OpTorch: Optimized deep learning architectures for resource limited environments
Deep learning algorithms have made many breakthroughs and have various applications in real life. Computational resources become a bottleneck as the data and complexity of the deep learning pipeline increases. In this paper, we propose optimized deep learning pipelines in multiple aspects of training including time and memory. OpTorch is a machine learning library designed to overcome weaknesses in existing implementations of neural network training. OpTorch provides features to train complex neural networks with limited computational resources. OpTorch achieved the same accuracy as existing libraries on Cifar-10 and Cifar-100 datasets while reducing memory usage to approximately 50%. We also explore the effect of weights on total memory usage in deep learning pipelines. In our experiments, parallel encoding-decoding along with sequential checkpoints results in much improved memory and time usage while keeping the accuracy similar to existing pipelines. OpTorch python package is available at available at https://github.com/cbrl-nuces/optorch
💡 Research Summary
The paper introduces OpTorch, a Python library that aims to make deep‑learning training feasible on hardware with limited computational resources. The authors focus on two orthogonal dimensions of optimization: data‑flow and gradient‑flow.
On the data‑flow side, OpTorch implements a parallel encoding‑decoding (E‑D) scheme that packs up to 16 (or 32 for float‑64) images into a single tensor of the original spatial dimensions. Each pixel is divided by 256 and stored as an integer, while an offset array records odd/even information, enabling loss‑less reconstruction. This compression reduces the memory footprint of a batch by up to 16×. The library also provides Selective‑Batch‑Sampling (SBS), which lets users control the class composition of each mini‑batch, facilitating class‑balanced augmentation (MixUp, CutMix, AugMix) and enabling a “forced loss‑less” mode that preserves full pixel fidelity.
For gradient‑flow optimization, three mechanisms are combined. First, mixed‑precision (MP) training stores model weights in FP16 but casts them to FP32 during loss and gradient computation, preserving numerical stability while halving weight memory. Second, sequential checkpointing (SC) stores only a small subset of intermediate activations during the forward pass; missing activations are recomputed on‑the‑fly during back‑propagation. This reduces activation memory dramatically at the cost of extra forward computations. Third, the library allows arbitrary combinations of MP, SC, and E‑D, giving users a single‑line API to select the desired trade‑off.
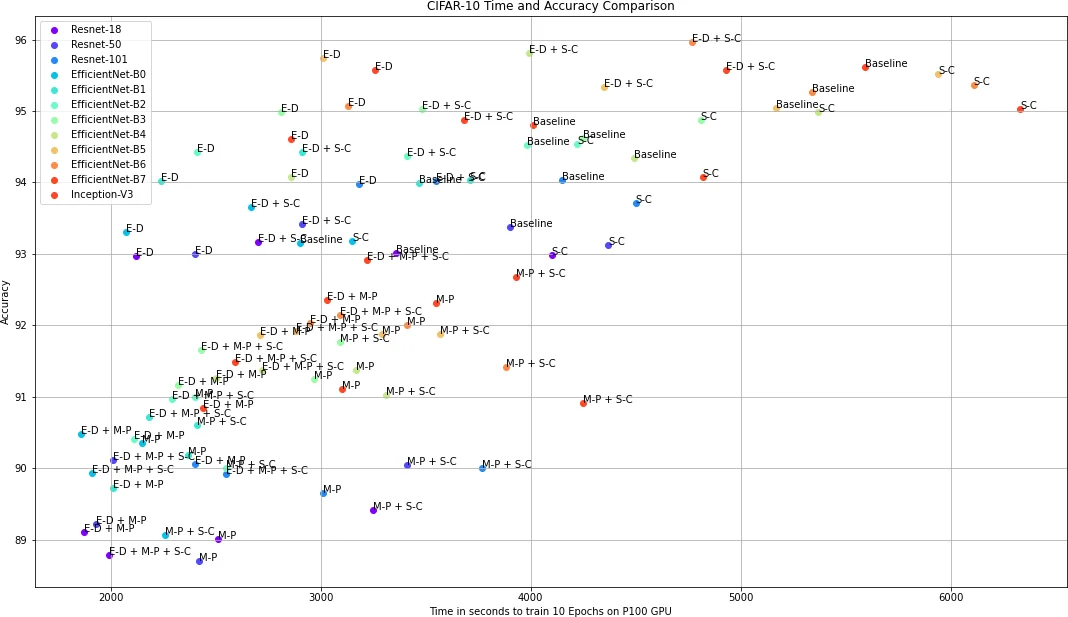
The experimental evaluation uses CIFAR‑10 and CIFAR‑100 with a suite of popular architectures: ResNet‑18/34/50/101, EfficientNet‑B0‑B7, and Inception‑V3. All models are trained on a single NVIDIA P100 GPU with batch size 16. Baseline (FP32, no optimizations) serves as a reference. Results show that SC alone cuts peak GPU memory from roughly 7 GB to 2 GB for ResNet‑18, a >70 % reduction, while accuracy drops by less than 0.2 %. Adding MP further halves weight memory and speeds up training by ~15 % because FP16 kernels are faster. The combination E‑D + SC yields the greatest memory savings (≈50 % of baseline) and also reduces wall‑clock time compared with the baseline, because the compressed batches are quicker to transfer and the reduced activation storage lessens GPU memory pressure. When all three techniques (MP + E‑D + SC) are used together, the authors report comparable accuracy to the baseline, a ~20 % reduction in training time, and a memory usage of under 1 GB for the largest EfficientNet‑B7 model.
A separate analysis of checkpoint placement in a simple 7‑layer network suggests that storing checkpoints at the first, an intermediate, and the final layer yields the best balance between memory savings and recomputation overhead.
Despite these promising numbers, the paper has several shortcomings. The encoding scheme is limited to a maximum of 16 (or 32) images per batch, which may not scale to high‑resolution datasets (e.g., ImageNet) or larger batch sizes commonly used in practice. The checkpointing strategy is manually configured; an automated algorithm that selects optimal checkpoint locations based on layer size or memory budget would be more practical. The experiments are confined to a single‑GPU environment; the authors do not demonstrate how OpTorch integrates with multi‑GPU or distributed training frameworks such as PyTorch Distributed, DeepSpeed, or ZeRO. Moreover, the comparison is only against a naïve baseline; recent memory‑saving features in mainstream libraries (e.g., torch.utils.checkpoint, gradient‑checkpointing in TensorFlow) are not evaluated, making it difficult to assess the relative advantage of OpTorch. Finally, reproducibility suffers because hyper‑parameters, exact checkpoint positions, and thread‑synchronization details are not fully disclosed, and the GitHub repository is referenced without a permanent archive or detailed documentation.
In summary, OpTorch presents a cohesive set of engineering tricks—mixed precision, selective checkpointing, and batch compression—that together enable training of relatively large convolutional networks on modest GPUs with minimal accuracy loss. The library’s single‑command interface is attractive for practitioners facing memory constraints. Future work should address scalability to higher‑resolution data, automated checkpoint selection, and thorough benchmarking against existing memory‑optimization tools in both single‑ and multi‑node settings. If these extensions are realized, OpTorch could become a valuable addition to the toolbox of deep‑learning researchers and engineers working in resource‑limited environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment