Front Contribution instead of Back Propagation
Deep Learning’s outstanding track record across several domains has stemmed from the use of error backpropagation (BP). Several studies, however, have shown that it is impossible to execute BP in a real brain. Also, BP still serves as an important and unsolved bottleneck for memory usage and speed. We propose a simple, novel algorithm, the Front-Contribution algorithm, as a compact alternative to BP. The contributions of all weights with respect to the final layer weights are calculated before training commences and all the contributions are appended to weights of the final layer, i.e., the effective final layer weights are a non-linear function of themselves. Our algorithm then essentially collapses the network, precluding the necessity for weight updation of all weights not in the final layer. This reduction in parameters results in lower memory usage and higher training speed. We show that our algorithm produces the exact same output as BP, in contrast to several recently proposed algorithms approximating BP. Our preliminary experiments demonstrate the efficacy of the proposed algorithm. Our work provides a foundation to effectively utilize these presently under-explored “front contributions”, and serves to inspire the next generation of training algorithms.
💡 Research Summary
The paper “Front Contribution instead of Back Propagation” proposes a radical alternative to the standard error‑backpropagation (BP) algorithm that underlies modern deep learning. The authors argue that BP is biologically implausible, memory‑intensive, and a computational bottleneck, and they introduce the “Front‑Contribution” algorithm as a compact replacement.
The core idea is to pre‑compute, before training begins, how each weight in the earlier layers contributes to the final‑layer weights. These contributions are then added as non‑linear correction terms to the final layer’s parameters, effectively collapsing the entire network into a single layer whose weights are a function of the original final‑layer weights plus the accumulated contributions. In this collapsed network, only the final layer (now augmented with the correction terms) is updated during training; all earlier layers are frozen. The authors claim that this yields exactly the same output as a network trained with conventional BP, while dramatically reducing memory usage and training time.
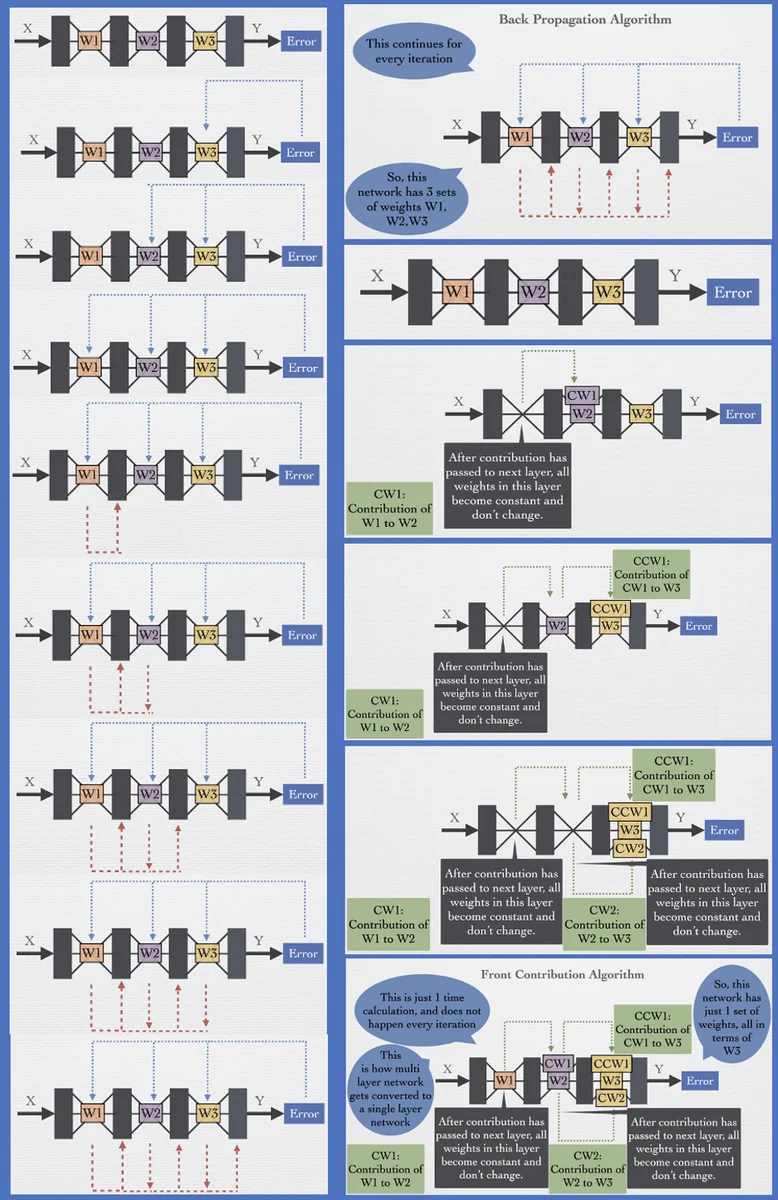
In the “Method” section the authors formalize the network as Y = f(X, W₁,…,Wₙ). Using the chain rule they note that the gradient ΔWᵢ for any layer i depends on the weights of all subsequent layers (Wᵢ₊₁,…,Wₙ). They argue that the first layer W₁ is not an independent basis vector because its update can be expressed entirely through the later layers. To compensate for freezing W₁, they introduce a “compensation weight” p that is added to the weights of the second layer (W₂). The compensation p must be a non‑linear function of W₂ (and ultimately of all downstream weights) because it must reproduce the effect of the omitted update of W₁.
