A note on using performance and data profilesfor training algorithms
It is shown how to use the performance and data profile benchmarking tools to improve algorithms’ performance. An illustration for the BFO derivative-free optimizer suggests that the obtained gains are potentially significant.
💡 Research Summary
**
The paper introduces a novel methodology for training algorithmic parameters by directly employing performance profiles and data profiles as objective functions, rather than the traditional average‑or‑worst‑case performance measures. The authors focus on the Bacterial Foraging Optimizer (BFO), a derivative‑free optimization algorithm that already contains an internal mechanism for parameter selection. They first recall the classical training formulations: (1) minimizing the average number of objective‑function evaluations across a benchmark set, and (2) minimizing a robust version that considers the worst performance within a local perturbation box around the parameter vector. Both formulations require solving a (generally non‑convex) optimization problem over the parameter space, subject to bound constraints.
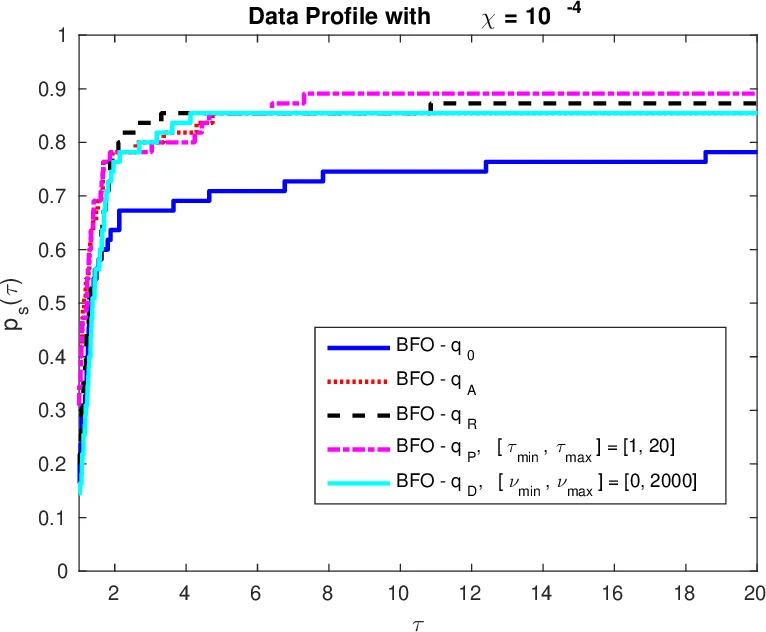
The core contribution is the definition of two new training criteria based on the widely used benchmarking tools of performance profiles (as introduced by Dolan and Moré) and data profiles (as introduced by Moré and Wild). A performance profile (p_s(\tau)) measures, for a solver (s), the fraction of benchmark problems solved within a factor (\tau) of the best known solver. A data profile (d_s(\nu)) measures the fraction of problems solved within a computational budget (\nu) (scaled by problem dimension). The authors propose to maximize the area under these staircase‑shaped curves:
- Data‑profile training: (\phi_D^P(q)=\int_{\nu_{\min}}^{\nu_{\max}} d_{s_q}(\nu),d\nu). Here (s_q) denotes BFO instantiated with parameter vector (q). The integration limits (
Comments & Academic Discussion
Loading comments...
Leave a Comment