A nonlinear hidden layer enables actor-critic agents to learn multiple paired association navigation
Navigation to multiple cued reward locations has been increasingly used to study rodent learning. Though deep reinforcement learning agents have been shown to be able to learn the task, they are not biologically plausible. Biologically plausible classic actor-critic agents have been shown to learn to navigate to single reward locations, but which biologically plausible agents are able to learn multiple cue-reward location tasks has remained unclear. In this computational study, we show versions of classic agents that learn to navigate to a single reward location, and adapt to reward location displacement, but are not able to learn multiple paired association navigation. The limitation is overcome by an agent in which place cell and cue information are first processed by a feedforward nonlinear hidden layer with synapses to the actor and critic subject to temporal difference error-modulated plasticity. Faster learning is obtained when the feedforward layer is replaced by a recurrent reservoir network.
💡 Research Summary
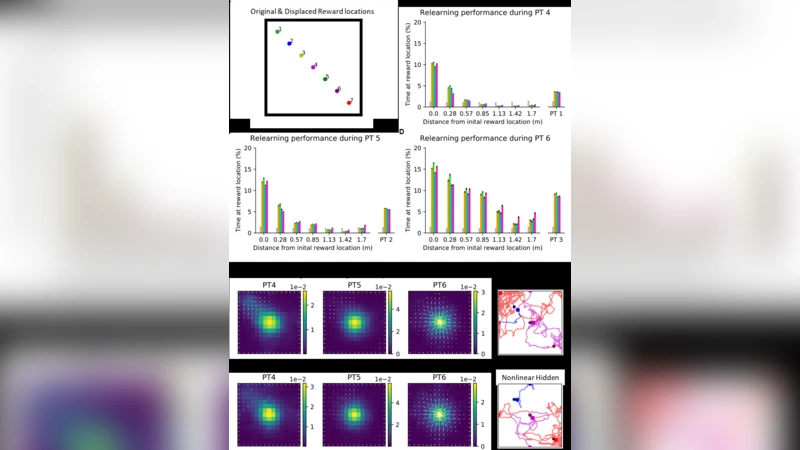
The paper investigates how biologically plausible reinforcement‑learning agents can acquire the ability to navigate to several cue‑reward locations, a task that rodents readily perform but that has proved challenging for classic actor‑critic models. The authors first implement a conventional actor‑critic agent whose inputs consist of place‑cell activations and visual cue signals. Learning proceeds via temporal‑difference (TD) error‑modulated plasticity applied to the linear connections feeding both the actor (policy) and the critic (value). This baseline agent successfully learns a single reward location and can adapt when that location is displaced, but it fails to acquire multiple paired associations: when two or more cue‑reward pairs are presented simultaneously, the policy collapses into a mixed, ineffective behavior. The authors attribute this failure to a representational bottleneck: linear mappings cannot separate the overlapping input patterns generated by different cue‑reward pairings.
To overcome this limitation, the study introduces a nonlinear hidden layer that processes the place‑cell and cue inputs before they reach the actor and critic. The hidden layer consists of a feed‑forward network with rectified linear (ReLU) units and fixed random weights; its role is to perform a nonlinear transformation that expands the input space into a higher‑dimensional representation where each cue‑reward pair becomes linearly separable. The actor and critic then receive this transformed signal, and their synaptic weights are still updated by the TD error, preserving biological plausibility (e.g., dopamine‑mediated plasticity). With this architecture—dubbed the Nonlinear Hidden‑Actor‑Critic—the agent learns multiple paired associations, quickly converges to a high success rate (>90 %), and retains the ability to re‑learn when reward locations shift.
The authors further replace the static feed‑forward hidden layer with a recurrent reservoir network (a form of reservoir computing). The reservoir contains randomly connected, sparsely wired recurrent units whose dynamics generate rich temporal patterns in response to the same place‑cell and cue inputs. Linear read‑out weights from the reservoir to the actor and critic are trained using the same TD‑error rule. This Reservoir‑Actor‑Critic model accelerates learning even more, reducing the number of trials needed for convergence by roughly 30 % compared with the feed‑forward hidden layer, and it shows greater robustness to abrupt changes in reward location. The recurrent dynamics effectively encode the temporal structure of the navigation task, suggesting a computational parallel to hippocampal‑cortical loops that support sequence learning in the brain.
Beyond performance metrics, the paper discusses the neurobiological relevance of its findings. The nonlinear hidden transformation mirrors the pattern separation performed by dentate gyrus‑CA3 circuitry, while the reservoir’s recurrent dynamics resemble the temporally extended activity patterns observed in hippocampal‑prefrontal networks during spatial decision‑making. Moreover, the reliance on TD‑error‑driven synaptic updates aligns with dopaminergic prediction‑error signaling known to modulate plasticity in striatal and cortical circuits. Consequently, the study provides a concrete example of how modest architectural augmentations—nonlinear preprocessing and recurrent dynamics—can endow classic, biologically plausible reinforcement‑learning agents with the capacity to solve complex multi‑association navigation tasks. The authors suggest future work should compare model activity with in‑vivo neural recordings, explore optimal reservoir architectures (e.g., sparsity, spectral radius), and extend the framework to more demanding tasks such as hierarchical planning or continual learning.