A concrete two‑layer example with ReLU activations is worked out. The intermediate activations v₁ and v₂ are treated as constants when W₁ is frozen, and the output equation Y = v₁·w₅ + v₂·w₆ is rewritten as Y = v_c₁·(w₅ + p) + v_c₂·(w₆ + q). By equating the back‑propagated update with the “contribution” update, expressions for p and q are derived that involve the input vector, the current weights, and the loss gradient dE/dY. The authors then generalize these expressions to an arbitrary iteration n, introducing cumulative compensation terms Pₙ and Qₙ. For multiple inputs they note that the entire input sequence must be stored to compute P and Q, which already hints at a substantial memory requirement.
The authors claim that by repeatedly applying this compensation step, any fully‑connected network of depth n can be reduced to depth n‑1, then n‑2, and so on, until only a single “collapsed” layer remains. They refer to this recursive reduction as the Front‑Contribution algorithm. They assert that the algorithm’s time complexity is O(1) because the transformation from the original network to the collapsed one is a one‑time calculation, even though the derived expressions are highly non‑linear and data‑dependent.
In the conclusion they list several purported advantages: (i) a single pre‑computation step yields the non‑linear final weights; (ii) the collapsed network contains far fewer parameters, leading to drastic GPU memory savings; (iii) training time is reduced because back‑propagation is eliminated; (iv) the final non‑linear weight expression (e.g., Wₙ = Wₙ + k₁W₃ₙ + k₂W₅ₙ + …) may provide an interpretable hierarchy of learned features; (v) the collapsed network can be “re‑expanded” to inspect intermediate activations if desired; and (vi) the derivation can be extended to convolutional, recurrent, and transformer architectures.
Critical assessment
While the notion of moving the credit‑assignment computation forward rather than backward is conceptually interesting, the paper’s claims do not hold up under scrutiny. First, the compensation terms p, q, Pₙ, Qₙ are derived from the same gradients that BP would compute; the algorithm therefore does not eliminate the need to evaluate those gradients, it merely reshapes them. Computing the non‑linear corrections requires access to every training sample (the authors explicitly state that the whole input sequence must be stored) and must be recomputed at each iteration because the corrections depend on the current weights and loss gradients. This contradicts the claim of O(1) complexity and suggests a higher, possibly prohibitive, computational and memory cost.
Second, the paper provides no empirical evidence beyond a vague “preliminary experiment”. There are no benchmark datasets, no comparison with standard optimizers (SGD, Adam), and no ablation studies to quantify memory or speed gains. Without such validation, the assertion that the method yields exactly the same output as BP remains unproven.
Third, the theoretical justification that earlier layers are “not part of the system basis” is flawed. Even if a linear stack of layers can be mathematically collapsed, the presence of non‑linear activations (ReLU, sigmoid, etc.) prevents an exact algebraic reduction; the authors’ workaround introduces highly non‑linear correction terms that essentially re‑encode the same non‑linear transformations that BP would have performed.
Fourth, the biological motivation is weak. Recent neuroscience research has proposed plausible approximations to BP (e.g., predictive coding, dendritic error propagation). Claiming that BP is impossible in the brain does not automatically make the Front‑Contribution algorithm biologically realistic; the algorithm still relies on global loss gradients that would require a “learning channel” not observed in biology.
Finally, the paper’s presentation suffers from numerous typographical errors, missing equation numbers, and an incomplete supplementary section, which further undermines confidence in the rigor of the work.
In summary, the Front‑Contribution algorithm offers an intriguing perspective on forward‑looking credit assignment, but the current manuscript lacks mathematical rigor, realistic computational analysis, and empirical validation. As presented, it does not constitute a practical replacement for back‑propagation in modern deep learning pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment