy (b) Precision (c) Recall Fig. 5. The audito r model audits target ASR models trained with training sets of different data distributions. W e observe that in re- gards to accuracy and recall the target mo del with the same distribution as the audito r performs the best, while the contra ry is ob- served for precision. Nevertheless, the data transferability is well observed with reasonably high metrics fo r all data distributions. differen t target ASR mo dels are built using data selected from LibriSp eech, TIMIT, and TED, resp ectiv ely . Fig. 5 plots the auditor’s data transferabilit y on av- erage accuracy , precision, and recall. Once ab ov e a cer- tain threshold of the training set size ( ≈ 10 ), the p er- formance of our auditor significantly improv es with an increasing n umber of users data selected as its user-lev el training samples. Comparing the p eak results, the audit of the target mo del trained with the same data distri- bution (LibriSp eec h) slightly outp erforms the audit of target mo dels with differen t distributions (TIMIT and TED). F or instance, the a verage accuracy of the au- ditor auditing LibriSpeech data reac hes 78.81% when training set size is 500, while the av erage audit accuracy of the TIMIT target mo del p eaks at 72.62% for 2,000 users. Lastly the av erage audit accuracy of TED target mo del reaches its maximum of 66.92% with 500 users. As shown in Fig. 5, the p eaks of precision of the Lib- riSp eec h, TIMIT, and TED target mo del are 81.40%, 93.54%, and 100%, resp ectively , opp osite of what was observ ed with accuracy and recall. The observ ation of the TED target mo del with extremely high precision and low recall is p erhaps due to the dataset’s charac- teristics, where all of the audio clips of TED are long sp eec hes recorded in a noisy environmen t. In conclusion, our auditor demonstrates satisfying data transferability in general. Fig. 6. A compa rison of average accuracy for one audio, five au- dios, and all audios per user when training the audito r model with a limited number of audios per user gained in the auditing phase. Fig. 7. A va rying number of audios used for each speaker when querying an auditor model trained with 5 audios per user. The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 10 4.4 Effect of the Numb er of A udio Reco rds p er User The fewer audio samples a sp eaker is required to sub- mit for their user-level query during the auditing phase, the more conv enient it is for users to use the auditor. A dditionally , if the auditor can b e trained with user- lev el training samples accum ulated from a reduced n um- b er of audios p er user, both added conv enience and the efficiency of feature prepro cessing during the auditor’s training can b e realized. A limited num b er of audio samples p er user v ersus a large n um b er of audio samples per user. Assuming that eac h user audits their target ASR mo del b y querying with a limited num b er of audios, w e shall consider whether a small num b er or a large num b er of audio samples p er user should b e collected to train our auditor. Herein, v arying the n umber of audios p er user only affects the user-lev el information learned b y the auditor during the training phase. T o ev aluate this, we ha ve sampled one, five, and all audios p er user as the training sets when the querying set uses five audios p er user. Fig. 6 compares the av erage accuracy of the audi- tors when their training sets are pro cessed from limits of one audio, five audios, and finally all audios of each user. T o set up the five audio auditor’s training sets, w e randomly select five audios recorded from each user u j ← S m =5 i =1 ( x i , y i ) , then translate these audios using the shadow mo del to pro duce five transcriptions. F ol- lo wing the feature prepro cessing demonstrated in Sec- tion 3, user-level information for each user is extracted from these five output transcriptions with their corre- sp onding input audios. The same pro cess is applied to construct the auditor in which the training data consists of one audio per user. T o set up the auditor’s training set with all the users’ samples, we collect all audios spoken b y each user and rep eat the pro cess mentioned ab ov e (a verage ¯ m > 62 ). Moreov er, since the t wo auditors’ set- tings abov e rely on randomly selected users, eac h config- uration is rep eated 100 times, with users sampled anew, to rep ort the av erage result free of sampling biases. Fig. 6 demonstrates that the auditor p erforms b est when leveraging five audios per user during the feature prepro cessing stage. When a small n umber of users are presen t in the training set, the p erformance of the tw o auditors is fairly similar, except the auditor trained with one audio p er user. F or example, when only ten users are randomly selected to train the auditor, the a verage accuracy of these t wo auditors are 61.21% and 61.11%. When increasing to 30 users in the training set, the av- erage accuracy of the 5-sample and all-sample auditors is 65.65% and 64.56%, respectively . Ho wev er, with more than 30 users in the training set, the auditor trained on fiv e audios p er user outp erforms that using all audios p er user. Sp ecifically , when using five audios p er user, the auditor’s a verage accuracy rises to ≈ 70% with a larger training set size; compared to the auditor using all audios p er user, with a degraded accuracy of ≈ 55%. This is in part o wing to the difficulty of accurately charac- terizing users’ audios. In conclusion, despite restrictions on the num ber of user audio samples when training the auditor, the auditor can achie ve sup erior p erformance. Consequen tly , we recommend that the num b er of au- dios per user collected for the auditor’s training pro cess should b e the same for the auditor’s querying pro cess. A limited num b er of audio samples p er user while querying the auditor. While w e ha ve inv es- tigated the effect of using a limited num b er of audios p er user to build the training set, we now ask ho w the auditor p erforms with a reduced n umber of audios pro- vided by the user during the querying stage of the au- dit pro cess, and how man y audios eac h user needs to submit to preserve the p erformance of this auditor. W e assume our auditor has b een trained using the training set computed with five audios p er user. Fig. 7 displays p erformance trends (accuracy , precision, recall, and F1- score) when a v arying n umber of query audios p er user is provided to the target mo del. W e randomly select a user’s audios to query the target mo del by testing m = 1, 3, 5, 7, 9, or 11 audios p er user. As Fig. 6 reveals that the accuracy results are stable when training set size is large, we conduct our experiments using 10,000 records in the auditor training set. Again, each exp eriment is rep eated 100 times, and the results are all av eraged. Fig. 7 illustrates that the auditor performs w ell with results all ab ov e 60%. Apart from recall, the other three p erformances trend up wards with an increasing num ber of audios p er user. The scores of the accuracy , precision, and F1-score are approximately 75%, 81%, and 78%, resp ectiv ely , when each user queries the target mo del with nine audios, indicating an improv ement ov er the accuracy ( ≈ 72%) we previously observed in Fig. 3. It app ears, for accuracy , when the n umber of query au- dios p er user gro ws, the upw ard trend slows do wn and ev en sligh tly declines. The recall is maximized (89.78%) with only one audio queried b y eac h user, decreasing to 70.97% with eleven audios queried for eac h user. It migh t happ en b ecause the increased num b er of audio p er user do es not mean the increased num b er of users (i.e., testing samples). Since the auditor w as trained with fiv e audios p er user, the auditor may fail to recog- The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 11 T able 3. Info rmation about ASR mo dels trained with different architectures. ( W E R train : the prediction’s WER on the training set; W E R test : the prediction’s WER on the testing set; t: ta rget model; s: shadow mo del.). ASR Models Model’s Architecture Dataset Size W E R train W E R test LSTM-ASR (s) 4-LSTM lay er + Softmax 360 hrs 6.48% 9.17% RNN-ASR (s) 4-RNN lay er + Softmax 360 hrs 9.45% 11.09% GRU-ASR (s) 5-GRU lay er + Softmax 360 hrs 5.99% 8.48% LSTM-ASR (t) 4-LSTM layer + Softmax 100 hrs 5.06% 9.08% nize the user’s membership when querying with many more audios. Ov erall, with only a limited n umber of audios used for audit, e.g. nine audios per user, our auditor still effectiv ely discriminates a user’s membership in the target mo del’s training set. 4.5 Effect of T raining Shadow Mo dels across Different Architectures A shado w model trained with different architectures in- fluences how well it mimics the target mo del and the p erformance of the user-lev el audio auditor. In this sub- section, w e exp eriment with differen t shadow mo del ar- c hitectures b y training the auditor with information from v arious netw ork algorithms, like LSTM, RNNs, GR U. If the choice of a shadow mo del algorithm has a substantial impact on the auditor’s p erformance, we shall seek a metho d to lessen such an impact. W e also seek to ev aluate the influence of the combining attack as prop osed b y Salem et al. [32], by combining the tran- scription results from a set of ASR shadow models, in- stead of one, to construct the auditor’s training set. The feature extraction metho d is demonstrated in Section 3. W e refer to this combination as user-level c ombining au- dit . T o explore the specific impact of arc hitecture, w e assume that the acoustic mo del of the target ASR sys- tem is mainly built with the LSTM netw ork (we call this model the LSTM-ASR T arget model). W e consider three p opular algorithms, LSTM, RNNs, and GR U net- w orks, to b e prepared for the shadow mo del’s acoustic mo del. The details of the target and shado w ASR mod- els abov e are display ed in T able 3. Each shadow mo del is used to translate v arious audios, with their results pro cessed into the user-level information to train an au- ditor. Consider this, the shadow model that mainly uses the GRU netw ork structure to train its acoustic model is mark ed as the GR U-ASR shado w model; its corresp ond- ing auditor, named GR U-based auditor, is built using the training set constructed from GRU-ASR shadow mo del’s query results. Our other tw o auditors ha v e a similar naming con v ention, an LSTM-based auditor and an RNN-based auditor. Moreov er, as demonstrated in Fig. 2, we combine these three shadow mo dels’ results ( n = 3 ), and construct user-level training samples to train a new combined auditor. This auditor is denoted as the Combine d A uditor that learns all kinds of p opular ASR mo dels. Fig. 8 demonstrates the v aried auditor p erformance (accuracy , precision and recall) when shadow mo dels us- ing v arious algorithms are deploy ed. F or accuracy , all four auditors show an up ward trend with a small train- ing set size. The p eak is observed at 500 training samples then deca ys to a stable smaller v alue at h uge training set sizes. The GRU-based auditor surpasses the other three auditors in terms of accuracy , with the Combined A uditor p erforming the second-b est when the auditor’s training set size is smaller than 500. As for precision, all exp eriments show relatively high v alues (all abov e 60%), particularly the LSTM-based auditor with a pre- cision exceeding 80%. According to Fig. 8c), the RNN- based auditor and GRU-based auditor show an up ward trend in recalls. Herein, both of their recalls exceed 80% when the training set size is larger than 500. The recall trends for the LSTM-based auditor and the Combined A uditor follows the opp osite trend as that of GRU and RNN-based auditors. In general, the RNN-based audi- tor p erforms well across all three metrics. The LSTM- based auditor sho ws an excellent precision, while the GR U-based auditor obtains the highest accuracy . The algorithm selected for the shado w mo del will influence the auditor’s p erformance. The Com bined A uditor can achiev e accuracy higher than the a v- erage, only if its training set is relativ ely small. 4.6 Effect of Noisy Queries An ev aluation of the user-level audio auditor’s robust- ness, when provided with noisy audios, is also con- ducted. W e also consider the effect of the noisy audios when querying differen t kinds of auditors trained on dif- feren t shado w mo del architectures. W e shall describe the p erformance of the auditor with t wo metrics — preci- sion and recall; these results are illustrated in Fig. 9. The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 12 (a) Accuracy (b) Precision (c) Recall Fig. 8. Different audito r model performance when trained with different ASR shado w model a rchitectures. T o explore the effect of noisy queries, w e assume that our target mo del is trained with noisy audios. Un- der the strict black-box access to this target mo del, we shall use differen t neural net w ork structures to build the target mo del(s) and the shadow model(s). That is, the target mo del is an LSTM-ASR target mo del, while the GR U-ASR shado w model is used to train the GR U- based auditor. F or ev aluating the effect of the noisy queries, tw o target mo dels are prepared using (i) clean audios (100 hours) and (ii) noisy audios (500 hours) as training sets. In addition to the GRU-based auditor, another tw o auditors are constructed, an LSTM-based auditor and an RNN-based auditor. The target mod- els audited by the latter tw o auditors are the same as the GR U-based auditor. Herein, the LSTM-based audi- tor has an LSTM-ASR shadow mo del whose acoustic mo del shares the same algorithm as its LSTM-ASR tar- get mo del. Fig. 9a and Fig. 9d compare the precision and recall of the GR U-based auditor on target mo dels trained with clean and noisy queries, resp ectively . Overall, the audi- tor’s performance drops when auditing noisy queries, but the auditor still outperforms the random guess ( > 50%). By v arying the size of the auditor’s training set, w e observ e the precision of the auditor querying clean and noisy audios displaying similar trends. When querying noisy audios, the largest change in precision is ≈ 11%, where the auditor’s training set size w as 500. Its precision results of querying clean and noisy audios are around 81% and 70%, resp ectively . Ho wev er, the trends of the t wo recall results are fairly the opposite, and noisy queries’ recalls are decreasing remarkably . The low est decen t rate of the recall is ab out 42%, where the au- ditor was trained with ten training samples. Its recall results of querying tw o kinds of audios are around 74% and 32%. In conclusion, we observ e the impact of noisy queries on our auditor is fairly negative. Fig. 9b and Fig. 9e display the LSTM-based audi- tor’s precision and recall, respectively , while Fig. 9c and Fig. 9f illustrate the RNN-based auditor’s p erformance. Similar trends are observ ed from the earlier precision re- sults in the RNN-based auditor when querying clean and noisy queries. How ever, curiously , the RNN-based audi- tor, when querying noisy audios, sligh tly outp erforms queries on clean audios. Similar to the noisy queries effect on GRU-based auditor, the noisy queries’ recall of the RNN-based auditor decreases significantly versus the results of querying the clean audios. Though noisy queries show a negative effect, all recalls p erformed by the RNN-based auditor exceed 50%, the random guess. As for the effect of noisy queries on the LSTM-based auditor, unlik e GR U-based auditor and RNN-based au- ditor, the LSTM-based auditor demonstrates high ro- bustness on noisy queries. F or the most results of its precision and recall, the differences b etw een the perfor- mance on clean and noisy queries are no more than 5%. In conclusion, noisy queries create a negativ e effect on our auditor’s p erformance. Y et, if the shadow ASR mo del and the target ASR mo del are trained with the same algorithm, the negative effect can b e largely eliminated. 4.7 Effect of Different ASR Mo del Pip elines on Audito r Perfo rmance Aside from the ASR mo del’s architecture, we examine the user-level auditor’s robustness on differen t pipelines commonly found in ASR systems. In this section, the The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 13 (a) GRU-based A uditor Pre cision (b) LSTM-based A uditor Precision (c) RNN-based A uditor Precision (d) GRU-based A uditor Recall (e) L TSM-based Audito r Recall (f ) RNN-based A uditor Recall Fig. 9. Different audito r audits noisy queries with different ASR shado w model. ASR pip eline is not just a machine learning, instead a complicated system, as sho wn in Fig. 1. In practice, the t wo most p opular pip elines adopted in ASR systems are: a hybrid ASR system, or an end-to-end ASR system. W e build our auditor using the GRU-ASR shadow mo del with tw o target mo dels trained on systems built on the aforemen tioned ASR pip elines. Sp ecifically , one target mo del utilizes the Pytorch-Kaldi to olkit to construct a h ybrid DNN-HMM ASR system, while the other target mo del employs an end-to-end ASR system. Fig. 10 reports the performance (accuracy , preci- sion, and recall) of the auditor when auditing the t wo differen t target pip elines. Overall, the auditor b ehav es w ell o ver all metrics when auditing either target mo dels (all ab ov e 50%). The auditor alw ays demonstrates go o d p erformance when using a small num b er of training samples. The auditor targeting h ybrid ASR in compar- ison to the end-to-end ASR target ac hieves a b etter re- sult. A possible reason is that our auditor is constituted with a shadow model whic h has a hybrid ASR architec- ture. When fo cusing on the accuracy , the highest audit score of the hybrid ASR target mo del is 78.8%, while that of the end-to-end ASR target mo del is 71.92%. The difference in the auditor’s precision is not substantially , with their highest precision scores as 81.4% and 79.1%, resp ectiv ely . How ever, in terms of recall, the auditor’s abilit y to determine the user-level membership on the h ybrid ASR target mo del is m uch higher than the end- to-end target mo del, with maximum recall of 90% and 72%, resp ectively . When auditing the h ybrid ASR target mo del we ob- serv ed the mo del significan tly outp erforming other mo d- els. The training and testing data for b oth state-of-the- art ASR mo del architectures (i.e., hybrid and end-to- end) are the same. Thus, to confiden tly understand the impact of differen t ASR mo del pip elines on the auditor’s p erformance, w e shall also in vestigate the difference be- t ween the ov erfitting level of the h ybrid ASR target mo del and that of the end-to-end ASR target mo del, as the ov erfitting of the mo del increases the success rate of mem b ership inference attacks [39]. Recall that ov erfit- ting was previously defined in Section 3.3. The ov erfit- ting v alue of the hybrid ASR target mo del is measured as 0.04, while the o verfitting lev el of the end-to-end ASR target mo del is 0.14. Contrary to the conclusions ob- serv ed by [32], the target mo del that was more ov erfit The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 14 (a) Accuracy (b) Precision (c) Recall Fig. 10. The audit mo del audits different ta rget ASR mo dels trained with different pip elines. did not increase the p erformance of our user-level audio auditor. One lik ely reason is that our auditor audits the target mo del by considering user-level information un- der strict black-box access. Compared to conv entional blac k-b ox access in [32], our strict black-box access ob- tains its output from the transcrib ed text alone; con- sequen tly the influence of ov erfitting on sp ecific w ords (WER) would b e minimized. Thus, we can observe that our auditor’s success is not entirely attributed to the degree of the target ASR model’s ov erfitting alone. In conclusion, differen t ASR pip elines betw een the target model and the shadow mo del negatively im- pact the p erformance of the auditor. Neverthe- less, our auditor still p erforms w ell when the tar- get mo del is trained following a differen t pip eline (i.e., an end-to-end ASR system), significan tly out- p erforming random guesses (50%). 4.8 Real-W o rld A udit T est T o test the practicality of our mo del in the real world, w e keep our auditor mo del lo cally and conduct a pro of- of-concept trial to audit iPhone Siri’s sp eech-to-text ser- vice. W e select the auditor trained b y the GR U shadow mo del with LibriSp eech 360-hour voice data as its train- ing set. T o simplify the experiments, w e sample five au- dios per user for each user’s audit. A ccording to the results presented in Fig. 6 and Fig. 7, we select the au- ditor trained with five audios p er user, where 1,000 users w ere sampled randomly as the auditor’s training set. T o gain the a verage p erformance of our auditor in the real w orld, we stored 100 auditors under the same settings with the training set constructed 100 times. The final p erformance is the av erage of these 100 auditors’ results. T estb ed and Data Prepro cess. The iPhone Siri pro- vides strict black-box access to users, and the only dicta- tion result is its predicted text. All dictation tasks w ere completed and all audios were recorded in a quiet sur- rounding. The clean audios were play ed via a Blueto oth sp eak er to ensure Siri can sense the audios. User-level features were extracted as p er Section 3.2. The Siri is targeted on iPhone X of iOS 13.4.1. Ground T ruth. W e target a particular user ˆ u iPhone Siri’s sp eech-to-text service. F rom Apple’s priv acy p ol- icy of Siri (see Appendix D), iPhone user’s Siri’s record- ings can be selected to impro ve Siri and dictation service in the long-term (for up to t wo y ears). W e do note that this is an opt-in service. Simply put, this user can b e lab eled as “member” . As for the “nonmember” user, we randomly selected 52 speakers from LibriSpeech dataset whic h w as collected b efore 2014 [25]. As stated b y the iPhone Siri’s priv acy p olicy , users’ data “may b e re- tained for up to tw o years” . Th us, audios sampled from LibriSp eec h can be considered out of this Siri’s training set. W e further regard the corresponding speakers of LibriSp eec h as “nonmember” users. T o av oid nonmem- b er audios en tering Siri’s training data to retrain its ASR mo del during the testing time, eac h user’s querying audios w ere completed on the same da y we commenced tests for that user, with the Improv e Siri & Dictation setting turned off. As w e defined abov e, a “mem b er” may make the fol- lo wing queries to our auditor: querying the auditor (i) with audios within the target mo del’s training set ( D ˆ u = S A in mem ); (ii) with audios out of the target mo del’s training set ( D ˆ u = S A out mem ); (iii) with part of his or her audios within the target mo del’s training set ( D ˆ u = The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 15 ( S A in mem ) S ( S A out mem ) ). Thus, we generate six “mem- b er” samples where the audios were all recorded b y the target iPhone’s owner, including D ˆ u = S k =5 A in mem , D ˆ u = S m =5 A out mem , and D ˆ u = ( S k A in mem ) S ( S m A out mem ) , where k = 1 , 2 , 3 and k + m = 5 . In total, we collected 58 user-lev el samples with 6 “member” and 52 “nonmem- b er” samples. Results. W e load 100 auditors to test those samples and the av eraged ov erall accuracy as 89.76%. Sp ecifi- cally , the a verage precision of predicting the “member” samples is 58.45%, while the av erage precision of pre- dicting the “nonmem b er” samples is 92.61%. The av- erage ROC AUC result is 72.6%, which indicates our auditor’s separability in this experiment. Except for the differen t b eha viors of Siri translating the audios from “mem b er” and “nonmem b er” users, w e suspect that an- other reason of high precision on “nonmember” is due to the LibriSp eech audios are out of Siri’s dictation scop e. As for the lo w precision rate on “member” sam- ples, we single out the data D ˆ u = S k =5 A in mem for test- ing. Additionally , its av erage accuracy result can reach 100%; thus, the auditor is muc h more capable in han- dling A in mem than A out mem , corroborating our observ ation in Section 4.2. In conclusion, our auditor shows a generally satis- fying p erformance for users auditing a real-w orld ASR system, Apple’s Siri on iPhone. 5 Threats to A udito rs’ V alidit y V oiceprin ts Anonymization. In determining the user-lev el membership of audios in the ASR mo del, our auditor relies on the target mo del’s different b ehaviors when presented with training and unseen samples. The auditor’s qualit y dep ends on the diverse resp onses of the target model when translating audio from differ- en t users. The feature is named users’ voiceprin ts. The v oiceprint is measured in [28] based on a sp eak er recog- nition system’s accuracy . Our auditor represents the user’s v oiceprint according to tw o accum ulated features, including missing c haracters and extra characters. Ho w- ev er, if an ASR system is built using voice anonymiza- tion, our user-level auditor’s p erformance would degrade significan tly . The sp eaker’s v oice is disguised in [28] by using robust v oice conv ersation while ensuring the cor- rectness of speech conten t recognition. Herein, the most p opular technique of voice conv ersation is frequency w arping [43]. In addition, abundant information ab out sp eak ers’ identities is remo ved in [42] b y using adversar- ial training for the audio conten t feature. Fig. 1 sho ws that the av erage accuracy of the auditor dropp ed b y appro ximately 20% without using the t wo essen tial fea- tures. Hence, auditing user-level membership in a speech recognition mo del trained with anon ymized voiceprin ts remains as a future av enue of research. Differen tially Priv ate Recognition Systems. Dif- feren tial priv acy (DP) is one of the most popular meth- o ds to prev ent ML models from leaking an y training data information. The w ork [40] protects the text gen- erativ e mo del b y applying user-lev el DP to its language mo del. This metho d contains a language mo del during the hybrid ASR system’s training, on which the user- lev el DP can b e applied to obscure the identit y , at the sacrifice of transcription p erformance. The sp eaker and sp eec h characterization pro cess is protected in [23] by inserting noise during the learning pro cess. How ev er, due to strict blac k-b ox access and the lack of output probabilit y information, our auditor’s p erformance re- mains unknown on auditing the ASR mo del with DP . The inv estigation of our auditor’s p erformance to this user protection mechanism is op en for future research. W orkarounds and Coun termeasures. Although Salem et al. [32] has shown neither the shadow mo del nor the attack mo del are required to p erform mem b er- ship inference, due to the constrain ts of strict blac k- b o x access, the shadow mo del and auditor mo del ap- proac h provide a promising means to p erform a more difficult task of user-level membership inference. In- stead of the output probabilities, we mainly lev erage the ASR mo del’s translation errors in the character level to represen t the mo del’s behaviors. Alternative coun- termeasures against the membership inference, such as drop out, generally change the target mo del’s output probabilit y . Ho wev er, the changes to probabilities of the ASR mo del’s output are not as sensitive as changes to its translated text [32]. Studying the exten t of this sen- sitivit y of ASR mo dels remains as our future work. Syn thetic ASR Mo dels. Another limitation of our w ork is that we ev aluate our auditor on synthetic ASR systems trained on real-world datasets, and we ha v e not applied the auditor to extensive set of real-world m o dels aside from Siri. How ever, w e believe that our reconstruc- tion of the ASR mo dels closely mirrors ASR mo dels in the wild. The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 16 6 Related W o rk Mem b ership Inference A ttacks. The attack distin- guishes whether a particular data sample is a member of the target mo del’s training set or not. T raditional mem b ership inference attac ks against ML models under blac k-b ox access leverage numerous shadow mo dels to mimic the target mo del’s b ehavior [10, 17, 39]. Salem et al. [32] revealed that membership inference attacks could b e launc hed by directly utilizing the prediction probabilities and thresholds of the target mo del. Both w orks [17] and [49] prov e that o verfitting of a mo del is sufficien t but not a necessit y to the success of a member- ship inference attack. Y eom et al. [49] as well as F arokhi and Kaafar [8] formalize the membership inference at- tac k with black-box and white-box access. All previ- ously mentioned works consider record-level inference; ho wev er, Song and Shmatiko v [40] deplo y a user-level mem b ership inference attack in text generativ e mo dels, with only the top- n predictions kno wn. T rust worthiness of ASR Systems. The ASR sys- tems are often deploy ed on voice-con trolled devices [5], v oice p ersonal assistants [37], and machine translation services [6]. T ung and Shin [45] propose SafeChat to utilize a masking sound to distinguish authorized au- dios from unauthorized recording to protect any infor- mation leakage. Recent works [18] and [44] prop ose an audio cloning attac k and audio reply attack against the sp eec h recognition system to imp ersonate a legitimate user or inject unin tended v oices. V oice masquerading to imp ersonate users on the voice p ersonal assistants has b een studied [50]. Whereas Zhang et al. [50] propose another attac k, namely voic e squatting , to hijac k the user’s v oice command, pro ducing a sentence similar to the legal command. Du et al. [6] generate the adv ersarial audio samples to deceive the end-to-end ASR systems. A uditing ML Mo dels. Many of the curren t proposed auditing services also seek to audit the bias and fairness of a given mo del [31]. W orks ha ve also b een presen ted to audit the ML mo del to learn and chec k the mo del’s prediction reliability [1, 12, 36]. Moreov er, the auditor is utilized to ev aluate the ML model’s priv acy risk when protecting an individual’s digital rights [21, 40]. Our W ork. Our user-level audio auditor audits the ASR mo del under the strict black-box access. As sho wn in Section 3, we utilize the ASR mo del’s translation errors in the c haracter lev el to represent the mo del’s b eha vior. Compared to related works under black-box access, our auditor do es not rely on the target mo del’s output probabilit y [32, 39]. In addition, w e sidestep the feature pattern of sev eral top-ranked outputs of the tar- get mo del adopted by Song and Shmatik ov [40], instead w e use one text output, the user’s sp eed, and the in- put audio’s true transcription, as w e do not hav e access to the output probability (usually unattainable in ASR systems). Hence, our constraints of strict black-box ac- cess only allow accessing one top-ranked output. In this case, our user-lev el auditor (78.81%) outperforms Song’s and Shmatiko v’s user-level auditor (72.3%) in terms of accuracy . Moreo ver, Hay es et al. [10] use adversarial generativ e netw orks (GANs) to approximate the target mo del’s output probabilities while suffering big p erfor- mance p enalties with only 20% accuracy , our auditor’s accuracy is far higher. F urthermore, our auditor is muc h easier to b e trained than the solution of finding outlier records with a unique influence on the target mo del [17], b ecause w e only need to train one shadow mo del instead of many shadow (or reference) mo dels. 7 Conclusion This work highlights and exp oses the p otential of car- rying out user-level mem b ership inference audit in IoT v oice services. The auditor developed in this pap er has demonstrated promising data transferability , while al- lo wing a user to audit his or her membership with a query of only nine audios. Ev en with audios are not within the target mo del’s training set, the user’s mem- b ership can still be faithfully determined. While our w ork has y et to o verhaul the audit accuracy on v ar- ious IoT applications across multiple learning models in the wild, we do narrow the gap tow ards defining clear membership priv acy in the user level, rather than the record level [39]. How ever, questions remain ab out whether the priv acy leakage hails from the data distri- bution or its intrinsic uniqueness of the record. More detail ab out limitations are stated in App endices. Nev- ertheless, as w e hav e shown, b oth a small training set size and the Combined Auditor, which combines results from v arious ASR shado w mo dels to train the auditor, ha ve a p ositive effect on the IoT audit mo del; on the con trary , audios recorded in a noisy environmen t and differen t ASR pip elines imp ose a negativ e effect on the giv en auditor; fortunately , the auditor still outp erforms random guesses (50%). Examining other p erformance factors on more real-world ASR systems in addition to our iPhone Siri trial and extending p ossible countermea- sures against auditing are all w orth further exploration. The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 17 A ckno wledgments W e thank all anon ymous reviewers for their v aluable feedbac k. This research w as supp orted by A ustralian Researc h Council, Grant No. LP170100924. This work w as also supported by resources pro vided b y the P awsey Sup ercomputing Centre, funded from the Australian Go vernmen t and the Go vernmen t of W estern A ustralia. References [1] P . A dler, C. Falk, S. A. Friedler, T. Nix, G. Rybeck, C. Scheidegger, B. Smith, and S. Venkatasub ramanian. Au- diting black-b ox mo dels fo r indirect influence. Knowledge and Information Systems , 54(1):95–122, 2018. [2] BBC. Hmrc fo rced to delete five million voice files, 2019. URL https://www.bb c.com/news/business- 48150575. [3] D. U. CCP A. Califo rnia consumer privacy act (ccpa) website policy , 2020. [4] CCTV. Bewa re of WeChat voice scams: “cloning” users after WeChat voice, 2018. URL https://translate.google. com/translate?hl=en&sl=zh- CN&u=https://finance. sina.com.cn/money/bank/bank_hydt/2018- 11- 26/do c- ihmutuec3748767.shtml&prev=sea rch. [5] Y. Chen, X. Y uan, J. Zhang, Y. Zhao, S. Zhang, K. Chen, and X. Wang. Devil’s whisper: A general app roach for phys- ical adversarial attacks against commercial black-box sp eech recognition devices. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20) , 2020. [6] T. Du, S. Ji, J. Li, Q. Gu, T. W ang, and R. Bey ah. Sirenat- tack: Generating adversarial audio for end-to-end acoustic systems. arXiv prep rint a rXiv:1901.07846 , 2019. [7] Europ ean Parliament and Council of the Europ ean Union. Regulation (eu) 2016/679 of the Europ ean Pa rliament and of the Council of 27 April 2016 on the p rotection of natural persons with regard to the processing of p ersonal data and on the free movement of such data and repealing Directive 95/46/EC (general data protection regulation). Official Journal of the Europ ean Union , 119:1–88, 2016. [8] F. F arokhi and M. A. Kaafa r. Mo delling and quantifying membership information leakage in machine learning. arXiv prep rint arXiv:2001.10648 , 2020. [9] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, and D. S. Pallett. Darpa timit acoustic-phonetic conti- nous sp eech co rpus cd-rom. nist speech disc 1-1.1. NASA STI/Recon T echnical Rep ort , 93, 1993. [10] J. Ha yes, L. Melis, G. Danezis, and E. De Cristofa ro. Logan: Membership inference attacks against generative models. Proceedings on Privacy Enhancing T echnologies , 2019(1): 133–152, 2019. [11] A. Hern. Apple contractors ’regularly hear confiden- tial details’ on siri recordings, 2019. URL https:// www.theguardian.com/technology/2019/jul/26/apple- contractors- regularly- hear- confidential- details- on- siri- recordings. [12] P . W. Koh and P . Liang. Understanding black-box predic- tions via influence functions. In Proceedings of the 34th International Conference on Machine Learning-V olume 70 , pages 1885–1894. JMLR. org, 2017. [13] W. Kyle. How Amazon, Apple, Go ogle, Microsoft, and Sam- sung treat your voice data, 2019. URL https://ventureb eat. com/2019/04/15/how- amazon- apple- go ogle- microsoft- and- samsung- treat- your- voice- data/. [14] A. Liu, H.-y . Lee, and L.-s. Lee. Adversa rial training of end- to-end sp eech recognition using a criticizing language mo del. In Pro ceeding of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2019. [15] G. Liu, C. W ang, K. Peng, H. Huang, Y. Li, and W. Cheng. Socinf: Membership inference attacks on so cial media health data with machine learning. IEEE T ransactions on Computa- tional So cial Systems , 6(5):907–921, 2019. [16] S. Lok esh, P . K. Malarvizhi, M. D. Ramya, P . P arthasa rathy , and C. Gokulnath. An automatic tamil speech recognition system by using bidirectional recurrent neural netwo rk with self-organizing map. Neural Computing and Applications , pages 1–11, 2018. [17] Y. Long, V. Bindschaedler, L. W ang, D. Bu, X. Wang, H. T ang, C. A. Gunter, and K. Chen. Understanding mem- bership inferences on well-generalized learning models. a rXiv prep rint arXiv:1802.04889 , 2018. [18] H. Malik. Securing voice-driven interfaces against fake (cloned) audio attacks. In Proceedings of the 2019 IEEE Conference on Multimedia Information Pro cessing and Re- trieval (MIPR) , pages 512–517. IEEE, 2019. [19] E. McReynolds, S. Hubba rd, T. Lau, A. Saraf, M. Cakmak, and F. Roesner. T oys that listen: A study of pa rents, chil- dren, and Internet-connected toys. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Sys- tems , pages 5197–5207. ACM, 2017. [20] M. Mehrabani, S. Bangalo re, and B. Stern. P ersonalized speech recognition for Internet of Things. In Proceedings of the 2015 IEEE 2nd World Fo r um on Internet of Things (WF-IoT) , pages 369–374. IEEE, 2015. [21] Y. Miao, B. Z. H. Zhao, M. Xue, C. Chen, L. P an, J. Zhang, D. Kaafar, and Y. Xiang. The audio audito r: Pa rticipant-level memb ership inference in voice-based IoT. CCS Workshop of Privacy Preserving Machine Learning , 2019. [22] M. Nasr, R. Shokri, and A. Houmansadr. Machine lea rning with memb ership p rivacy using adversarial regularization. In Pro ceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS) , pages 634– 646, 2018. [23] A. Nautsch, A. Jiménez, A. T reib er, J. Kolberg, C. Jasserand, E. Kindt, H. Delgado, M. T o disco, M. A. Hmani, A. Mtibaa, et al. Preserving p rivacy in sp eaker and speech characterisation. Computer Speech & Language , 58: 441–480, 2019. [24] S. Nick. Amazon ma y give app developers access to Alexa audio recordings, 2017. URL https://www.theverge.com/ 2017/7/12/15960596/amazon- alexa- echo- sp eaker- audio- recordings- developers- data. [25] V. P anay otov, G. Chen, D. Povey , and S. Khudanpur. Lib- rispeech: An ASR corpus based on public domain audio The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 18 bo oks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 5206–5210. IEEE, 2015. [26] J. P ennington, R. So cher, and C. D. Manning. Glove: Global vectors for wo rd representation. In Proceedings of the 2014 Conference on Empirical Metho ds in Natural Language Pro- cessing (EMNLP) , pages 1532–1543, 2014. [27] J. M. Perero-Codosero, J. Antón-Martín, D. T. Merino, E. L. Gonzalo, and L. A. Hernández-Gómez. Exploring op en- source deep learning ASR for sp eech-to-text TV program transcription. In Pro ceedings of the IberSPEECH , pages 262–266, 2018. [28] J. Qian, H. Du, J. Hou, L. Chen, T. Jung, and X. Li. Speech sanitizer: Sp eech content desensitization and voice anonymization. IEEE T ransactions on Dep endable and Se- cure Computing , 2019. [29] M. Ravanelli, T. P arcollet, and Y. Bengio. The Pyto rch- Kaldi sp eech recognition to olkit. In Pro ceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Pro cessing (ICASSP) , pages 6465–6469. IEEE, 2019. [30] A. Rousseau, P . Deléglise, and Y. Esteve. T ed-lium: An au- tomatic