WaveGlove: Transformer-based hand gesture recognition using multiple inertial sensors
💡 Research Summary
The paper introduces WaveGlove, a custom glove equipped with five inertial measurement units (IMUs), one on each finger, to explore the benefits of multi‑sensor hand gesture recognition (HGR). Two gesture vocabularies were defined: “WaveGlove‑single”, consisting of eight whole‑hand movements plus a null class, and “WaveGlove‑multi”, containing ten gestures that involve distinct motions of individual fingers. Using the glove, the authors collected over 1 000 samples for the single vocabulary and more than 10 000 samples for the multi vocabulary.
To place their work in context, the authors assembled a benchmark of eleven datasets, including the two newly created WaveGlove datasets, three publicly available HGR datasets (uWave, Opportunity, Skoda), and six HAR datasets previously normalized in the literature. All datasets were processed with a uniform pipeline: Leave‑One‑Trial‑Out (LOTO) cross‑validation, consistent windowing (overlapping for the six pre‑processed HAR sets, non‑overlapping for the others), and identical feature scaling. This standardization enables fair comparison across a wide range of classification methods.
The study reproduces several established approaches ranging from classical machine learning (Decision Tree, Baseline) to deep learning models such as DeepConV‑LSTM, DCNN ensembles, and bidirectional GRU/LSTM networks. In addition, the authors propose a novel Transformer‑based architecture tailored for inertial time‑series. The model first projects the raw B×T×S input (batch, time steps, sensor channels) into a 32‑dimensional embedding via a linear layer, adds sinusoidal positional encoding, and passes the sequence through four Transformer encoder layers (8 attention heads, dropout 0.2, feed‑forward dimension 128). A dot‑product attention mechanism uses the final temporal output as the query while attending over the entire sequence, and a final linear layer maps the result to class logits. Hyper‑parameters were selected through an extensive sweep.
Performance results (Table 1) show that the Transformer model achieves state‑of‑the‑art accuracy on most datasets. Notably, on the WaveGlove‑multi set it reaches 99.40 % accuracy, surpassing DeepConV‑LSTM (90.35 %). On the WaveGlove‑single set it also outperforms prior methods (99.40 % vs. 99.10 % for the best baseline). Across the eleven benchmark datasets, the Transformer consistently matches or exceeds the best published scores, confirming its robustness to varying sensor configurations and gesture complexities.
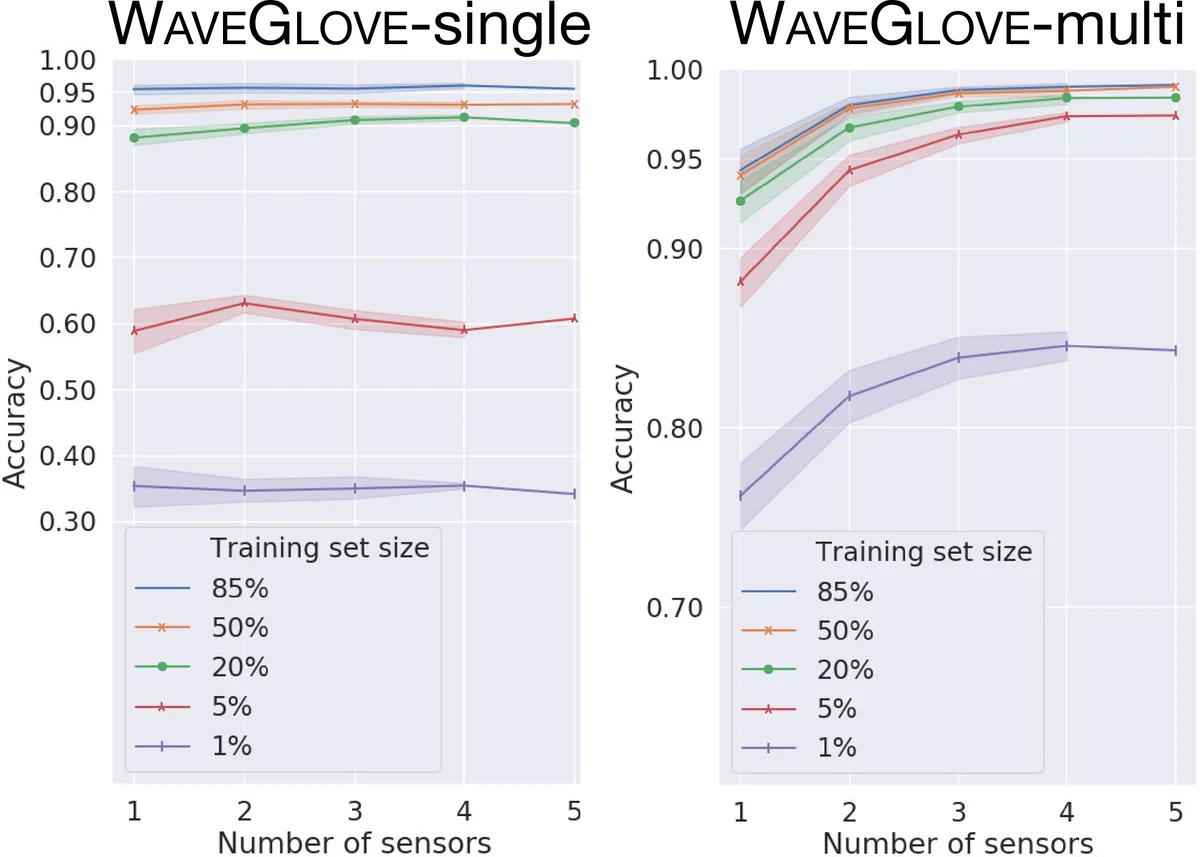
An ablation study investigates two key factors. First, training models on data from a single finger sensor reveals that sensor placement strongly influences confusion patterns: the index‑finger sensor fails to detect gestures that do not involve the index finger (e.g., “Metal”, “Peace”), while the pinky sensor confuses gestures lacking pinky movement. This demonstrates that different fingers contribute discriminative information for different gesture classes. Second, the authors vary the number of active sensors from one to five. For the simple “single” vocabulary, adding sensors yields negligible gains, as expected because the gestures involve uniform hand motion. In contrast, for the “multi” vocabulary, accuracy improves markedly up to three sensors and then plateaus, indicating diminishing returns beyond that point. The benefit of additional sensors is especially pronounced when the training set is small, suggesting that multi‑sensor data can compensate for limited sample sizes.
The paper’s contributions are threefold: (1) the design and public release of a multi‑IMU glove capable of capturing fine‑grained finger motions at a scale larger than any previously available HGR dataset; (2) the creation of a unified benchmark of eleven HAR/HGR datasets with standardized preprocessing, facilitating reproducible comparisons; and (3) the introduction of a streamlined Transformer architecture that achieves superior performance across diverse tasks. The authors suggest future work on modeling inter‑sensor correlations with graph neural networks, developing lightweight Transformer variants for real‑time on‑device inference, and exploring transfer‑learning strategies for personalized gesture vocabularies.
Comments & Academic Discussion
Loading comments...
Leave a Comment