Data-driven computation of invariant sets of discrete time-invariant black-box systems
We consider the problem of computing the maximal invariant set of discrete-time black-box nonlinear systems without analytic dynamical models. Under the assumption that the system is asymptotically stable, the maximal invariant set coincides with the domain of attraction. A data-driven framework relying on the observation of trajectories is proposed to compute almost-invariant sets, which are invariant almost everywhere except a small subset. Based on these observations, scenario optimization problems are formulated and solved. We show that probabilistic invariance guarantees on the almost-invariant sets can be established. To get explicit expressions of such sets, a set identification procedure is designed with a verification step that provides inner and outer approximations in a probabilistic sense. The proposed data-driven framework is illustrated by several numerical examples.
💡 Research Summary
The paper tackles the challenging problem of computing the maximal invariant set (equivalently, the domain of attraction) for discrete‑time nonlinear systems when no analytic model of the dynamics is available. Assuming the system is asymptotically stable on a compact constraint set X containing the origin, the maximal invariant set O∞ coincides with the set of all initial states whose trajectories remain in X for all future times. Classical algorithms rely on explicit knowledge of the map f, which is unavailable for black‑box systems, so the authors introduce a data‑driven framework that works solely with simulated or measured trajectories.
The key conceptual tool is the notion of an ε‑almost‑invariant set: a set Z⊆X for which the probability (with respect to a chosen sampling distribution P) that a point in Z is mapped outside Z by f is at most ε. This relaxes the strict invariance requirement and makes it amenable to statistical verification. The authors then formulate scenario‑optimization problems based on a finite number N of i.i.d. initial conditions drawn from P. For each horizon k, they estimate the empirical measure θk(ωN)= (1/N)∑i 1_{Ok}(xi) where Ok is the set of states that stay inside X for at least k steps. The sequence θk is non‑increasing; the first index \bar t(ωN) where θk=θk+1 serves as a data‑driven estimate of the invariance horizon.
Theorem 1 provides a probabilistic bound: for any ε∈(0,1] the probability that the true violation measure S(\bar t) exceeds ε is bounded by (1/ε)(1−ε)^N. Consequently, to guarantee an ε‑almost‑invariant set with confidence 1−β, it suffices to sample at least ⌈ln(εβ)/ln(1−ε)⌉ initial conditions. This yields an explicit sample‑complexity formula rarely seen in invariant‑set literature.
To tighten the bound, the authors introduce the first‑exit time t*(x)=min{t | φ(t,x)∉X} and define t*(ωN)=max_i t*(xi). Lemma 1 shows that t*(ωN)≥\bar t(ωN) and that the equality θ_{t*}=θ_{t*+1} holds. Theorem 2 then proves a sharper bound P_N{S(t*)≥ε}≤(1−ε)^N, eliminating the factor 1/ε and demonstrating that the probability of a large violation decays exponentially with N. This improvement is especially valuable for small ε and high‑confidence regimes.
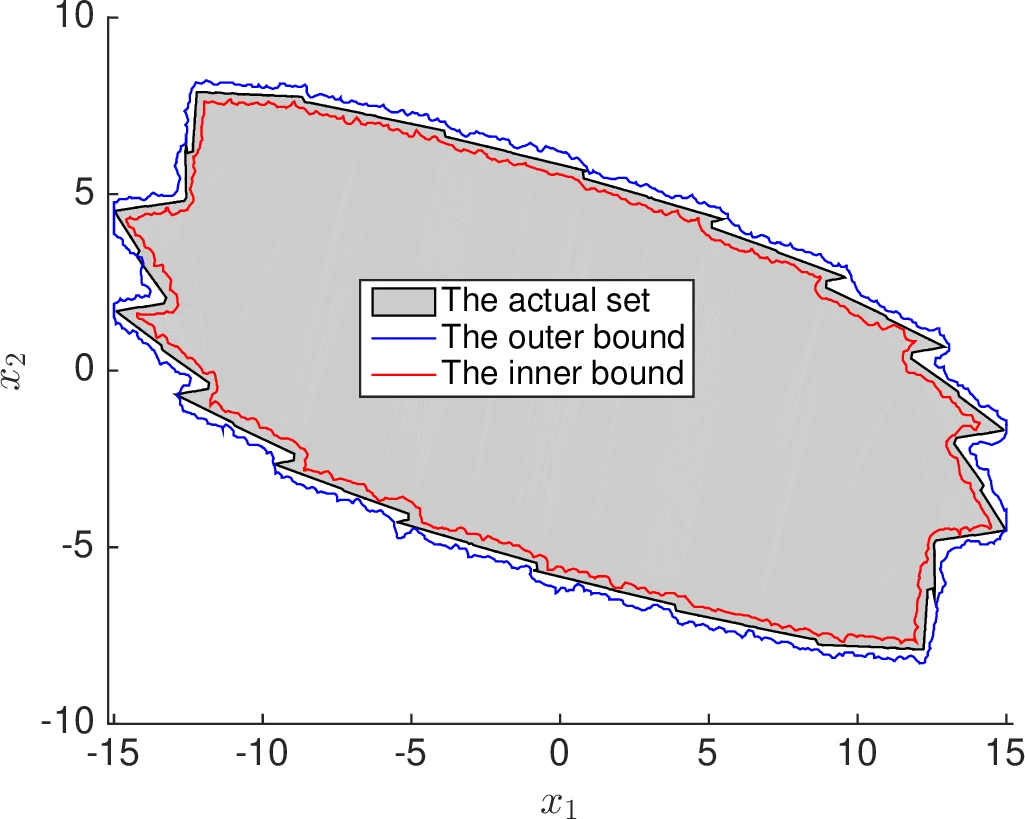
Having identified an implicit almost‑invariant set via the horizon estimate, the authors address the need for an explicit representation. They propose a set‑identification procedure that uses a larger collection of short trajectories to construct inner and outer approximations. The state space is discretized (e.g., via a grid or polyhedral partition), and for each cell the empirical occupancy θk is computed. Cells with θk≥1−ε form the inner approximation O_in, while cells with θk>0 form the outer approximation O_out. By construction, with probability at least 1−β, O_in⊆O∞⊆O_out, and the gap can be made arbitrarily small by refining the grid or increasing N.
Complexity analysis shows that the long‑trajectory phase costs O(N·L) (where L is the horizon length) and the short‑trajectory identification phase costs O(N·M) with M the number of grid cells. Both phases are polynomial and scalable, contrasting with many model‑based methods that require solving large semidefinite programs or performing exhaustive set‑propagation.
The paper validates the methodology on several numerical examples: (i) a 2‑D nonlinear system where the exact maximal invariant set is known, (ii) a 4‑D robotic arm model illustrating the method’s ability to handle higher dimensions, and (iii) a switched nonlinear system for which traditional identification is NP‑hard. In each case, the empirical violation probabilities match the theoretical bounds, and the inner/outer approximations tightly enclose the true invariant set.
In conclusion, the authors deliver a rigorous, probabilistically guaranteed, data‑driven approach to invariant‑set computation for black‑box discrete‑time nonlinear systems. The work bridges scenario optimization, almost‑invariant set theory, and practical set identification, opening avenues for safety verification, controller synthesis, and robust analysis without explicit models. Future directions suggested include adaptive sampling, extensions to continuous‑time dynamics, and integration with control design frameworks.
Comments & Academic Discussion
Loading comments...
Leave a Comment