Explanation-Based Human Debugging of NLP Models: A Survey
📝 Abstract
Debugging a machine learning model is hard since the bug usually involves the training data and the learning process. This becomes even harder for an opaque deep learning model if we have no clue about how the model actually works. In this survey, we review papers that exploit explanations to enable humans to give feedback and debug NLP models. We call this problem explanation-based human debugging (EBHD). In particular, we categorize and discuss existing work along three dimensions of EBHD (the bug context, the workflow, and the experimental setting), compile findings on how EBHD components affect the feedback providers, and highlight open problems that could be future research directions.
💡 Analysis
Debugging a machine learning model is hard since the bug usually involves the training data and the learning process. This becomes even harder for an opaque deep learning model if we have no clue about how the model actually works. In this survey, we review papers that exploit explanations to enable humans to give feedback and debug NLP models. We call this problem explanation-based human debugging (EBHD). In particular, we categorize and discuss existing work along three dimensions of EBHD (the bug context, the workflow, and the experimental setting), compile findings on how EBHD components affect the feedback providers, and highlight open problems that could be future research directions.
📄 Content
머신러닝 모델을 디버깅하는 일은 매우 까다롭고 복합적인 작업이다. 그 근본적인 이유는 대부분의 버그가 모델이 학습에 사용한 데이터 자체 혹은 학습 과정에 내재해 있기 때문이다. 예를 들어, 학습 데이터에 라벨링 오류가 포함되어 있거나, 데이터 분포가 실제 서비스 환경과 크게 차이 나는 경우, 혹은 학습 단계에서 과도한 과적합(over‑fitting)이나 그래디언트 소실·폭발과 같은 최적화 문제에 봉착했을 때 모델은 기대와 전혀 다른 출력을 생성한다. 이러한 문제를 발견하고 원인을 추적하려면 데이터 파이프라인을 면밀히 검토하고, 학습 로그와 손실 곡선을 분석하며, 필요에 따라 모델의 내부 파라미터를 직접 살펴보는 등 여러 단계의 정밀 검증이 요구된다.
특히 불투명(opaque)한 딥러닝 모델—예컨대 수백 개 이상의 레이어와 수억 개의 파라미터를 가진 대규모 신경망—의 경우, 모델이 입력을 어떻게 처리하고 최종 예측을 도출하는지에 대한 직관적인 이해가 거의 불가능하다. 이러한 ‘블랙박스’ 특성 때문에, 모델 내부에서 어떤 특징(feature)이 어떤 방식으로 결합되어 오류를 일으키는지 파악하기가 더욱 어려워진다. 따라서 모델의 동작 메커니즘에 대한 전혀 단서가 없는 상황에서는 디버깅 자체가 거의 불가능에 가깝다고 할 수 있다.
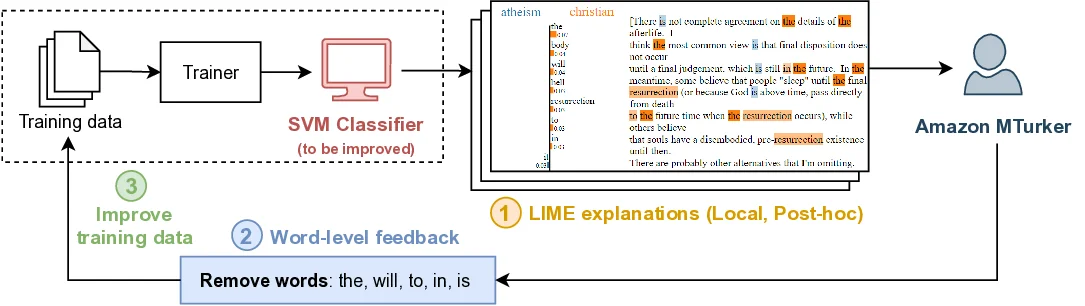
이러한 난관을 극복하고자 최근 연구자들은 설명(explanation) 기법을 활용하여 인간 사용자가 모델의 판단 근거를 직관적으로 파악하고, 그 위에 피드백(feedback) 을 제공함으로써 모델을 수정·보완하는 방법을 모색하고 있다. 설명 기법에는 입력‑출력 관계를 시각화하는 saliency map, 각 토큰이나 단어가 예측에 미치는 영향을 정량화하는 attention weight 시각화, 특정 특징의 중요도를 나타내는 feature importance 점수, 그리고 모델 내부의 중간 표현을 인간이 이해할 수 있는 형태로 변환하는 layer‑wise relevance propagation 등 다양한 접근이 포함된다. 이러한 설명을 기반으로 인간은 “이 부분은 잘못된 근거에 의해 결정되었다”, “이 라벨은 데이터 오류가 있다”와 같은 구체적인 수정 제안을 할 수 있게 된다.
본 설문(survey)에서는 설명을 활용해 인간이 직접 피드백을 제공하고 자연어 처리(NLP) 모델을 디버깅하도록 돕는 연구들을 체계적으로 검토한다. 우리는 이러한 연구 흐름을 **‘설명 기반 인간 디버깅(Explanation‑Based Human Debugging, 이하 EBHD)’**이라는 용어로 통합하고, 기존 문헌을 세 가지 주요 차원—버그가 발생한 맥락(bug context), 디버깅 작업 흐름(workflow), 그리고 실험 설정(experimental setting)—에 따라 분류·분석하였다.
버그 컨텍스트(bug context)
- 데이터 편향(data bias): 학습 코퍼스에 특정 사회적·문화적 편향이 내재되어 있어 모델이 특정 그룹에 대해 부당한 예측을 하는 경우.
- 라벨링 오류(label noise): 인간 주석자가 실수하거나 모호한 기준으로 라벨을 부여해 발생하는 오류.
