The Deep Learning Compiler: A Comprehensive Survey
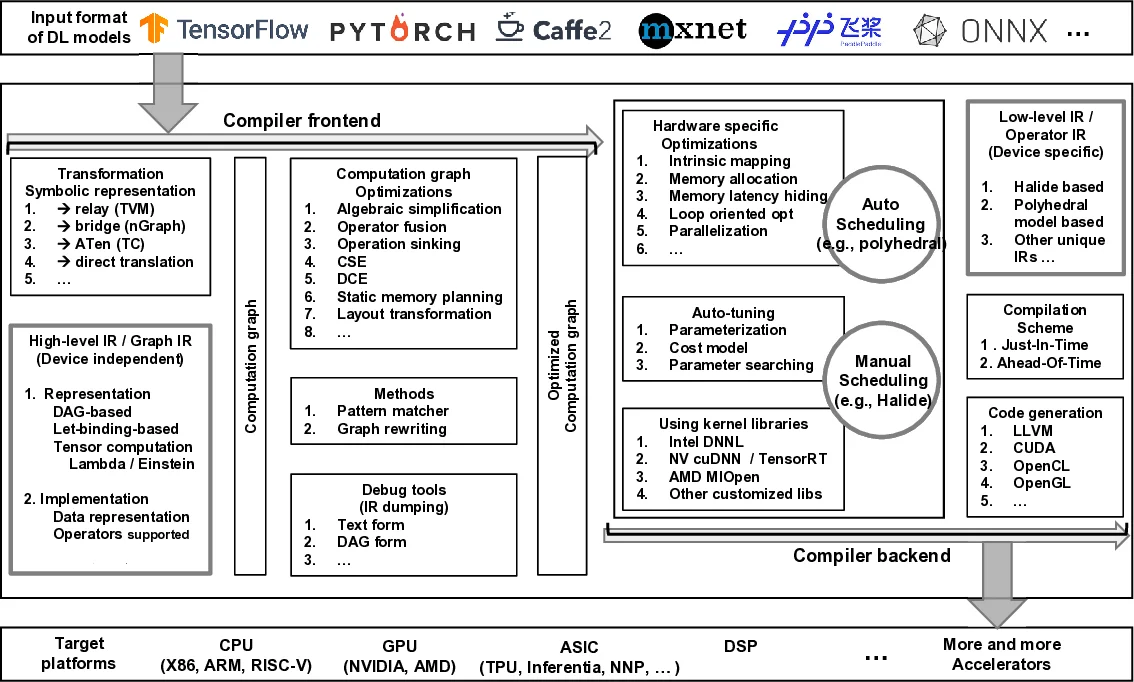
The difficulty of deploying various deep learning (DL) models on diverse DL hardware has boosted the research and development of DL compilers in the community. Several DL compilers have been proposed from both industry and academia such as Tensorflow XLA and TVM. Similarly, the DL compilers take the DL models described in different DL frameworks as input, and then generate optimized codes for diverse DL hardware as output. However, none of the existing survey has analyzed the unique design architecture of the DL compilers comprehensively. In this paper, we perform a comprehensive survey of existing DL compilers by dissecting the commonly adopted design in details, with emphasis on the DL oriented multi-level IRs, and frontend/backend optimizations. Specifically, we provide a comprehensive comparison among existing DL compilers from various aspects. In addition, we present detailed analysis on the design of multi-level IRs and illustrate the commonly adopted optimization techniques. Finally, several insights are highlighted as the potential research directions of DL compiler. This is the first survey paper focusing on the design architecture of DL compilers, which we hope can pave the road for future research towards DL compiler.
💡 Research Summary
The paper presents a comprehensive survey of deep‑learning (DL) compilers, focusing on their architectural design, intermediate representations (IRs), and optimization techniques. It begins by motivating the need for DL compilers: the rapid proliferation of diverse DL frameworks (TensorFlow, PyTorch, MXNet, etc.) and a growing ecosystem of specialized hardware (TPU, NPU, GPU, FPGA, neuromorphic chips) makes manual model‑to‑hardware mapping increasingly untenable. The authors outline the role of ONNX as a lingua franca for model exchange and describe three hardware categories—general‑purpose, dedicated, and neuromorphic—highlighting their distinct computational primitives and memory hierarchies.
The core of the survey dissects the common three‑stage compiler pipeline: frontend, multi‑level IR, and backend. The frontend parses models, performs early graph‑level optimizations (operator fusion, constant propagation, dead‑code elimination), and maps framework‑specific operators to a unified set. The multi‑level IR hierarchy is described in detail: a high‑level graph IR captures whole‑model structure; a mid‑level operator‑centric IR enables transformations such as loop unrolling, memory layout changes, and scheduling; a low‑level hardware‑specific IR expresses SIMD/vector instructions, memory‑bank assignments, and custom accelerator intrinsics. This hierarchy allows each stage to apply optimizations appropriate to its abstraction level while preserving correctness.
The backend leverages mature toolchains (e.g., LLVM) for code generation, integrates hardware‑specific kernel libraries (cuDNN, MKL‑DNN, TensorRT), and employs auto‑tuning frameworks that explore schedule and tile parameters to maximize performance on the target device. The survey then systematically compares major DL compilers—TVM, TensorFlow XLA, Glow, nGraph, Tensor Comprehensions, and others—according to criteria such as supported frameworks, target hardware, number and nature of IR levels, optimization passes, and auto‑tuning capabilities. Empirical results on CNN benchmarks (ResNet‑50, MobileNet‑V2) show that TVM’s schedule DSL and auto‑tuning achieve the highest throughput on GPUs, while XLA delivers consistent gains on TPUs. Layer‑wise analysis reveals that convolution layers benefit most from operator fusion and memory‑layout optimizations.
A taxonomy is proposed that classifies DL compilers along five axes: (1) input model format, (2) target hardware family, (3) IR hierarchy depth, (4) optimization categories (fusion, quantization, memory management, etc.), and (5) presence of auto‑tuning and library integration. This taxonomy serves both practitioners—who can select a compiler matching their constraints—and researchers—who can identify gaps in the current landscape.
Finally, the authors discuss open challenges and future research directions: dynamic shape handling, unified pre‑/post‑processing pipelines, polyhedral models for more aggressive schedule generation, sub‑graph partitioning for heterogeneous execution, mixed‑precision and advanced quantization schemes, unified optimization across multiple backends, differentiable programming to blend training and inference optimizations, and privacy‑preserving compilation (e.g., homomorphic encryption). The paper concludes that addressing these challenges will be essential for the next generation of DL compilers, enabling seamless, high‑performance deployment of increasingly complex models across an ever‑broader hardware spectrum.
Comments & Academic Discussion
Loading comments...
Leave a Comment