Collective Learning
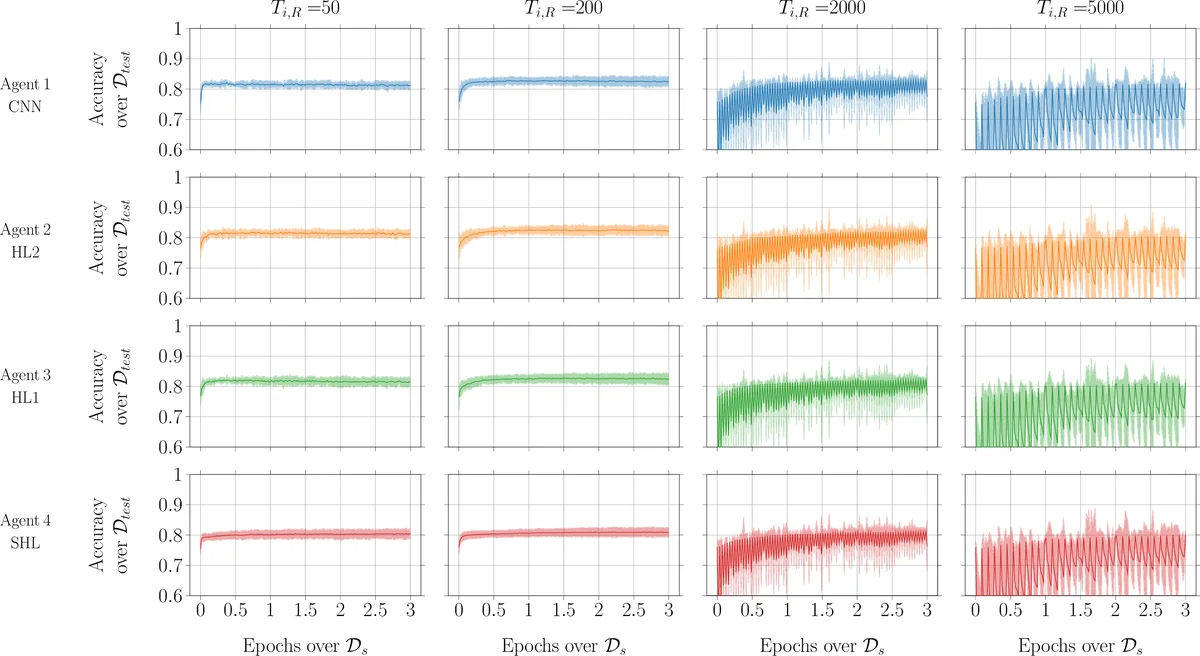
In this paper, we introduce the concept of collective learning (CL) which exploits the notion of collective intelligence in the field of distributed semi-supervised learning. The proposed framework draws inspiration from the learning behavior of human beings, who alternate phases involving collaboration, confrontation and exchange of views with other consisting of studying and learning on their own. On this regard, CL comprises two main phases: a self-training phase in which learning is performed on local private (labeled) data only and a collective training phase in which proxy-labels are assigned to shared (unlabeled) data by means of a consensus-based algorithm. In the considered framework, heterogeneous systems can be connected over the same network, each with different computational capabilities and resources and everyone in the network may take advantage of the cooperation and will eventually reach higher performance with respect to those it can reach on its own. An extensive experimental campaign on an image classification problem emphasizes the properties of CL by analyzing the performance achieved by the cooperating agents.
💡 Research Summary
The paper introduces a novel framework called Collective Learning (CL) for distributed semi‑supervised learning, where a set of heterogeneous agents cooperate to improve their classification performance without sharing raw model parameters or private labeled data. The authors draw inspiration from human collaborative behavior, structuring the learning process into two distinct phases: a self‑training phase and a collective‑training phase.
In the self‑training phase each agent independently optimizes its own local model f_i(θ_i;·) using only its private labeled dataset D_i,T. The loss function Ψ_i(θ_i) is defined as the sum of per‑sample losses Φ_i, and any standard optimizer (SGD, Adam, etc.) can be employed. This phase requires no communication and serves to bootstrap each model with the limited supervision available locally.
The collective‑training phase leverages a shared pool of unlabeled data D_s. At each iteration a sample x_k^s is drawn from D_s. Every agent i computes a prediction z_k^i = f_i(θ_k^i; x_k^s) and broadcasts it to its out‑neighbors in a time‑varying directed graph G_k. Each agent then aggregates the predictions received from its in‑neighbors using a weighted average ∑{j∈N_i^{in}} w{k,ij} z_k^j. The aggregated value is passed through a labeling operator lbl
Comments & Academic Discussion
Loading comments...
Leave a Comment