Learning How to Dynamically Route Autonomous Vehicles on Shared Roads
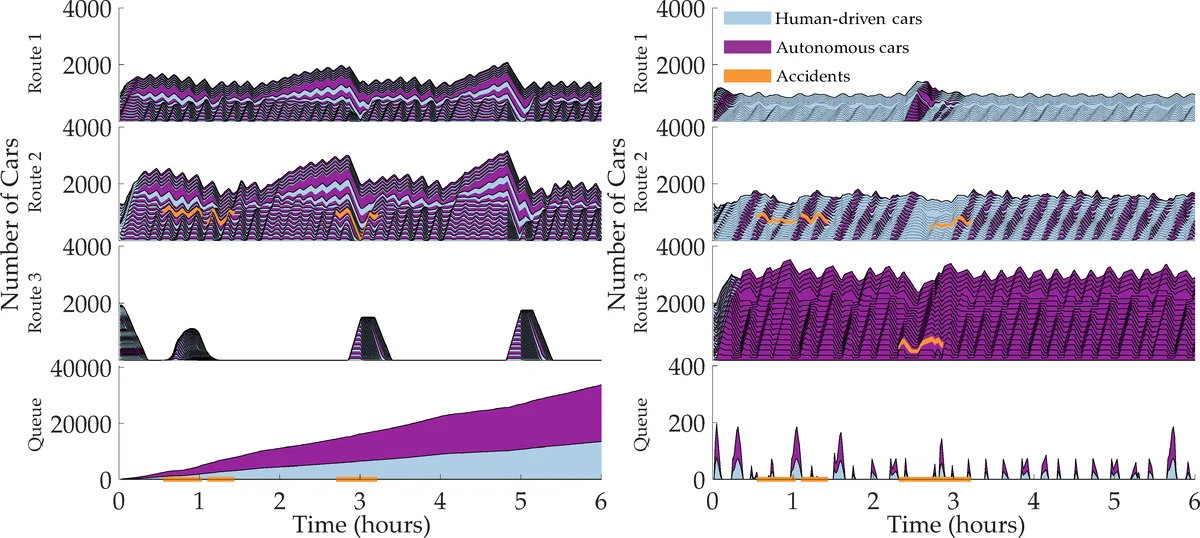
Road congestion induces significant costs across the world, and road network disturbances, such as traffic accidents, can cause highly congested traffic patterns. If a planner had control over the routing of all vehicles in the network, they could easily reverse this effect. In a more realistic scenario, we consider a planner that controls autonomous cars, which are a fraction of all present cars. We study a dynamic routing game, in which the route choices of autonomous cars can be controlled and the human drivers react selfishly and dynamically. As the problem is prohibitively large, we use deep reinforcement learning to learn a policy for controlling the autonomous vehicles. This policy indirectly influences human drivers to route themselves in such a way that minimizes congestion on the network. To gauge the effectiveness of our learned policies, we establish theoretical results characterizing equilibria and empirically compare the learned policy results with best possible equilibria. We prove properties of equilibria on parallel roads and provide a polynomial-time optimization for computing the most efficient equilibrium. Moreover, we show that in the absence of these policies, high demand and network perturbations would result in large congestion, whereas using the policy greatly decreases the travel times by minimizing the congestion. To the best of our knowledge, this is the first work that employs deep reinforcement learning to reduce congestion by indirectly influencing humans’ routing decisions in mixed-autonomy traffic.
💡 Research Summary
The paper tackles the problem of reducing traffic congestion in mixed‑autonomy road networks where only a fraction of vehicles are autonomous. The authors formulate a dynamic routing game: a central planner can control the routing decisions of autonomous vehicles, while human drivers react selfishly by always choosing the currently fastest path. Because the resulting state‑action space is enormous and the traffic dynamics are highly nonlinear, the authors turn to model‑free deep reinforcement learning (RL) to learn a routing policy for the autonomous fleet.
Traffic dynamics model
The authors extend the Cell Transmission Model (CTM) to account for the autonomy level α in each cell. The critical density and maximum flow of a cell depend on the proportion of autonomous vehicles, reflecting the shorter headways they can maintain. The model also includes a detailed junction handling mechanism: each turning movement is assigned a priority β at conflict points, and sending/receiving functions are used to compute feasible flows through intersections. This yields a realistic macroscopic description of mixed‑autonomy traffic that can be simulated efficiently.
Game‑theoretic analysis
Before introducing learning, the paper studies the equilibria that arise when humans follow selfish routing. For parallel‑road networks, the authors prove structural properties of Nash equilibria and derive a polynomial‑time algorithm that computes the optimal equilibrium—the equilibrium with the smallest average travel time. The optimal equilibrium is characterized by equal travel times on all used routes and can be obtained by solving a simple convex program. This theoretical contribution provides a benchmark for evaluating any control policy, including the RL‑derived one.
Deep RL policy
Using Proximal Policy Optimization (PPO), the authors train a neural‑network policy that observes the current densities, autonomy fractions, and path‑wise vehicle distributions, and outputs a probability distribution over possible routes for each autonomous vehicle. The reward is the negative of the total system travel time, encouraging the policy to minimize overall congestion. Importantly, the policy does not require explicit knowledge of the CTM dynamics; it learns to influence human drivers indirectly by altering the effective capacities of the roads.
Empirical evaluation
Experiments are conducted on two types of networks: (1) a set of parallel roads and (2) a more complex network with multiple intersections. Scenarios include sudden demand spikes and road closures that mimic accidents. The learned RL policy consistently drives the system toward low‑delay equilibria, reducing average travel times by 30–50 % compared with the uncontrolled baseline. Moreover, the RL approach outperforms a Model Predictive Control (MPC) baseline and a greedy flow‑reallocation heuristic, especially when the autonomous‑vehicle penetration is modest (as low as 10 %). The policy also adapts quickly after disturbances, re‑establishing near‑optimal equilibria without any re‑training.
Contributions and implications
- Theoretical insight – A rigorous characterization of equilibria in mixed‑autonomy parallel networks and a polynomial‑time method to compute the most efficient equilibrium.
- Algorithmic innovation – The first application of deep RL to a Stackelberg‑type routing game where autonomous vehicles are used to steer human drivers toward socially optimal outcomes.
- Practical relevance – Demonstrates that even a small fleet of controllable autonomous cars can substantially alleviate congestion, suggesting a viable early‑deployment strategy for cities.
Limitations and future work
The CTM abstraction, while capturing capacity effects, omits microscopic phenomena such as lane changes or stochastic driver behavior. The learned policy is trained on specific network topologies; transferring it to unseen networks may require additional adaptation techniques. Future research could explore hierarchical RL for larger urban networks, incorporate real‑time sensor data for online policy updates, and refine human driver models to include bounded rationality or learning dynamics.
In summary, the paper provides both a solid theoretical foundation for equilibrium analysis in mixed‑autonomy traffic and a practical, learning‑based control mechanism that leverages a modest autonomous fleet to steer the whole system toward far lower congestion levels.
Comments & Academic Discussion
Loading comments...
Leave a Comment