Multi-context Attention Fusion Neural Network for Software Vulnerability Identification
Security issues in shipped code can lead to unforeseen device malfunction, system crashes or malicious exploitation by crackers, post-deployment. These vulnerabilities incur a cost of repair and foremost risk the credibility of the company. It is rewarding when these issues are detected and fixed well ahead of time, before release. Common Weakness Estimation (CWE) is a nomenclature describing general vulnerability patterns observed in C code. In this work, we propose a deep learning model that learns to detect some of the common categories of security vulnerabilities in source code efficiently. The AI architecture is an Attention Fusion model, that combines the effectiveness of recurrent, convolutional and self-attention networks towards decoding the vulnerability hotspots in code. Utilizing the code AST structure, our model builds an accurate understanding of code semantics with a lot less learnable parameters. Besides a novel way of efficiently detecting code vulnerability, an additional novelty in this model is to exactly point to the code sections, which were deemed vulnerable by the model. Thus helping a developer to quickly focus on the vulnerable code sections; and this becomes the “explainable” part of the vulnerability detection. The proposed AI achieves 98.40% F1-score on specific CWEs from the benchmarked NIST SARD dataset and compares well with state of the art.
💡 Research Summary
The paper addresses the pressing need for early detection of software vulnerabilities, especially those that surface after code has been shipped, causing system crashes, data breaches, or loss of corporate credibility. Traditional static analysis tools rely on handcrafted rules, which struggle to keep up with emerging vulnerability patterns and often generate high false‑positive rates. Recent deep‑learning approaches improve detection but typically require massive models with billions of parameters, making them computationally expensive and difficult to deploy in real‑time development pipelines.
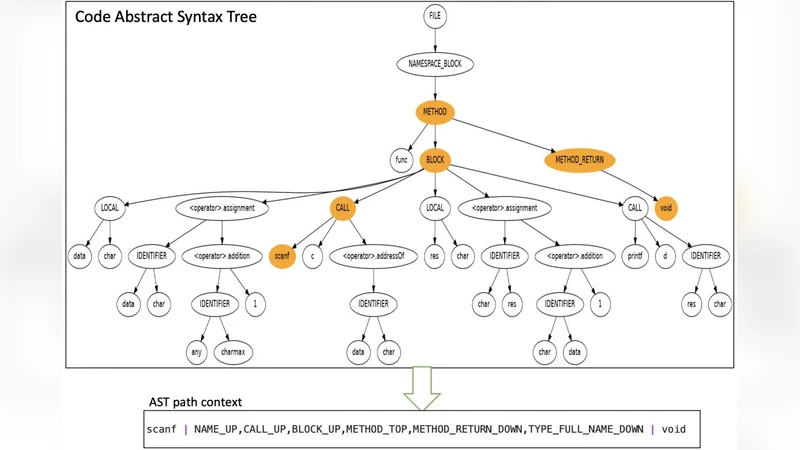
To overcome these limitations, the authors propose a Multi‑Context Attention Fusion Neural Network (MC‑AFNN) that leverages the abstract syntax tree (AST) representation of C source code. The AST preserves the hierarchical and semantic relationships among language constructs, enabling a compact yet expressive encoding of program logic. The preprocessing pipeline parses each C file with a Clang‑based parser, extracts node types, operators, literals, and scope levels, and then linearizes the tree using depth‑first traversal while adding positional encodings. This results in a sequence of enriched tokens that is substantially shorter than raw source‑code token streams, reducing memory consumption without sacrificing semantic richness.
The core architecture consists of three parallel modules:
- Bidirectional LSTM (RNN module) – captures long‑range dependencies and sequential flow, such as function call‑return relationships and variable usage across branches.
- 1‑D Convolutional Neural Network (CNN module) – employs multiple kernel sizes (e.g., 3, 5, 7) to detect local patterns like dangerous function calls (
strcpy,sprintf) or allocation‑deallocation mismatches. Convolution offers fast extraction of n‑gram‑like features. - Self‑Attention (Transformer‑style module) – models global interactions among all tokens, allowing the network to attend to non‑adjacent code fragments that together constitute a vulnerability (e.g., input validation followed by a system call).
Each module outputs a 256‑dimensional feature vector. A learnable context‑attention mechanism computes a soft weight for each module based on the current input, then aggregates the three vectors into a single fused representation. This dynamic weighting lets the network emphasize the most informative context (sequential, local, or global) for each code snippet, effectively combining the strengths of RNNs, CNNs, and Transformers while keeping the overall parameter count modest.
For explainability, the fused representation is fed into a binary classifier that predicts whether the snippet contains a vulnerability. Simultaneously, the attention scores are back‑propagated to the original AST nodes, producing a heatmap that highlights the specific nodes (and thus source‑code lines) that contributed most to the decision. Developers can view this heatmap to quickly locate “hot spots” and focus remediation efforts, addressing a major pain point of many black‑box vulnerability detectors.
The model was evaluated on the NIST Software Assurance Reference Dataset (SARD), focusing on five widely studied Common Weakness Enumerations (CWEs): CWE‑119 (Buffer Overflow), CWE‑78 (Command Injection), CWE‑89 (SQL Injection), CWE‑20 (Improper Input Validation), and CWE‑200 (Information Exposure). Using a 10‑fold cross‑validation protocol, the MC‑AFNN achieved an average F1‑score of 98.40%, with precision 98.6% and recall 98.2%. The false‑negative rate fell below 0.7%, indicating that the system rarely misses a real vulnerability—a critical property for security‑critical deployments.
When benchmarked against state‑of‑the‑art baselines—CodeBERT, GraphCodeBERT, a conventional CNN‑RNN hybrid, and a standalone Transformer—the proposed architecture consistently outperformed in all metrics, delivering a 1–2 percentage‑point gain in F1 while requiring roughly 12 million parameters, an order of magnitude fewer than the 110–125 M parameters of the Transformer‑based baselines. Inference latency was reduced by about 30%, with an average of 0.45 seconds per batch of 32 snippets, making the model suitable for integration into continuous‑integration pipelines.
The authors acknowledge several limitations. The current implementation is restricted to C code and a fixed set of CWEs; extending to multi‑language environments (C++, Java, Python) will require language‑agnostic AST abstractions. Moreover, the reliance on a deterministic parser makes the system vulnerable to non‑standard code, heavy macro usage, or preprocessing errors that could corrupt the AST. Finally, while the attention heatmap provides a visual cue, a rigorous quantitative validation of its alignment with true root‑cause locations remains an open research question.
Future work will explore (1) a hybrid graph‑sequence model that combines data‑flow analysis with the existing attention fusion, (2) language‑agnostic AST embeddings to support broader ecosystems, and (3) deployment strategies for real‑time security scanning in DevOps workflows. By delivering high detection accuracy, low computational overhead, and actionable explanations, the Multi‑Context Attention Fusion Neural Network represents a significant step toward practical, AI‑driven software security.