Principal Component Analysis: A Natural Approach to Data Exploration
Principal component analysis (PCA) is often used for analyzing data in the most diverse areas. In this work, we report an integrated approach to several theoretical and practical aspects of PCA. We start by providing, in an intuitive and accessible manner, the basic principles underlying PCA and its applications. Next, we present a systematic, though no exclusive, survey of some representative works illustrating the potential of PCA applications to a wide range of areas. An experimental investigation of the ability of PCA for variance explanation and dimensionality reduction is also developed, which confirms the efficacy of PCA and also shows that standardizing or not the original data can have important effects on the obtained results. Overall, we believe the several covered issues can assist researchers from the most diverse areas in using and interpreting PCA.
💡 Research Summary
The paper presents a comprehensive treatment of Principal Component Analysis (PCA) aimed at both newcomers and seasoned practitioners across a wide spectrum of scientific and engineering domains. It begins with a historical motivation, emphasizing the exponential growth of data (“data deluge”) and the consequent need for methods that can summarize, visualize, and extract the most informative structures from high‑dimensional datasets. PCA is introduced as a linear transformation that rotates the original coordinate system so that the first axis captures the maximum possible variance, the second captures the next largest variance, and so on. This geometric intuition is illustrated with a simple two‑dimensional example involving bean diameter and square‑root of area, showing how an elongated cloud of points can be aligned with a principal axis and subsequently reduced in dimensionality.
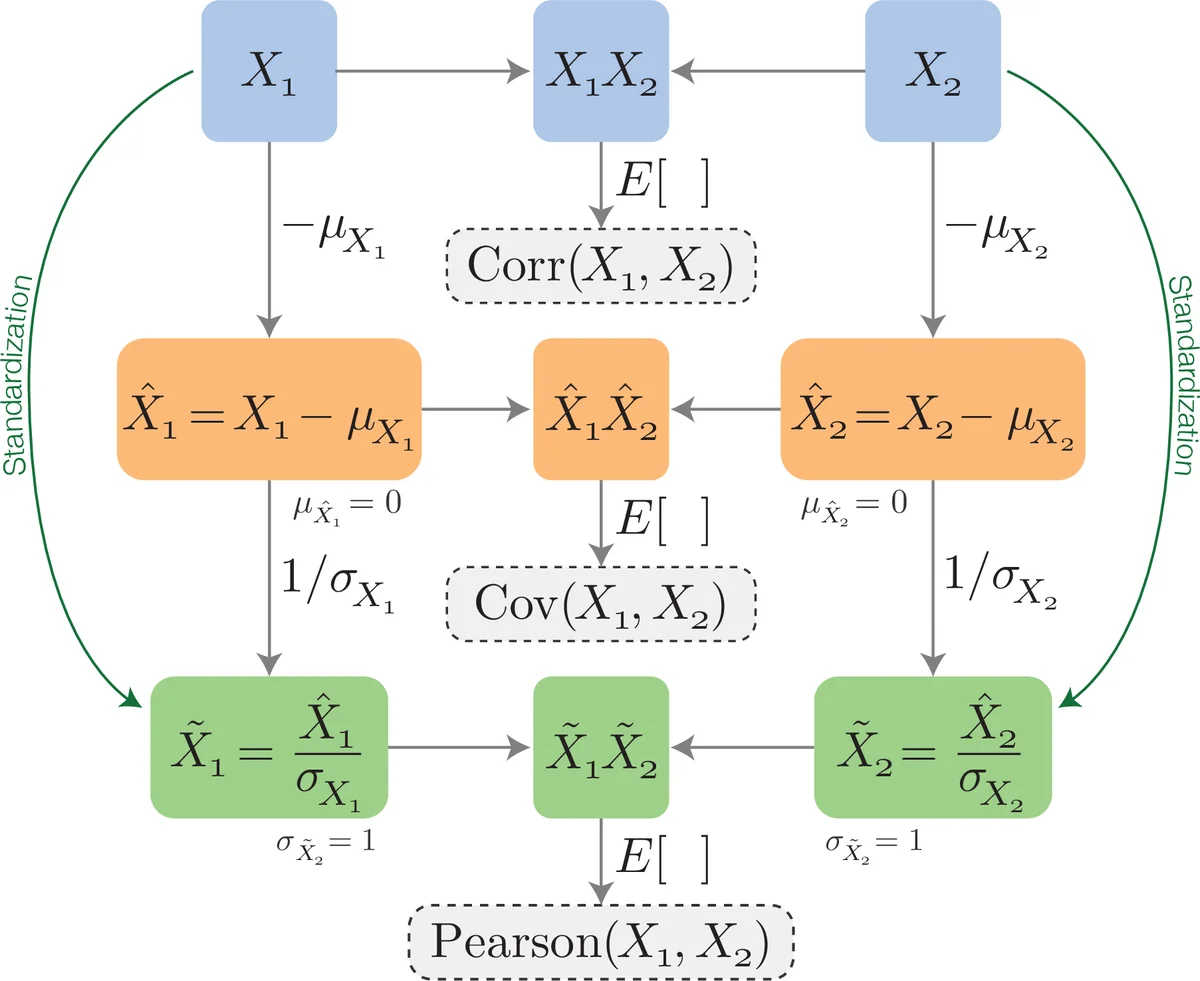
The theoretical core of the manuscript revisits correlation, covariance, and Pearson’s correlation coefficient, establishing the statistical foundations for PCA. The authors detail the steps of centering (subtracting the mean) and scaling (dividing by the standard deviation), distinguishing between generic “normalization” and the specific statistical operation called “standardization.” They then derive the covariance matrix, explain its eigendecomposition, and prove that the eigenvectors associated with the largest eigenvalues correspond to directions of maximal data spread. The paper also discusses the sign ambiguity of eigenvectors, the concept of PCA axis direction, and the role of rotation in interpreting loadings and biplots.
A central contribution is the systematic comparison of standardized versus non‑standardized data pipelines. By applying PCA to a curated collection of publicly available datasets spanning biology, medicine, neuroscience, psychology, sports, chemistry, materials science, engineering, safety, computer science, deep learning, economics, scientometrics, physics, astronomy, geography, weather, agriculture, tourism, arts, history, social sciences, and linguistics, the authors quantify how scaling influences the cumulative explained variance, reconstruction error, and visual interpretability of biplots. The empirical results consistently show that a small number of components (typically 2–3) can capture 80–95 % of total variance, and that standardization generally yields more balanced eigenvalue spectra, higher compression efficiency, and more stable component selection across heterogeneous domains.
Beyond PCA alone, the manuscript positions PCA as a preprocessing step for more computationally intensive projection methods such as Linear Discriminant Analysis (LDA), Independent Component Analysis (ICA), and entropy‑based techniques. The authors argue that applying PCA first reduces dimensionality, thereby lowering computational cost and improving statistical significance for subsequent analyses. However, they caution that PCA optimizes variance, not class separability, so it should be complemented with discriminative methods when the primary goal is classification.
The “Review of PCA Applications” section provides a concise yet detailed survey of representative studies in each listed field, highlighting the specific data types (e.g., gene expression matrices, medical imaging voxels, EEG time‑frequency representations, sports performance metrics, spectroscopic fingerprints, sensor networks) and the practical outcomes achieved through PCA (feature reduction, noise filtering, visualization, outlier detection). This survey serves as a ready‑to‑use reference for researchers seeking to adopt PCA in their own work.
In the experimental study, the authors describe dataset selection criteria, preprocessing choices, and evaluation metrics. They present results in terms of explained variance curves, reconstruction error plots, and illustrative biplots that compare standardized and raw data. The discussion interprets these findings, noting that while standardization often improves component interpretability, certain domains with inherently meaningful physical units may benefit from preserving original scales.
The concluding remarks synthesize the insights: PCA remains a powerful, mathematically transparent tool for exploratory data analysis, capable of simultaneous dimensionality reduction, decorrelation, and visualization. Proper handling of scaling, awareness of PCA’s variance‑centric objective, and strategic integration with complementary methods are essential for maximizing its utility. The authors suggest future directions such as kernel PCA, deep learning‑based autoencoders, and interactive visualization platforms to extend PCA’s applicability to nonlinear and large‑scale scenarios. Overall, the paper delivers a well‑structured, accessible, and practically oriented guide that can assist researchers from diverse backgrounds in effectively employing and interpreting PCA.
Comments & Academic Discussion
Loading comments...
Leave a Comment