sp eech recognition dedicated co rpus. In Pro ceedings of the International Conference on Language Resources and Evaluation (LREC) , pages 125–129, 2012. [31] P . Saleiro, B. Kuester, L. Hinkson, J. London, A. Stevens, A. Anisfeld, K. T. Rodolfa, and R. Ghani. Aequitas: A bias and fairness audit to olkit. a rXiv p reprint arXiv:1811.05577 , 2018. [32] A. Salem, Y. Zhang, M. Humbert, P . Berrang, M. F ritz, and M. Backes. Ml-leaks: Model and data independent mem- bership inference attacks and defenses on machine learning models. In Pro ceedings of the 26th Annual Net wo rk and Distributed System Security Symposium (NDSS) , 2019. [33] M. Sapna. Hey , Alexa, what can you hear? and what will you do with it?, 2018. URL https://www.nytimes.com/ 2018/03/31/business/media/amazon- go ogle- privacy- digital- assistants.html. [34] P . Sa rah. 41% of voice assistant users have concerns about trust and privacy , report finds, 2019. URL https: //techcrunch.com/2019/04/24/41- of- voice- assistant- users- have- concerns- ab out- trust- and- privacy- rep ort- finds/. [35] L. Schönherr, K. K ohls, S. Zeiler, T. Holz, and D. K olossa. Adversa rial attacks against automatic speech recogni- tion systems via psychoacoustic hiding. arXiv prep rint arXiv:1808.05665 , 0(0):1–18, 2018. [36] P . Schulam and S. Saria. Can you trust this prediction? Auditing pointwise reliability after learning. arXiv prep rint arXiv:1901.00403 , 2019. [37] F. H. Shezan, H. Hu, J. Wang, G. W ang, and Y. Tian. Read between the lines: An empirical measurement of sensitive applications of voice p ersonal assistant systems. In Pro ceed- ings of the Web Conference , WWW ’20. A CM, 2020. [38] M. Shok o ohi-Y ekta, Y. Chen, B. Campana, B. Hu, J. Za- karia, and E. Keogh. Discovery of meaningful rules in time series. In Pro ceedings of the 21th ACM SIGKDD Interna- tional Conference on Knowledge Discovery and Data Mining (KDD) , pages 1085–1094. ACM, 2015. [39] R. Shokri, M. S. Song, and V. Shmatik ov. Membership inference attacks against machine learning models. In Pro- ceedings of the 2017 IEEE Symp osium on Security and Pri- vacy (S&P) , pages 3–18. IEEE, 2017. [40] C. Song and V. Shmatikov. A uditing data provenance in text-generation mo dels. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD) , pages 196–206, 2019. [41] L. Song, R. Shokri, and P . Mittal. Privacy risks of securing machine learning mo dels against adversarial examples. In Proceedings of the 2019 ACM SIGSAC Conference on Com- puter and Communications Security (CCS) , pages 241–257, 2019. [42] B. M. L. Srivastava, A. Bellet, M. T ommasi, and E. Vin- cent. Privacy-preserving adversarial representation learning in ASR: Reality or illusion? a rXiv p reprint arXiv:1911.04913 , 2019. [43] D. Sundermann and H. Ney . Vtln-based voice conversion. In Pro ceedings of the 3rd IEEE International Symp osium on Signal Pro cessing and Information T echnology (IEEE Cat. No. 03EX795) , pages 556–559. IEEE, 2003. [44] F. T om, M. Jain, and P . Dey . End-to-end audio replay at- tack detection using deep convolutional netwo rks with atten- tion. In Proceedings of the Interspeech Conference , pages 681–685, 2018. [45] Y.-C. T ung and K. G. Shin. Exploiting sound masking fo r audio privacy in smartphones. In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security , pages 257–268, 2019. [46] F. W eninger, H. Erdogan, W. S, V. E, J. Le Roux, J. R. Hershey , and B. Schuller. Speech enhancement with LSTM recurrent neural netw orks and its application to noise-robust ASR. In Pro ceedings of the International Conference on Latent Variable Analysis and Signal Separation , pages 91– 99. Springer, 2015. [47] S. Wildstrom. Nuance exec on iphone 4s, siri, and the future of sp eech, 2011. URL https://techpinions.com/nuance- exec- on- iphone- 4s- siri- and- the- future- of- speech/3307. [48] M. Xue, G. Magno, E. Cunha, V. Almeida, and K. W. Ro ss. The right to b e fo rgotten in the media: A data-driven study . Proceedings on Privacy Enhancing T echnologies , 2016(4): 389–402, 2016. [49] S. Y eom, I. Giacomelli, M. Fredrikson, and S. Jha. Privacy risk in machine learning: Analyzing the connection to over- fitting. In Pro ceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF) , pages 268–282. IEEE, 2018. [50] N. Zhang, X. Mi, X. F eng, X. Wang, Y. Tian, and F. Qian. Dangerous skills: Understanding and mitigating security risks of voice-controlled third-part y functions on virtual personal assistant systems. In Pro ceedings of the 2019 IEEE Sym- posium on Security and Privacy (S&P) , pages 1381–1396. IEEE, 2019. The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 19 App endices A. Datasets The LibriSpeech sp eech corpus (LibriSp eech) contains 1,000 hours of sp eech audios from audiob o oks which are part of the LibriV ox project [25]. This corpus is famous in training and ev aluating sp eech recognition systems. A t least 1,500 speakers ha ve con tributed their voices to this corpus. W e use 100 hours of clean speech data with 29,877 recordings to train and test our target mo del. 360 hours of clean speech data, including 105,293 recordings, are used for training and testing the shado w models. A d- ditionally , there are 500 hours of noisy data used to train the ASR mo del and to test our auditor’s p erformance in a noisy environmen t. The TIMIT sp eech corpus (TIMIT) is another fa- mous sp eec h corpus used to build ASR systems. This corpus recorded audios from 630 sp eakers across the United States, totaling 6,300 sen tences [9]. In this work, w e use all this data to train and test a target ASR mo del, and then audit this model with our auditor. The TED-LIUM speech corpus (TED) collected audios based on TED T alks for ASR developmen t [30]. This corpus w as built from the TED talks of the IWSL T 2011 Ev aluation Campaign. There are 118 hours of sp eec hes with corresponding transcripts. B. Evaluation Metrics The user-level audio auditor is ev aluated with four met- rics calculated from the confusion matrix, which reports the num b er of true p ositives, true negatives, false p os- itiv es and false negatives: T rue P ositive (TP) , the n umber of records w e predicted as “ member ” are cor- rectly lab eled; T rue Negativ e (TN) , the num b er of records we predicted as “ nonmember ” are correctly la- b eled; F alse P ositive (FP) , the num b er of records w e predicted as “ member ” are incorrectly labeled; F alse Negativ e (FN) , the num b er of records we predicted as “ nonmember ” are incorrectly lab eled. Our ev aluation metrics are derived from the ab ov e-mentioned n umbers. – Accuracy: the p ercen tage of records correctly clas- sified by the auditor mo del. – Precision: the p ercentage of records correctly deter- mined as “ member ” by the auditor mo del among all records determined as “ member ” . – Recall: the p ercentage of all true “ member ” records correctly determined as “ member ” . – F1-score: the harmonic mean of precision and recall. C. ASR Mo dels’ Architectures On the LibriSpeech 360-hour v oice dataset, we build one GR U-ASR mo del with the Pytorch-Kaldi to olkit. That is, we train a five-la yer GRU net work with each hidden la yer of size 550 and one Softmax lay er. W e use tanh as the activ ation function. The optimization function is Ro ot Mean Square Propagation (RMSProp). W e set the learning rate as 0.0004, the drop out rate for eac h GR U la yer 0.2, and the num b er of epo chs of training 24. On the LibriSpeech 360-hour voice dataset, we train another ASR mo del using the Pytorch-Kaldi toolkit. Sp ecifically , it is a four-lay er RNN netw ork with each hidden lay er of size 550 using ReLU as the activ ation function and a Softmax lay er. The optimization func- tion is RMSProp. W e set the learning rate as 0.00032, the drop out rate for each RNN lay er 0.2, and the num- b er ep o chs of training 24. On the LibriSpeech 360-hour voice dataset, we train one hybrid LSTM-ASR mo del. The acoustic model is constructed with a four-la yer LSTM and one Softmax la yer. The size of each hidden LSTM lay er is 550 along with 0.2 drop out rate. The activ ation function is tanh , while the optimization function is RMSProp. The learn- ing rate is 0.0014, and the maximum n umber of training ep o c hs is 24. On the LibriSp eecch 100-hour v oice dataset, we train a hybrid ASR mo del. The acoustic mo del is con- structed with a four-lay er LSTM and one Softmax la yer. Eac h hidden LSTM la yer has 550 neurons along with 0.2 drop out rate. The activ ation function is tanh , while the optimization function is RMSProp. The learning rate is 0.0016, and the maximum n umber of training ep o chs is 24. On the LibriSp eecch 100-hour v oice dataset, we train an end-to-end ASR model. The enco der is con- structed with a five-la yer LSTM with each la yer of size 320 and with 0.1 dropout rate. W e use one la yer lo cation-based attention with 300 cells. The deco der is constructed with a one-la yer LSTM with 320 neurons along with 0.5 drop out rate. The CTC deco ding is en- abled with a w eight of 0.5. The optimization function is A dam. The learning rate is 1.0, and the total num b er of training ep o chs is 24. On the TEDLium dataset, we train a hybrid ASR mo del. The acoustic mo del is constructed with a four- la yer LSTM and one Softmax la yer. Eac h hidden LSTM la yer has 550 neurons along with 0.2 drop out rate. The The Audio Auditor: User-Level Memb ership Inference in Internet of Things Voice Services 20 activ ation function is tanh , while the optimization func- tion is RMSProp. The learning rate is 0.0016, and the n umber of maxim um training ep o chs is 24. On the TIMIT dataset, we train a hybrid ASR mo del. The acoustic mo del is constructed with a four- la yer LSTM and one Softmax la yer. Eac h hidden LSTM la yer has 550 neurons along with 0.2 drop out rate. The activ ation function is tanh , while the optimization func- tion is RMSProp. The learning rate is 0.0016, and the n umber of maxim um training ep o chs is 24. D. Real-Wo rld A udit T est Siri is a virtual assistan t provided b y Apple in their iOS, iPadOs, and macOS. Siri’s natural language in ter- face is used to answ er users’ voice queries and make rec- ommendations [47]. The priv acy p olicy of Apple’s Siri is sho wn in Fig. 11. The user, who is considered as a mem b er user of Siri’s ASR mo del in our setting, has used the targeted iPhone for more than t wo years, fre- quen tly in teracting with Siri, often with the Improv e Siri & Dictation service opted in. As for the mem b er user’s mem b er audio, w e carefully chose fiv e phrases that the user had certainly used when engaging with Siri. Start- ing with “Hey Siri” and phrases from common interac- tions including “Hey Siri”, “What’s the weather today”, “What date is it today”, “Set alarm at 10 o’clo ck”, and “Hey Siri, what’s your name” . As for the mem b er user’s non-mem b er audio, we chose fiv e short phrases in Lib- riSp eec h that the user had nev er used to interact with Siri (e.g. “we ate at man y men’s tables uninvited”). These phrases were recorded using the member user’s v oice along with our mem b er user’s non-mem b er audios. The use of either set of phrases should pro duce an ability to audit as recall that our metho d imitates the user as a whole when auditing the model, irresp ective of whether a sp ecific audio phrase was used to train/update this mo del. Lastly , for the nonmember users’ nonmember audio, the target Siri’s language is English (Australia). Since the LibriSp eech dataset was collected before 2014 and as stated by the iPhone Siri’s priv acy p olicy , users’ data “may b e retained for up to tw o years” . W e con- sider these recordings to not b e part of the Siri train- ing dataset, and th us we hav e nonmember users’ non- mem b er audio. W e further assume that our selected user phrases ab out b o ok reading are nonmem b ers. Fig. 11. The p rivacy policy of Apple’s Siri E. Limitations and F uture Wo rk F urther In vestigation on F eatures. F rom our set of selected features both audio-specific features and fea- tures capturing mo del b ehaviors p erforms well, as ob- serv ed in our results. It remains to be seen if additional audio-sp ecific features w ould sp ecifically aid the task of user-lev el auditing. As there are many potential feature candidates, we consider this as part of future work. A uditing P erformance with V aried Numbers of Queries. In our auditor, we observe that only a lim- ited n umber of queries p er user is necessary to audit the target ASR mo del, esp ecially when the auditor is trained with a limited audios p er user. An interesting observ ation w as that our user-level auditor’s recall p er- formance on more queries p er user declines under the strict black-box access. W e are contin uing our inv esti- gation into why our auditor’s ability to find unautho- rized use of user data v aries in this manner when b eing queried with different n umbers of audios. Mem b er Audio in Siri Auditing. In our setting, we mak e our best effort to ensure member audios are used for training. Ho wev er, in our real-world ev aluation, ev en with the “Improv e Siri & Dictation” setting turned on, with an extended perio d of con tinual use b y our user, we cannot guarantee that member audios of our member user where actually used for training although we are confiden t they ha ve b een included.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment