Towards Enhancing Fault Tolerance in Neural Networks
Deep Learning Accelerators are prone to faults which manifest in the form of errors in Neural Networks. Fault Tolerance in Neural Networks is crucial in real-time safety critical applications requiring computation for long durations. Neural Networks with high regularisation exhibit superior fault tolerance, however, at the cost of classification accuracy. In the view of difference in functionality, a Neural Network is modelled as two separate networks, i.e, the Feature Extractor with unsupervised learning objective and the Classifier with a supervised learning objective. Traditional approaches of training the entire network using a single supervised learning objective is insufficient to achieve the objectives of the individual components optimally. In this work, a novel multi-criteria objective function, combining unsupervised training of the Feature Extractor followed by supervised tuning with Classifier Network is proposed. The unsupervised training solves two games simultaneously in the presence of adversary neural networks with conflicting objectives to the Feature Extractor. The first game minimises the loss in reconstructing the input image for indistinguishability given the features from the Extractor, in the presence of a generative decoder. The second game solves a minimax constraint optimisation for distributional smoothening of feature space to match a prior distribution, in the presence of a Discriminator network. The resultant strongly regularised Feature Extractor is combined with the Classifier Network for supervised fine-tuning. The proposed Adversarial Fault Tolerant Neural Network Training is scalable to large networks and is independent of the architecture. The evaluation on benchmarking datasets: FashionMNIST and CIFAR10, indicates that the resultant networks have high accuracy with superior tolerance to stuck at “0” faults compared to widely used regularisers.
💡 Research Summary
The paper addresses the vulnerability of deep learning accelerators and neuromorphic hardware to permanent “stuck‑at‑0” faults that can appear in both weights and activations. Recognising that a neural network can be naturally divided into a feature extractor (FE) with an unsupervised learning goal and a fully‑connected classifier (FCC) with a supervised goal, the authors propose a two‑phase training framework that treats these components separately.
Phase I – Unsupervised Regularisation of the Feature Extractor
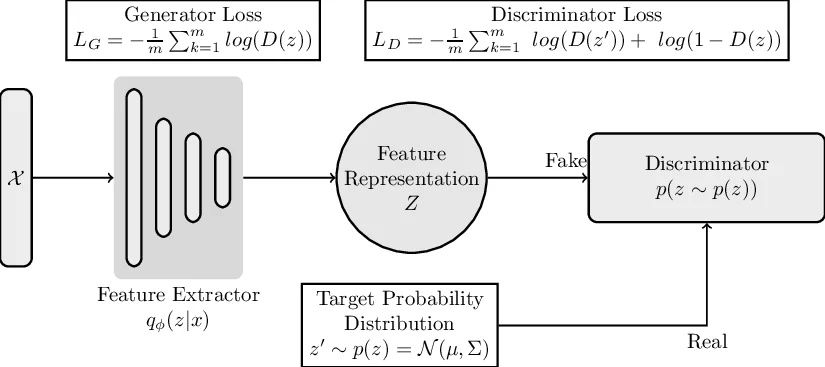
The FE is trained simultaneously in two adversarial games.
- Reconstruction Game: A generative decoder receives the FE’s latent features and attempts to reconstruct the original image. The FE and decoder are jointly optimized to minimise reconstruction loss, forcing the latent representation to retain sufficient information for indistinguishability between original and reconstructed inputs.
- Distribution‑Matching Game: A binary discriminator tries to distinguish FE‑generated latent samples from samples drawn from a prior Gaussian distribution. The FE minimizes a minimax objective that pushes its latent distribution toward the Gaussian prior, thereby smoothing the feature space.
These two games together act as a strong regulariser: the reconstruction game preserves semantic content, while the distribution‑matching game forces the latent vectors to be uniformly spread, reducing the variance of learned parameters. Empirical analysis shows that a regularised model’s weight distribution has a standard deviation of ~0.05 compared with ~0.45 for an over‑fitted, unregularised counterpart, indicating that regularisation distributes importance more evenly across parameters.
Phase II – Supervised Fine‑Tuning of the Classifier
After Phase I, the FE is frozen (or lightly fine‑tuned) and attached to an FCC. The FCC is trained with the standard cross‑entropy loss on the target labels. Because the FE already provides robust, well‑regularised features, the classifier can achieve high accuracy without needing additional regularisation.
Experimental Evaluation
Four network architectures of varying depth (from a simple MLP to a ResNet‑style CNN) are evaluated on FashionMNIST and CIFAR‑10. The proposed method is compared against L1 (Lasso), L2 (Tikhonov) regularisation, and an unregularised baseline. Fault injection is performed by randomly masking a given percentage (0 %–30 %) of weights and activations to simulate stuck‑at‑0 faults, both at the level of fully‑connected parameters and convolutional filters.
Key findings:
- Test accuracy of the proposed models matches or slightly exceeds that of L1/L2‑regularised networks.
- Generalisation error (difference between training and test accuracy) is markedly lower, confirming reduced over‑fitting.
- Under increasing fault rates, the proposed models suffer far smaller accuracy drops; for example, at a 20 % fault rate the accuracy loss is 2–5 % lower than that of L1/L2 baselines.
- The advantage holds for convolutional filter faults as well, demonstrating that the regularisation effect propagates through the entire architecture.
Contributions
- A clear functional decomposition of a neural network into FE and FCC, each trained with objectives aligned to its role.
- Simultaneous optimisation of two adversarial games that provide a strong, architecture‑agnostic regulariser for the FE.
- Empirical evidence linking reduced parameter variance to improved fault tolerance, introducing “generalisation error” as a practical metric for comparing fault‑tolerant designs.
- Demonstration of scalability across multiple architectures and datasets.
Limitations and Future Work
The study focuses exclusively on permanent stuck‑at‑0 faults; other fault types such as bit‑flips, timing errors, or transient glitches are not addressed. Hardware‑level cost (energy, area, latency) of the additional adversarial components is not quantified. Future research directions include extending the framework to other fault models, analysing convergence properties of the dual‑game optimisation, and integrating the method with large‑scale pretrained models (e.g., Vision Transformers) or on‑chip fault‑aware training pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment