Personalizing ASR for Dysarthric and Accented Speech with Limited Data
Automatic speech recognition (ASR) systems have dramatically improved over the last few years. ASR systems are most often trained from 'typical' speech, which means that underrepresented groups don't experience the same level of improvement. In this …
Authors: Joel Shor, Dotan Emanuel, Oran Lang
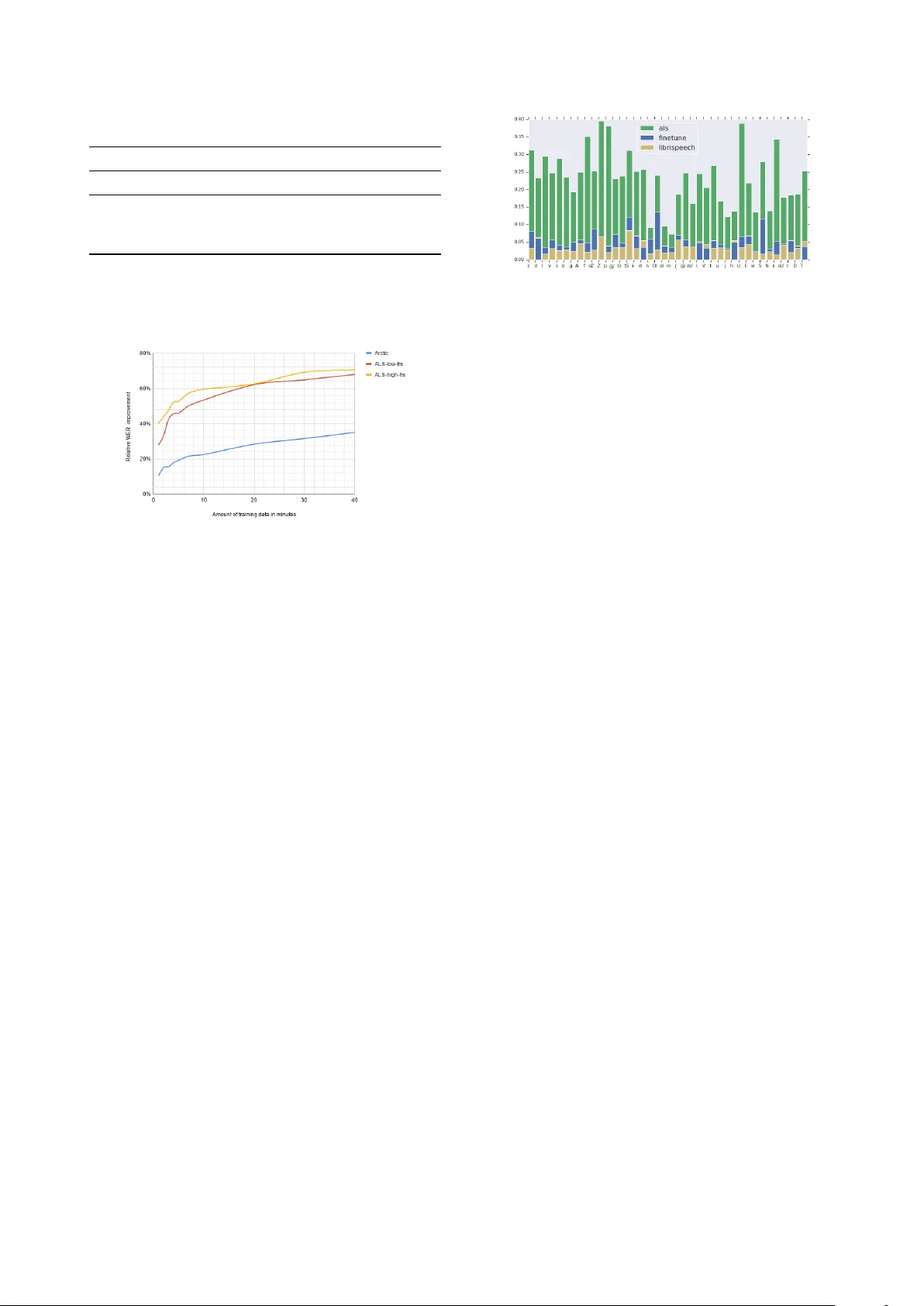
P ersonalizing ASR f or Dysarthric and Accented Speech with Limited Data J oel Shor 1 , Dotan Emanuel 1 , Oran Lang 1 , Omry T uval 1 , Michael Br enner 1 , J ulie Cattiau 1 , F ernando V ieira 2 , Maeve McNally 2 , T aylor Charbonneau 2 , Melissa Nollstadt 2 , A vinatan Hassidim 1 , Y ossi Matias 1 1 Google, United States 2 ALS Therapy De velopment Institute, United States { joelshor, dotan, oranl } @google.com Abstract Automatic speech recognition (ASR) systems hav e dramatically improv ed ov er the last fe w years. ASR systems are most often trained from typical speech, which means that underrepresented groups dont experience the same level of improvement. In this paper , we present and ev aluate finetuning techniques to improve ASR for users with non-standard speech. W e focus on two types of non-standard speech: speech from people with amyotrophic lateral sclerosis (ALS) and accented speech. W e train personal- ized models that achie ve 62% and 35% relative WER improve- ment on these two groups, bringing the absolute WER for ALS speakers, on a test set of message bank phrases, down to 10% for mild dysarthria and 20% for more serious dysarthria. W e show that 71% of the improvement comes from only 5 minutes of training data. Finetuning a particular subset of layers (with many fewer parameters) often gives better results than finetun- ing the entire model. This is the first step to wards building state of the art ASR models for dysarthric speech. Index T erms : speech recognition, personalization, accessibil- ity 1. Introduction State-of-the-art speaker -independent ASR systems are made possible by large datasets and data-driven algorithms. This setup works well when the dataset contains a large amount of data from all types of voices that one would want the system to recognize, but fails on groups not well-represented in the data: ASR models trained on thousands of hours of ‘typical users’ recognize voices in the typical use-case, but often fail to recog- nize accented voices or ones impacted by medical conditions. Getting ASR to work on non-standard speech is dif ficult for a few reasons. First, it can be difficult to find enough speakers to train a state-of-the-art model. Second, individuals within a group like ‘ ALS’ or a particular accent can hav e very differ - ent ways of speaking. This paper’ s approach overcomes data scarcity by beginning with a base model trained on thousands of hours of standard speech. It gets around sub-group hetero- geneity by training personalized models. This paper details the technical approach to Project Eu- phonia, an accessibility project announced at Google I/O 2019 [1, 2]. T o demonstrate our approach, we focus on accented speech from non-nativ e English speakers, and speech from in- dividuals living with ALS. ALS is a progressive neurodegen- erativ e disorder that affects speech production, among other things. About 25% of people with ALS experience slurred speech as their first symptom [3]. Most people with ALS ev en- tually lose mobility , so they would especially benefit from being able to interact verbally with smart home devices. The se verity of dysarthria for people with ALS is measured with an FRS score, ranging from 0 to 4, with 0 being incomprehensible and 4 normal [4]. In this paper, we improve state-of-the-art ASR for indi viduals with ALS FRS 1-3 and heavy accents. The main contributions of this paper are: 1. A finetuning technique for personalizing an ASR model on dysarthric speech that yields word error rates on a test set of message bank phrases [5] of 10 . 8% for mild dysarthria (FRS of 3) and 20 . 9% for severe dysarthria (FRS of 1-2). The finetuning technique yields a word er- ror rate of 8 . 5% on he avily accented data. The finetuned models make recognition mistakes that are distribution- ally more similar to standard ASR mistakes on standard speech. 2. Demonstrating that the finetuning giv es significant im- prov ement over the base model in multiple scenarios, including different non-standard speech (dysarthric and accented), and on different architectures. 3. On the ALS speech, 71% of the relative WER improv e- ment can be achiev ed with 5 minutes of data, 80% with 10 minutes of data. Furthermore, for some models, just training the encoder produces better results, and just training the layers closest to the input yields 90% of total relativ e improv ement. 2. Related W ork Neural networks are the state-of-the-art systems for ASR in the large data-regime. W e explore how well two particular archi- tectures can be finetuned on a small amount of non-standard data. The RNN-Transducer [6, 7] is a neural network architec- ture that has shown good results on numerous ASR tasks. It consists of an encoder and decoder network and is configured such that unidirectional models can perform streaming ASR. In this paper , we use a bidirectional encoder without attention that was sho wn to achie ve comparable results [8]. W e also e xplore the Listen, Attend, and Spell architec- ture. It is an attention-based, sequence-to-sequence model that maps sequences of acoustic properties to sequences of language [9]. It has produced state-of-the-art results on a challenging 12,500 hour voice-search ASR task, achie ving a 4 . 1% WER [10]. This model uses an encoder to con vert the sequence of acoustic frames to a sequence of internal representations, and a decoder with attention to con vert the sequence of internal representations to linguistic output. The best network in [10] produced word pieces, which are a linguistic representation be- tween graphemes and words [11]. There are a number of methods for adapting large ASR models to small amounts of data [12, 13, 14]. This paper’ s ap- Figure 1: Schematic diagrams of the RNN-T architectur e (left) and the LAS ar chitectur e (right). Diagrams come fr om [8]. proach is most similar to [15], which in volv es selectiv ely fine- tuning parts of the ASR model. There are also many published techniques on how to im- prov e ASR specifically for pathological, or dysarthric, speech: [16] appended articulatory features to the usual acoustic ones to achieve a 4-8% relati ve WER improv ement, and [17] adapts ASR models trained on open source datasets to a dataset of dysarthric speech. Howe ver , all these approaches are limited either by the quality of the base model or the amount of data av ailable for finetuning. Numerous studies ha ve explored the acoustic, articula- tory , and phonetic differences between standard and modified speech. Some of the conditions explored are Parkinsons [18], age [19], dyslexia [20], and ALS [21]. W e add to this body of work by describing the phonetic mistakes that a production ASR system makes on a large collection of ALS audio. W e are also able to describe our improved ASR model by character- izing which phonemes the improved models are better able to recognize. 3. Experiments W e create personalized ASR models by starting with a base model trained on standard, unaccented speech. This approach is much more resource efficient than retraining the entire model, from scratch, for each speaker . In order to verify that we are learning something other than just the idiosyncrasies of a par- ticular model, we run most of our experiments starting from two different models: a Bidirectional RNN T ransducer (RNN- T) model [6], and a Listen, Attend, and Spell (LAS) model [9]. Both are end-to-end sequence-to-sequence models. W e follow the training procedure in [8] for the RNN-T model and [10] for the LAS model (on the 1000 hour, open source Librispeech dataset [22]). W e finetune different layer combinations on different amounts of data, on both ALS and accents datasets. W e fine- tune models per speaker . 3.1. Data 3.1.1. ALS W e collected 36 . 7 hours of audio from 67 people with ALS, in partnership with the ALS Therapy Development Institute (ALS- TDI). The participants were given sentences to read, and they recorded themselves on their home computers using custom software. The sentences were collected from three sources: The Cornell Movie-Dialogs Corpus [23], a collection of sentences used by te xt-to-speech voice actors, and a modified selection of sentences from the Boston Children’ s Hospital [5]. Note that this corpus is a restricted language domain, but is phonetically very similar to other corpora e.g. Librispeech. The FRS scores of participants were measured by ALS-TDI, and we only ev alu- ate on people with speech FRS 3 and belo w ( 17 speakers, 22 . 1 hours). See the attached multimedia file for audio examples. 3.1.2. Accented Speech T o test our finetuning method on another type of non-standard speech, we use the L2 Arctic dataset of non-nativ e speech [24]. This dataset consists of 20 speakers with approximately 1 hour of speech per speaker . Each speaker recorded a set of 1150 phonetically balanced utterances. For each of the 20 speakers, we split the data into 90/10 train and test. All of the sentences which contains proper nouns are used in the training set, in or- der to remo ve the possibility of the model to artificially achie ve better results on the test set by memorizing them. 3.2. Base Models All our base networks and finetuning are trained on 80-bin log- mel spectrograms computed from a 25ms window and a 10ms hop. W e use the same technique presented in [25] and used in [8]: we stack frames in groups of 3 and process them as one ’ super-frame. ’ W e trained RNN-T and LAS architectures (Figure 1). All training was performed with the multicondition training (MTR) techniques described in [8]. During training, we distorted the audio using a room simulator deriv ed from Y ouT ube data. The av erage SNR of the added noise is 12dB. W e use the T ensor- Flow library Lingv o [26]. 3.2.1. Bidir ectional RNN-T ransducer In this paper, we primarily work with a bidirectional RNN- T ransducer (RNN-T) architecture that achieves near state-of- the-art performance. This architecture was first introduced in [6]. W e use the version presented in [8]. The network maps acoustic frames to word pieces, which are a linguistic repre- sentation between graphemes and words [11]. It has a 5 layer bidirectional con volutional LSTM encoder, a 2 layer LSTM de- coder , and a joint layer . It has 49.6M parameters in total. 3.2.2. Listen, Attend, and Spell model T o verify which results generalize beyond a particular architec- ture, we also run some of our experiments with a Listen, At- tend, and Spell (LAS) model trained on the open source Lib- rispeech dataset [22]. This architecture was first introduced in [9]. The model that we use is described in [10]. It is a sequence- to-sequence with attention model that maps acoustic frames to graphemes. W e use an encoder with 4 layers of bidrectional con v olutional LSTMs and a 2 layer RNN decoder . The model has a total of 132M parameters. Our grapheme targets are the 26 English lo wer -case letters, punctuation symbols, and a space. There are 33 tar get grapheme symbols. The base LAS model was trained to 1M steps on all 960 hours of the Librispeech dataset. It achiev ed a 5 . 5% WER on the clean test split and 15 . 5% on the non-clean test split (the two standard test splits gi ven in the dataset). T able 1: A vera ge WER Impr ovements Cloud RNN-T LAS Base Finetune Base Finetune Arctic 1 24 . 0 13 . 3 8 . 5 22 . 6 11 . 3 ALS 2 42 . 7 59 . 7 20 . 9 86 . 3 31 . 3 ALS 3 13 . 1 33 . 1 10 . 8 49 . 6 17 . 2 1 Non-nativ e English speech from the L2-Arctic dataset. [24] 2 Low FRS (ALS Functional Rating Scale) intelligible with repeating, Speech combined with nonv ocal communication. 3 FRS-3 detectable speech disturbance. [4] Figure 2: A verag e Relative WER impr ovement as a function of the amount of training data. 3.3. Finetuning All our finetuning uses four T esla V100 GPUs for no more than four hours. 3.3.1. RNN-T W e started by finetuning 1, 2, and 3 layers in fixed combina- tions (treating the decoder as a single layer), on both datasets, adjusting hyperparameters as necessary . Let E i denote the i th layer of the encoder , where lower -numbered layers are closer to the input. W e uniformly found that training from E 0 up with or without the joint layer was always better than the other meth- ods, so we focused our search on training from E 0 up, with or without the joint layer . Next, for each ALS and accented individual, we exhaus- tiv ely searched our finetuning space, with various amounts of data. For the RNN-T , this meant finetuning each of E 0 , E 0 -E 1 , E 0 -E 2 , etc.. the entire encoder, with or without the joint layer . 3.3.2. LAS For LAS architectures, we finetuned various layer combinations and consistently found that the best results from this network came from finetuning all layers. All results reported in this pa- per for the LAS network are on finetuning the entire network, unless otherwise specified. 4. Results 4.1. Perf ormance W e report our absolute word error rate in T able 1. The re- sults show dramatic improv ement ov er Google cloud ASR [27] model for very non-standard speech (heavy accents and ALS Figure 3: The distribution of phoneme mistakes before and after finetuning. x-axis is SAMP A phoneme . y-axis is number of times that phoneme was deleted or substituted divided by number of phoneme occurances in the gr ound truth transcripts. speech below 3 on the ALS Functional Rating Scale [4]) and moderate improvements in ALS speech that is similar to healthy speech. The comparison to Google cloud ASR demonstrates that a healthy speech model finetuned on non-standard speech produces strong results, but we acknowledge that the compari- son is not perfect: the LAS and RNN-T models use the entire audio to make predictions while Google cloud ASR model only looks backwards in time. This lets Google cloud ASR support streaming, but it is also less accurate. The relativ e difference between base model and the fine- tuned model demonstrates that the majority of the improv ement comes from the finetuning process, except in the case of the RNN-T on the Arctic dataset (where the RNN-T baseline is al- ready strong). 4.2. Limited Data On the ALS dataset, finetuning on fiv e minutes and ten minutes of data yields 75% and 85% of the WER improvement com- pared to a model trained on 40 min of data, respectiv ely . On the Arctic dataset, fourteen and twenty minutes of training data yields 70% and 81% of the WER improvement, respectively . Figure 2 shows more details. 4.3. Layers The LAS model consistently performed best when the entire network was finetuned. The RNN-T model achie ved 91% of the relativ e WER improvement by just finetuning the joint layer and first layer of the encoder (compared to finetuning the joint layer and the entire encoder, the a verage WER across all participants regardless of FRS score w as 18.1% vs 15.1%). On Arctic, fine- tuning the joint layer and the first encoder layer achiev ed 86% of the relative improvement compared to finetuning the entire network ( 11 . 0% vs 10 . 5% ). 4.4. Phoneme mistakes T o better understand how our models improved, we looked at the pattern of phoneme mistakes. W e started by comparing the distribution of phoneme mistakes made by Google cloud ASR model on standard speech (Librispeech) to the mistakes made on ALS speech. W e map the ground truth transcripts and the ASR model outputs to sequences of SAMP A phonemes, then compute the edit distance between the two phoneme sequences. W e aggregate o ver speak ers and utterances. First, we compute the probability of a mistake for a partic- ular phoneme in the ground truth transcript. Since the standard speech and ALS speech transcripts are different, we normal- ize by the number of ground truth transcript phonemes. The phonemes with the five largest differences between the ALS data and standard speech are p, U, f, k, and Z. These five ac- count for 20% of the likelihood of a deletion mistake. Next, we in vestig ate which phonemes are mistakenly added. W e compute the probability that a particular phoneme will mistakenly appear in the recognized transcript. By far the biggest differences are in the n and m phonemes, which together account for 17% of the insertion / substitution mistakes. Finally , we perform the same analysis on some of our finetuned models. The unrecognized phoneme distribution be- comes more similar to that of standard speech (see Figure 3). Also, surprisingly , the phoneme distrib ution that the model pro- duced when it made a mistake was much more similar to mis- takes on standard speech after finetuning (KL of 0 . 26 between standard and ALS, 0 . 10 after finetuning). 5. Discussion In this paper , we de velop well-performing ASR models for dysarthric and heavily accented individuals by carefully fine- tuning healthy-speech models. Specifically , we demonstrated: 1. Good absolute performance on av erage dysarthric ALS speakers, large impro vements in very dysarthric speak ers 2. Better performance on ALS and accented speech when just training the RNN-T encoder 3. Much of the improvement is from the first 5-10 minutes of training data, and can be achieved by just training the first encoder layer and the joint layer 4. The fiv e most mistaken phonemes in ALS speech ac- count for 20% of the mistakes Prior to this work, it was unclear how much improvement could be achie ved by finetuning on small amounts of non- standard speech. W e show that with on the order of 1 hour of data, we can create a personalized ASR model that is sig- nificantly better than Cloud-based services. This improvement comes mainly from the finetuning process: we see a relative WER improv ement ov er our base model of 70% for dysarthric speech (for both groups) and 35 . 1% for accented speech. The finetuning process used four GPUs for fewer than four hours, making this technique very accessible. W e achiev e better performance by just training the encoder for the RNN-T architecture but not the LAS architecture. This is likely due to a peculiarity of the RNN-T : the RNN-T architec- ture is factorized into a component whose activ ations are solely a function of the current audio (the encoder) and another com- ponent whose activ ations are a function of the current predicted transcript (the decoder). The LAS model has no such factor- ization, so information about the acoustics and linguistics are likely more evenly distributed throughout the network. This claim isn’t precise, since the RNN-T weights used at inference time are determined by the statistical properties of both lan- guage and acoustics, b ut e ven minor effects from this factoriza- tion might mean that finetuning the encoder only helps prevent the network from overfitting to the language seen in the small amount of training data. A large fraction of the improvement comes from the first 5-10 minutes of audio. One explanation is that the test and train sentences are linguistically similar enough for the model to learn the kinds of things that are said during testing from a small number of examples. Another explanation is that just fine- tuning part of the network allows it to retain the general acous- tic and linguistic information from the general speech model while needing minimal modifications to adapt to a single new speaker . Future work includes testing this hypothesis, possibly by exploring its performance on radically dif ferent sentences. The model might be adapting to general non-standard speech or to the individual. This could be tested, for instance, by training a single model on the entire ALS or Arctic corpus, and comparing it to a single speaker model. W e didn’t include results from this comparison, and we discuss this in the ‘Future W orks’ section. W e found that finetuning just the joint layer and the first encoder layer achieved 90% of the relative improvement com- pared to training the joint layer and the entire encoder . This can be explained by a combination of the acoustic vs linguistic properties discussed earlier in this section and by analogy with a popular computer vision finetuning technique. Many computer vision papers publish good results by finetuning the last few layers of a classification network that was pretrained on Ima- genet [28]. In that technique, authors usually assume that their data follows roughly the distribution of images in imagenet, and that their image label distribution is different. Our problem has the reverse assumption: we assume that the distribution of lan- guage (labels) is the same in our problem as in standard speech, but that the distribution of ALS / accented speech is different from that of standard speech. Lastly , we find that the five most deleted / substituted phonemes account for roughly 20% of such errors, and that the two most incorrectly inserted phonemes account for just over 20% of such errors. This kind of observation might lead to ALS-detection techniques: one can try to detect ALS degra- dation by matching the prediction distribution of a production ASR system. W e might also be able to improve the finetuning process by collecting more speech that inv olv es the most-often- confused phonemes. 6. Future W ork A major challenge is to build state of the art speech recogni- tion models for strongly dysarthric speech. It is an open ques- tion whether there are additional techniques that can be helpful in the low data regime (such as V irtual Adversarial T raining, data augmentation, etc). W e can also use the phoneme mistakes to weight certain examples during training, or to pick training sentences for people with ALS to record that contain the most egre gious phoneme mistakes. W e would lik e to explore pooling data from multiple speak- ers with similar conditions, but did not do so in this paper . W e believ e that such an experiment raises more questions around training speaker-independent non-standard speech ALS mod- els, which we feel are outside the scope of this work. 7. Acknowledgements W e’ d like to thank T ara Sainath, Anshuman T ripathi, Hasim Sak, Ding Zhao, Ron W eiss, Chung-Cheng Chiu, Dan Liebling, and Philip Nelson for technical and project guidance. 8. References [1] Google, “Project euphonia: Helping everyone be better understood, ” 2019. [Online]. A vailable: https://www .youtube. com/watch?v=O AdegPmkK- o&t=1s [2] J. Cattiau, “How ai can improve products for people with impaired speech, ” 2019. [Online]. A vailable: https://blog.google/ outreach- initiatives/accessibility/impaired- speech- recognition/ [3] https://www .als.net/what- is- als/. [4] A. C. T . S. A. P . I.-I. S. Group, “The amyotrophic lateral sclerosis functional rating scale: Assessment of activities of daily living in patients with amyotrophic lateral sclerosis, ” Ar chives of Neur ology , v ol. 53, no. 2, pp. 141–147, 02 1996. [Online]. A vailable: https://doi.org/10.1001/archneur .1996. 00550020045014 [5] J. Costello, “Message banking, voice banking and legacy mes- sages, ” Boston, MA: Boston Children’ s Hospital , 2014. [6] A. Grav es, “Sequence transduction with recurrent neural net- works, ” arXiv pr eprint arXiv:1211.3711 , 2012. [7] A. Grav es, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural netw orks, ” in 2013 IEEE international confer ence on acoustics, speech and signal pr ocessing . IEEE, 2013, pp. 6645–6649. [8] R. Prabhav alkar , K. Rao, T . N. Sainath, B. Li, L. Johnson, and N. Jaitly , “ A comparison of sequence-to-sequence models for speech recognition. ” in Interspeech , 2017, pp. 939–943. [9] W . Chan, N. Jaitly , Q. Le, and O. V inyals, “Listen, attend and spell: A neural network for large vocab ulary con versational speech recognition, ” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2016, pp. 4960–4964. [10] C.-C. Chiu, T . N. Sainath, Y . W u, R. Prabhavalkar , P . Nguyen, Z. Chen, A. Kannan, R. J. W eiss, K. Rao, E. Gonina et al. , “State- of-the-art speech recognition with sequence-to-sequence models, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 4774–4778. [11] K. Rao, H. Sak, and R. Prabhavalkar , “Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer , ” in 2017 IEEE A utomatic Speech Recognition and Understanding W orkshop (ASR U) . IEEE, 2017, pp. 193–199. [12] K. C. Sim, A. Narayanan, A. Misra, A. T ripathi, G. Pundak, T . N. Sainath, P . Haghani, B. Li, and M. Bacchiani, “Domain adaptation using factorized hidden layer for robust automatic speech recog- nition, ” Pr oc. Interspeech 2018 , pp. 892–896, 2018. [13] C. Wu and M. J. Gales, “Multi-basis adaptive neural network for rapid adaptation in speech recognition, ” in 2015 IEEE Interna- tional Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2015, pp. 4315–4319. [14] K. Mengistu and F . Rudzicz, “ Adapting acoustic and le xical mod- els to dysarthric speech, ” Pr oc. ICASSP 2011 , 2011. [15] S. Bansal, H. Kamper , K. Liv escu, A. Lopez, and S. Goldwater , “Pre-training on high-resource speech recognition improves low- resource speech-to-text translation, ” in Interspeech , 2018. [16] E. Yılmaz, V . Mitra, C. Bartels, and H. Franco, “ Articula- tory features for asr of pathological speech, ” arXiv preprint arXiv:1807.10948 , 2018. [17] M. B. Mustafa, S. S. Salim, N. Mohamed, B. Al-Qatab, and C. E. Siong, “Severity-based adaptation with limited data for asr to aid dysarthric speakers, ” PloS one , vol. 9, no. 1, p. e86285, 2014. [18] V . Delvaux, K. Huet, M. Piccaluga, S. V an Malderen, and B. Harmegnies, “T owards a better characterization of parkinso- nian speech: a multidimensional acoustic study , ” in Interspeech , 2018. [19] A. Hermes, J. Mertens, and D. M ¨ ucke, “ Age-related effects on sensorimotor control of speech production, ” Proc. Interspeech 2018 , pp. 1526–1530, 2018. [20] N. D. C. Blanco, M. Hoen, F . Meunier , and J. Meyer , “Phoneme resistance and phoneme confusion in noise: Impact of dyslexia, ” in InterSpeech 2018 , v ol. 2018, 2018. [21] N. Nonavinakere Prabhakera, P . Alku et al. , “Dysarthric speech classification using glottal features computed from non-words, words and sentences, ” in Interspeech , 2018. [22] V . Panayotov , G. Chen, D. Pov ey , and S. Khudanpur , “Lib- rispeech: an asr corpus based on public domain audio books, ” in 2015 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2015, pp. 5206–5210. [23] C. Danescu-Niculescu-Mizil and L. Lee, “Chameleons in imag- ined con versations: A new approach to understanding coordina- tion of linguistic style in dialogs, ” in Pr oceedings of the 2nd W ork- shop on Cognitive Modeling and Computational Linguistics . As- sociation for Computational Linguistics, 2011, pp. 76–87. [24] G. Zhao, S. Sonsaat, A. O. Silpachai, I. Lucic, E. Chukharev- Khudilaynen, J. Levis, and R. Gutierrez-Osuna, “L2-arctic: A non-nativ e english speech corpus, ” P er ception Sensing Instrumen- tation Lab , 2018. [25] H. Sak, A. Senior , K. Rao, and F . Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recognition, ” arXiv pr eprint arXiv:1507.06947 , 2015. [26] J. Shen, P . Nguyen, Y . W u, Z. Chen et al. , “Lingvo: a modular and scalable framew ork for sequence-to-sequence modeling, ” 2019. [27] “Google cloud speech api, ” https://cloud.google.com/ speech- to- text/. [28] J. Y osinski, J. Clune, Y . Bengio, and H. Lipson, “How trans- ferable are features in deep neural networks?” arXiv preprint arXiv:1411.1792 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment