AngularGrad: A New Optimization Technique for Angular Convergence of Convolutional Neural Networks
Convolutional neural networks (CNNs) are trained using stochastic gradient descent (SGD)-based optimizers. Recently, the adaptive moment estimation (Adam) optimizer has become very popular due to its adaptive momentum, which tackles the dying gradient problem of SGD. Nevertheless, existing optimizers are still unable to exploit the optimization curvature information efficiently. This paper proposes a new AngularGrad optimizer that considers the behavior of the direction/angle of consecutive gradients. This is the first attempt in the literature to exploit the gradient angular information apart from its magnitude. The proposed AngularGrad generates a score to control the step size based on the gradient angular information of previous iterations. Thus, the optimization steps become smoother as a more accurate step size of immediate past gradients is captured through the angular information. Two variants of AngularGrad are developed based on the use of Tangent or Cosine functions for computing the gradient angular information. Theoretically, AngularGrad exhibits the same regret bound as Adam for convergence purposes. Nevertheless, extensive experiments conducted on benchmark data sets against state-of-the-art methods reveal a superior performance of AngularGrad. The source code will be made publicly available at: https://github.com/mhaut/AngularGrad.
💡 Research Summary
The paper introduces AngularGrad, a novel optimizer for training convolutional neural networks (CNNs) that explicitly incorporates the angular relationship between consecutive gradients. While traditional optimizers such as SGD, Adam, RMSProp, and their many variants rely primarily on the magnitude of the gradient (and sometimes its variance), they ignore how the direction of the gradient changes over time. AngularGrad addresses this gap by computing the angle Aₜ between the current gradient gₜ and the previous gradient gₜ₋₁. Two formulations are proposed: one based on the arctangent of the normalized difference (tangent variant) and another based on the cosine of the angle (cosine variant). The minimum of the current and previous angles, A_min, is passed through a hyperbolic tangent to obtain a smooth scaling factor ϕₜ = tanh(|∢(A_min)|)·λ₁+λ₂, where λ₁ and λ₂ are binary hyper‑parameters (empirically set to ½ each). This factor modulates the effective learning rate in the Adam‑style update rule:
θₜ = θₜ₋₁ – α·ϕₜ·(m̂ₜ / (√v̂ₜ + ε)).
When the angle between successive gradients is large (indicating a zig‑zag trajectory), ϕₜ becomes small, reducing the step size and dampening oscillations. Conversely, when the angle is small, ϕₜ approaches one, allowing larger steps and accelerating convergence. The authors prove that AngularGrad retains the same O(√T) regret bound as Adam, because ϕₜ is bounded between 0 and 1 by construction.
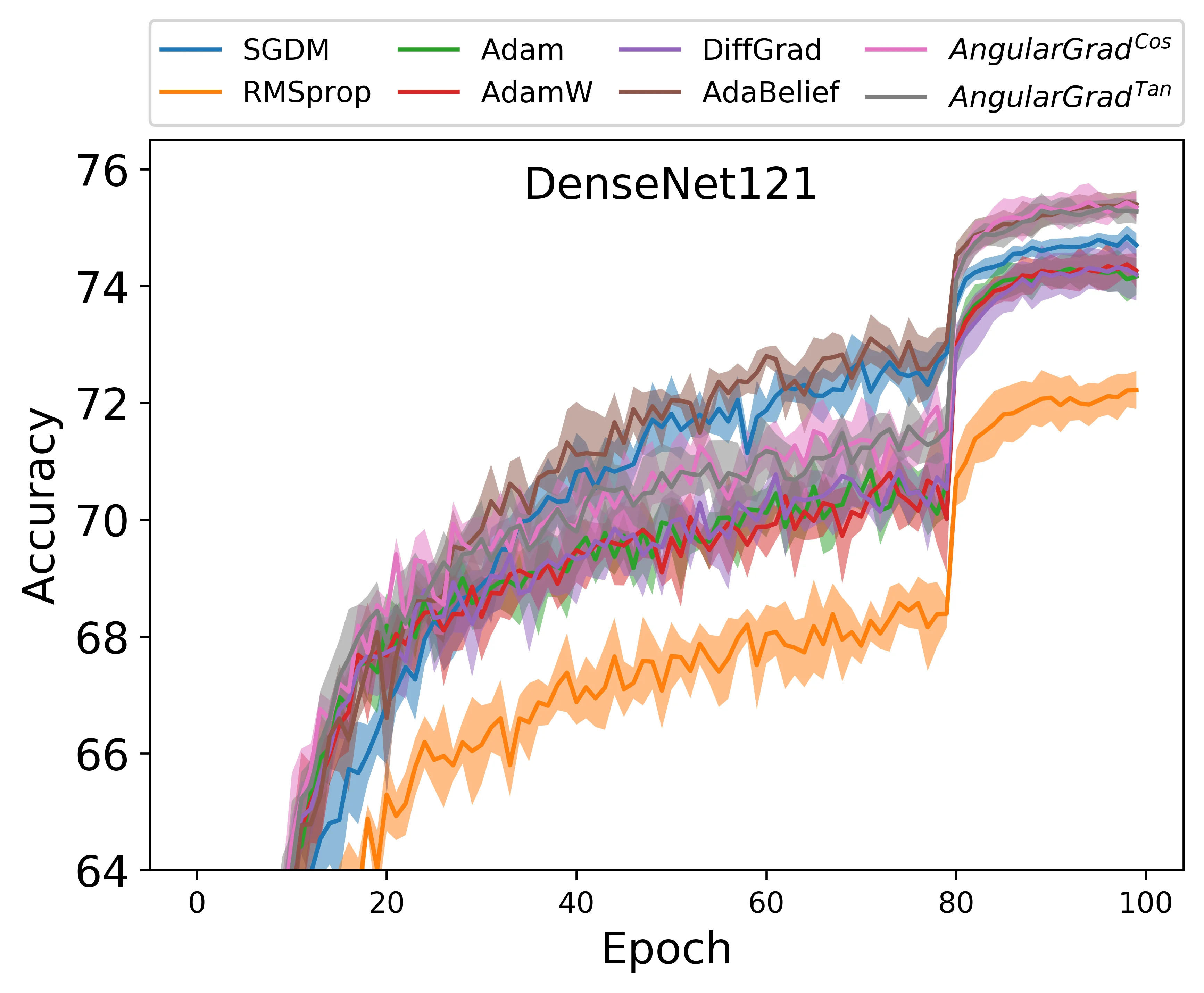
Extensive experiments were conducted on several image‑classification benchmarks (CIFAR‑10, CIFAR‑100, Tiny‑ImageNet, ImageNet‑1K) using a variety of modern CNN architectures (ResNet‑18/34, DenseNet‑121, EfficientNet‑B0, MobileNet‑V2). AngularGrad consistently outperformed Adam, RAdam, diffGrad, AdaBelief, and other state‑of‑the‑art optimizers in terms of final top‑1 accuracy (improvements of 0.3–0.8 percentage points), faster loss reduction, and fewer epochs to convergence. The optimizer’s memory footprint and computational overhead are comparable to Adam, as the additional angle calculations involve only a few vector inner products and a tanh operation per iteration.
The paper also discusses limitations: the extra arctangent/cosine computations could become non‑trivial for extremely large models (e.g., transformer‑scale language models), and the fixed λ₁, λ₂ values may not be optimal for all tasks. Future work is suggested in adaptive tuning of these hyper‑parameters, integration with other recent optimizers (e.g., LAMB, Lion), and application beyond vision, such as NLP or reinforcement learning.
In summary, AngularGrad enriches the optimizer’s information set by adding a directional (angular) component to the traditional magnitude‑based statistics. This leads to smoother optimization trajectories, mitigates the zig‑zag phenomenon, and yields empirically superior performance while preserving theoretical convergence guarantees, marking a meaningful contribution to the field of deep‑learning optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment