Deep-Learned Event Variables for Collider Phenomenology
The choice of optimal event variables is crucial for achieving the maximal sensitivity of experimental analyses. Over time, physicists have derived suitable kinematic variables for many typical event topologies in collider physics. Here we introduce a deep learning technique to design good event variables, which are sensitive over a wide range of values for the unknown model parameters. We demonstrate that the neural networks trained with our technique on some simple event topologies are able to reproduce standard event variables like invariant mass, transverse mass, and stransverse mass. The method is automatable, completely general, and can be used to derive sensitive, previously unknown, event variables for other, more complex event topologies.
💡 Research Summary
The paper introduces a novel deep‑learning framework for automatically constructing low‑dimensional event variables that retain maximal information about underlying theory parameters in high‑energy collider experiments. Traditional analyses rely on human‑engineered kinematic variables (e.g., invariant mass, transverse mass, stransverse mass) that are tailored to specific event topologies. The authors ask whether these handcrafted variables are truly optimal and whether a machine can discover better, more general observables.
Their solution is to train an “Event Variable Network” (EVN) together with an auxiliary classifier. The EVN maps the high‑dimensional raw event data X (e.g., four‑momenta of reconstructed objects) to a low‑dimensional variable V(X). To ensure V captures as much information about the model parameters Θ as possible, they construct a binary classification task: class 0 samples are generated by pairing X and Θ independently (producing the product distribution p_X⊗p_Θ), while class 1 samples retain the true joint distribution p(X,Θ). The classifier receives (V,Θ) as input and learns to distinguish the two classes. Training the composite network to minimize binary cross‑entropy is equivalent to maximizing the mutual information I(V;Θ), i.e., minimizing the information loss incurred by dimensionality reduction.
Training data are produced by sampling Θ from a broad prior p_Θ and generating events X from the conditional distribution p_{X|Θ} using standard Monte‑Carlo generators. The authors emphasize that the prior must cover the full range of parameter values over which the resulting variable should be sensitive, a departure from the usual practice of fixing Θ to a benchmark point.
The methodology is demonstrated on three benchmark topologies:
-
Fully visible two‑body decay (A → b c). Here Θ is the parent mass m_A, and X consists of the four‑momenta of the two massless daughters (8‑dimensional input). After training, the learned variable V correlates almost perfectly (Kendall τ ≈ 0.95, Spearman ρ ≈ 0.997) with the invariant mass m_bc, the known optimal observable. The distribution of V shifts clearly with different m_A values, showing strong sensitivity across the sampled mass range.
-
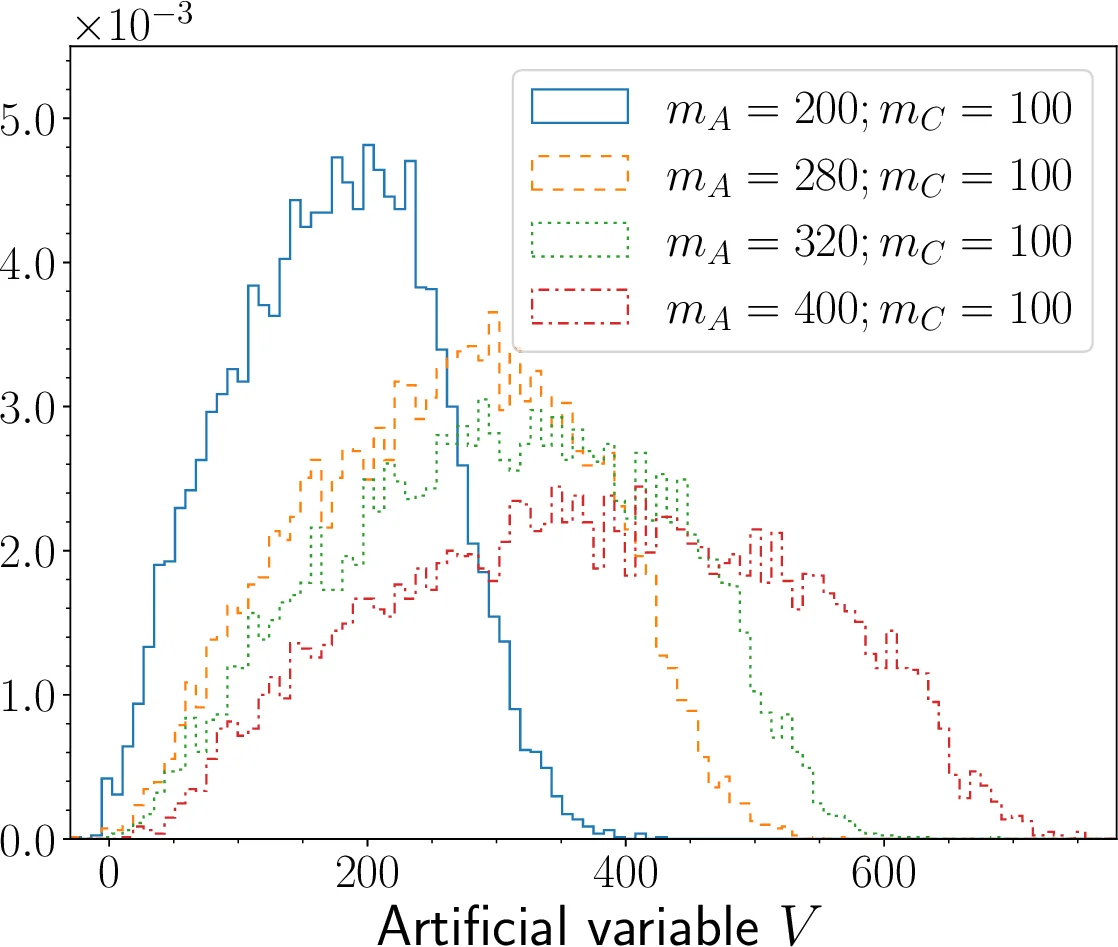
Semi‑visible two‑body decay (A → b C). Θ = (m_A, m_C) is two‑dimensional, and X includes the visible particle’s four‑momentum plus missing transverse momentum (6‑dimensional input). The optimal observable is the transverse mass m_T. The learned V again exhibits an almost one‑to‑one mapping to m_T (τ ≈ 0.95, ρ ≈ 0.994) and its histograms vary markedly with the chosen (m_A, m_C) pair, confirming the method’s ability to handle missing energy.
-
Symmetric pair‑production with semi‑visible decays (A₁A₂ → (b₁C₁)(b₂C₂)). The relevant variable is the stransverse mass m_T2. The EVN reproduces this variable with high fidelity, demonstrating that the approach scales to more complex event structures involving two invisible particles.
All networks are built in TensorFlow, using fully‑connected layers with ReLU activations for the EVN (five hidden layers of 128–64–64–64–32 units) and a smaller classifier (three hidden layers of 16 units). Training uses the Adam optimizer, a batch size of 50, and 2.5 million events (balanced between the two classes), with 20 % reserved for validation.
The results prove that the EVN can automatically discover the same optimal kinematic variables that physicists have derived analytically over decades, without any explicit physics input beyond the definition of the training task. This validates the underlying information‑theoretic principle and opens the door to discovering new observables for topologies where no analytic solution is known.
However, the study has limitations. It focuses exclusively on a single output variable (d_V = 1); extending to multi‑dimensional observables (e.g., joint distributions of several variables) remains to be explored. The network architecture and hyper‑parameter choices are not systematically optimized, leaving open the question of how much performance can be gained with more sophisticated models (e.g., graph neural networks that respect particle‑level symmetries). Moreover, the experiments are performed on idealized simulated data without detector effects, pile‑up, or realistic background contamination. Applying the method to actual LHC data will require incorporating these effects, possibly via domain‑adaptation techniques or by training on full detector simulations.
In summary, the paper presents a compelling, generalizable framework that leverages mutual information maximization to automate the design of collider observables. By reproducing invariant mass, transverse mass, and m_T2 in controlled settings, it demonstrates both interpretability (through direct comparison with known variables) and optimality (via information‑theoretic arguments). Future work should aim at (i) multi‑variable extensions, (ii) integration with realistic experimental pipelines, and (iii) application to novel signatures such as cascade decays, compressed spectra, or exotic long‑lived particle searches, where human‑crafted variables are currently limited. The approach promises to enhance discovery potential while reducing reliance on ad‑hoc feature engineering in high‑energy physics analyses.
Comments & Academic Discussion
Loading comments...
Leave a Comment