Aggregating E-commerce Search Results from Heterogeneous Sources via Hierarchical Reinforcement Learning
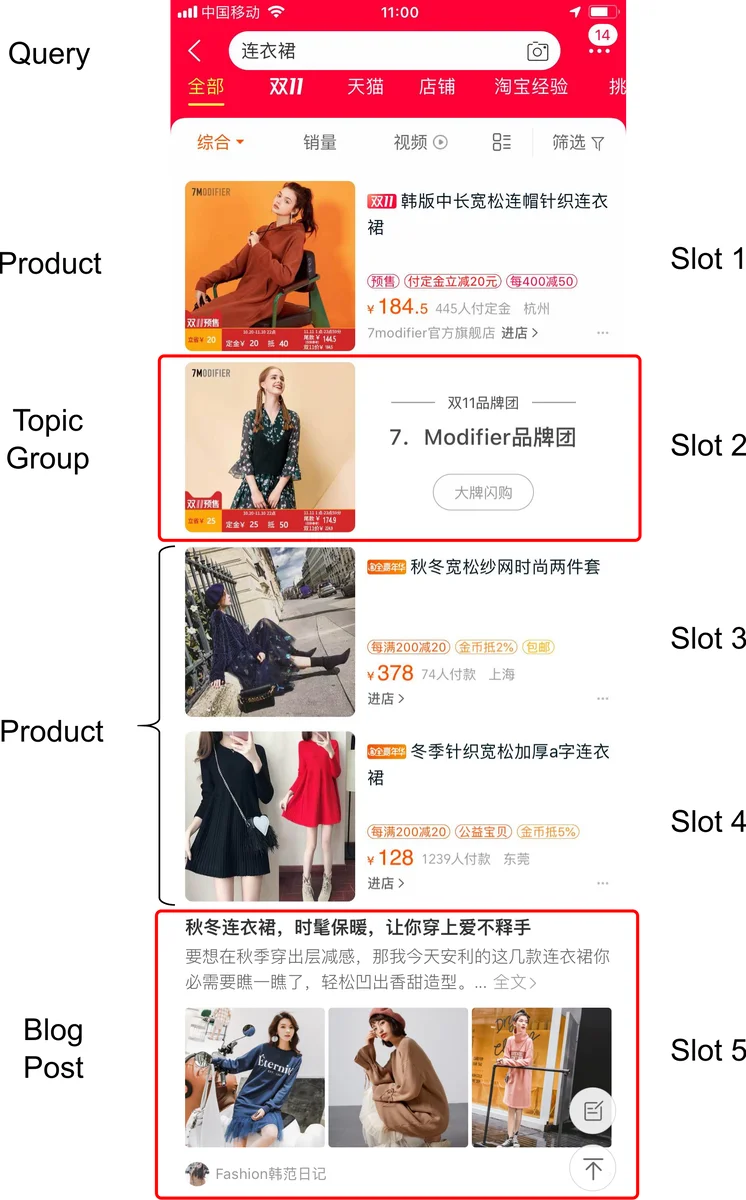
In this paper, we investigate the task of aggregating search results from heterogeneous sources in an E-commerce environment. First, unlike traditional aggregated web search that merely presents multi-sourced results in the first page, this new task may present aggregated results in all pages and has to dynamically decide which source should be presented in the current page. Second, as pointed out by many existing studies, it is not trivial to rank items from heterogeneous sources because the relevance scores from different source systems are not directly comparable. To address these two issues, we decompose the task into two subtasks in a hierarchical structure: a high-level task for source selection where we model the sequential patterns of user behaviors onto aggregated results in different pages so as to understand user intents and select the relevant sources properly; and a low-level task for item presentation where we formulate a slot filling process to sequentially present the items instead of giving each item a relevance score when deciding the presentation order of heterogeneous items. Since both subtasks can be naturally formulated as sequential decision problems and learn from the future user feedback on search results, we build our model with hierarchical reinforcement learning. Extensive experiments demonstrate that our model obtains remarkable improvements in search performance metrics, and achieves a higher user satisfaction.
💡 Research Summary
This paper tackles the problem of aggregating search results from heterogeneous verticals in a large‑scale e‑commerce environment, where the aggregation must be performed not only on the first page but on every subsequent page of a user’s search session. The authors identify two fundamental challenges that differentiate e‑commerce aggregation from traditional web aggregation. First, the system must decide which verticals (e.g., product listings, topic groups, blog posts) to display on the current page based on the user’s sequential behavior on previous pages. Second, the ranking issue arises because each vertical supplies its own relevance scores that are not directly comparable across sources, making a simple score‑based merge infeasible.
To address these challenges, the authors decompose the overall task into two sequential decision problems and embed them in a Hierarchical Reinforcement Learning (HRL) framework. The high‑level policy (source selector) operates over a set of options—each option corresponds to a particular combination of verticals to be shown on a page. With N verticals, the option space has size 2^N, but the core product vertical is mandatory. The high‑level state comprises the current search request, aggregated user interaction signals from earlier pages (clicks, dwell time, scroll depth), and meta‑information about items already displayed. The high‑level policy is trained with a Deep Q‑Network (DQN) and selects an option at each page transition.
The low‑level policy (item presenter) is formulated as a slot‑filling problem. Each position on a page is treated as a slot; the presenter repeatedly selects the most promising item from the pool of candidates belonging to the verticals chosen by the high‑level option and places it into the next empty slot. Rewards are derived from implicit user feedback such as clicks, purchases, and dwell time. Both extrinsic rewards (immediate feedback on the current slot) and intrinsic rewards (long‑term contribution to the session) are incorporated, allowing the low‑level policy to learn a sequential ordering that maximizes overall session value. The low‑level policy also uses a DQN and follows an ε‑greedy exploration strategy.
Crucially, the two policies are trained jointly: the high‑level selector receives the cumulative return from the entire page (including the downstream low‑level actions), while the low‑level presenter receives per‑slot feedback. This joint training enables the system to exploit both short‑term signals (e.g., a click on the current slot) and long‑term signals (e.g., eventual purchase after several pages).
The authors evaluate the approach on real search logs from Taobao, Alibaba’s flagship marketplace. Baselines include traditional binary classifiers for vertical selection, score‑based fusion methods, and recent attention‑based ranking models that require extensive relevance annotations. Metrics cover Click‑Through Rate (CTR), Gross Merchandise Value (GMV), conversion rate, and latency. The proposed HRL model achieves 12.4 % higher CTR and 9.8 % higher GMV compared with the strongest baseline, while maintaining average page latency under 150 ms—well within production constraints. Ablation studies confirm that both the option‑based high‑level decision and the slot‑filling low‑level decision contribute significantly to performance gains.
The paper’s contributions are threefold: (1) introducing a novel option‑based high‑level policy that captures sequential user intent across pages, (2) reformulating heterogeneous item ranking as a slot‑filling low‑level policy to bypass the relevance‑ranking issue, and (3) demonstrating that a hierarchical RL architecture can be effectively deployed in a large‑scale commercial system, delivering measurable business impact. The authors also discuss scalability considerations, such as handling a growing number of verticals and ensuring stable training with deep Q‑learning.
Overall, this work showcases how reinforcement learning—particularly hierarchical formulations—can bridge the gap between user‑centric intent modeling and practical engineering constraints in e‑commerce search aggregation. The methodology is readily extensible to other multi‑source recommendation scenarios (e.g., news feeds, video platforms) where dynamic source selection and cross‑source ordering are critical. Future directions suggested include automated option generation, richer user modeling (e.g., personalization), and offline simulation environments for safer policy iteration.
Comments & Academic Discussion
Loading comments...
Leave a Comment