- 모델 구조 결함(model architecture flaw): 설계 단계에서 선택된 레이어 구성이나 활성화 함수가 특정 유형의 입력에 대해 비효율적으로 작동하는 경우.
- 학습 파라미터 설정(learning‑parameter mis‑specification): 학습률, 배치 크기, 정규화 기법 등이 부적절하게 설정돼 최적화가 제대로 이루어지지 않는 상황.
워크플로우(workflow)
- 단일‑라운드 인터랙션(single‑round interaction): 사용자가 한 번의 설명을 보고 즉시 피드백을 제공하고, 그 피드백을 반영한 모델이 바로 재학습되는 방식.
- 다중‑라운드 반복(iterative multi‑round loop): 설명을 기반으로 피드백을 주고받으며, 매 라운드마다 모델이 업데이트되고 새로운 설명이 생성되는 반복적 프로세스.
- 시뮬레이션 기반 디버깅(simulation‑driven debugging): 실제 인간 대신 사전 정의된 규칙이나 자동화된 에이전트를 이용해 피드백을 생성하고, 그 효과를 실험적으로 검증하는 접근.
- 크라우드소싱(crowdsourcing) 참여: 다수의 비전문가 혹은 전문가 집단에게 설명을 제시하고, 그들의 의견을 집계해 모델 수정에 활용하는 방식.
실험 설정(experimental setting)
- 실험실 실험(lab study): 제한된 인원에게 통제된 환경에서 설명과 피드백 과정을 수행하게 하여 정밀한 행동 데이터를 수집.
- 온라인 사용자 연구(online user study): 웹 기반 인터페이스를 통해 대규모 사용자에게 실시간으로 설명을 제공하고, 그들의 피드백을 기록.
- 시뮬레이션 평가(simulation evaluation): 실제 인간 대신 사전 구축된 시뮬레이터가 피드백을 제공하도록 설계해, 다양한 변수(예: 설명 정확도, 피드백 비용 등)의 영향을 정량적으로 분석.
- 다중 도메인 테스트(multi‑domain testing): 동일한 EBHD 프레임워크를 텍스트 분류, 기계 번역, 질의응답 등 서로 다른 NLP 태스크에 적용해 일반화 가능성을 검증.
위와 같은 차원별 분류를 바탕으로 우리는 EBHD 구성 요소가 피드백 제공자에게 미치는 영향에 대한 주요 발견을 정리하였다. 구체적으로,
- 설명의 형태와 상세 수준이 피드백 제공자의 **신뢰도(trust)**와 **이해도(comprehension)**에 결정적인 역할을 한다는 점을 여러 연구가 보고하였다. 예를 들어, 단순히 “핵심 단어에 높은 가중치가 부여됨”이라는 설명보다, 해당 단어가 왜 중요한지 언어학적 근거와 함께 제시될 때 사용자는 더 정확하고 구체적인 수정 제안을 할 가능성이 높다.
- 인터랙션 라운드 수가 증가할수록 초기 피드백의 **노이즈(noise)**가 감소하고, 최종 모델 성능이 향상되는 경향이 관찰되었다. 다만 라운드가 지나치게 많아지면 **사용자 피로도(fatigue)**가 급격히 상승해 피드백 품질이 오히려 저하될 수 있다는 트레이드오프도 동시에 보고되었다.
- 실험 환경에 따라 피드백 제공자의 동기 부여와 행동 양식이 크게 달라졌다. 실험실 내에서는 보상과 명확한 과제 지시가 높은 참여도를 이끌어냈지만, 온라인 환경에서는 자율성과 즉각적인 시각적 피드백이 더 큰 영향을 미쳤다.
마지막으로, 현재까지 밝혀진 **열린 문제(open problems)**와 향후 연구 방향을 다음과 같이 정리한다.
- 설명의 스케일러빌리티(scalability): 대규모 사전학습 언어 모델에 대해 실시간으로 의미 있는 설명을 생성하고, 이를 인간이 효율적으로 소비할 수 있는 방법이 아직 부족하다.
- 피드백 평가 메트릭스(feedback evaluation metrics): 인간이 제공한 피드백이 실제 모델 개선에 얼마나 기여했는지를 정량화할 수 있는 표준화된 지표가 부재하다.
- 다중 모달(multi‑modal) 설명: 텍스트뿐 아니라 이미지, 오디오 등 복합 입력을 다루는 모델에 대해 통합적인 설명을 제공하고, 이를 기반으로 인간이 피드백을 주는 방법론이 필요하다.
- 사용자 모델링(user modeling): 피드백 제공자의 전문성, 선호도, 인지적 한계 등을 고려한 맞춤형 인터페이스 설계가 아직 초기 단계에 머물러 있다.
- 윤리·공정성(equity & ethics): 설명을 통해 드러난 편향을 수정하는 과정에서 새로운 불공정이 발생하지 않도록 하는 윤리적 가이드라인이 요구된다.
요약하면, 머신러닝 특히 딥러닝 기반 NLP 모델의 디버깅은 데이터·학습·모델 구조라는 복합적인 원인에 의해 복잡성을 띤다. 설명을 매개로 인간이 직접 피드백을 제공하도록 하는 설명 기반 인간 디버깅(EBHD) 접근은 이러한 복잡성을 완화시키는 유망한 길이며, 본 설문은 EBHD를 버그 컨텍스트, 워크플로우, 실험 설정이라는 세 축으로 체계화함으로써 현재 연구 흐름을 조망하고, 향후 연구가 집중해야 할 핵심 과제들을 제시한다. 이러한 통합적 시각은 학계·산업 모두가 보다 투명하고 신뢰할 수 있는 NLP 시스템을 구축하는 데 중요한 이정표가 될 것으로 기대된다.