Multiple regression techniques for modeling dates of first performances of Shakespeare-era plays
💡 Research Summary
The paper tackles the longstanding problem of dating Shakespeare‑era plays, focusing on the year of first public performance—a crucial chronological marker for literary historians. The authors assembled a corpus of 285 English plays from the 16th and 17th centuries, then narrowed it to 181 plays whose best‑guess first‑performance dates fall between 1585 and 1610, a period that contains the bulk of surviving works. Each text was manually standardized for spelling using the VARD tool, because early modern English exhibits extreme orthographic variation that would otherwise inflate the dimensionality of word‑frequency features. The texts were also encoded in TEI‑P4 XML, allowing the authors to separate dialogue from stage directions, prefaces, and other non‑spoken material. A small set of homographs (e.g., “that” used as conjunction, relative pronoun, or demonstrative) were tagged with part‑of‑speech information, yielding 48 distinct lexical forms for counting.
The dependent variable is the “best‑guess” first‑performance year taken from the multi‑volume Catalogue of British Drama 1533‑1642. The independent variables are raw word‑type frequencies (including function words) drawn from a vocabulary of 51 183 items; the authors deliberately avoided the usual stop‑word removal to preserve potentially informative high‑frequency terms. Because the feature space is massive, the study applies two heuristic feature‑selection strategies.
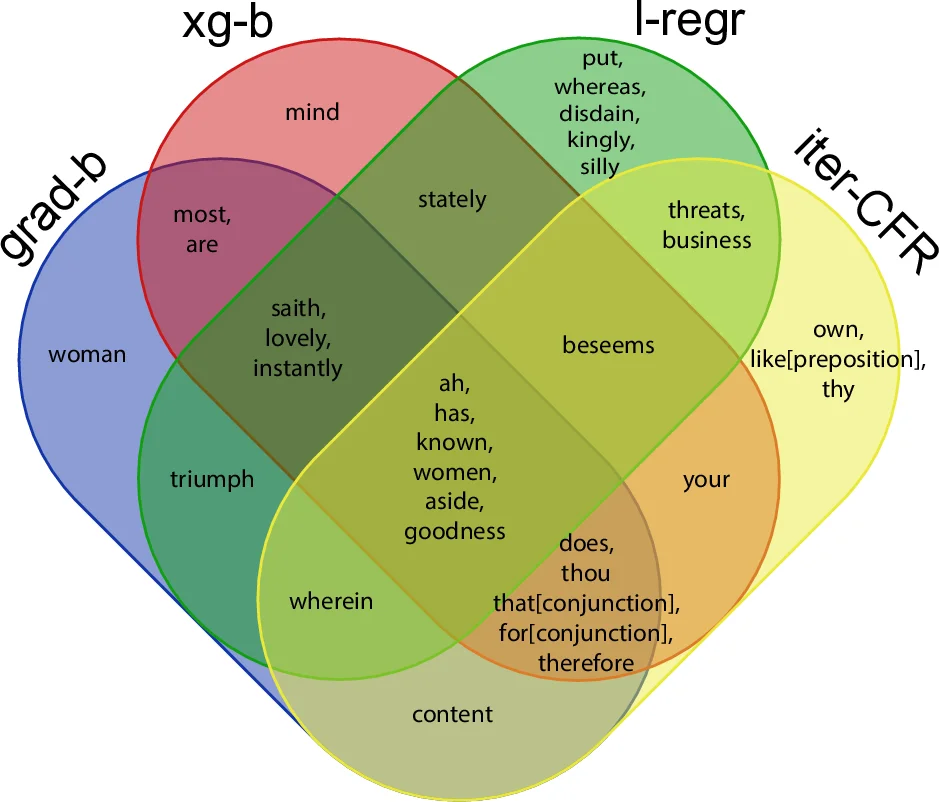
First, Lasso (L1‑regularized linear regression) is run on 100 random 80 % training subsets. With λ = 1, the Lasso consistently selects a core set of 14 words (e.g., “and”, “a”, “you”, “thou”, “thy”) that appear in at least 90 % of the trials. These words also rank among the top 50 by Pearson correlation with performance year, confirming their relevance. Lasso provides a sparse linear baseline and serves as a benchmark for more sophisticated models.
Second, the authors introduce Continued Fraction Regression (CFR), a non‑linear regression framework that represents the model as a finite continued fraction. To search the enormous space of possible fractions, they employ a memetic algorithm—a hybrid of a population‑based genetic algorithm and a local improvement (greedy) phase. CFR treats the regression problem as a combinatorial optimization task, iteratively refining both the structure of the fraction and the coefficients assigned to selected words. Across 100 independent runs, CFR typically converges on models that use fewer than 20 words while achieving superior predictive performance.
Model evaluation follows a standard 80 %/20 % train‑test split and a leave‑one‑out cross‑validation scheme. Performance metrics include Mean Absolute Error (MAE) and the coefficient of determination (R²). Compared against nine conventional regressors (ordinary least squares, Ridge, Support Vector Regression, Random Forest, Gradient Boosting, etc.), both Lasso and CFR outperform the baselines, with CFR achieving the best results (R² ≈ 0.78, MAE ≈ 2.3 years). This indicates that a compact, interpretable set of lexical cues can reliably approximate the year of a play’s first performance.
Beyond pure prediction, the authors conduct an interpretive analysis of the most frequently selected words in the CFR models. High‑frequency pronouns and archaic verb forms such as “thou”, “thy”, and “sir” show strong positive correlations with earlier dates, reflecting the gradual shift toward more modern pronouns (“you”, “your”) in later years. Moreover, by grouping plays into genres (tragedy, comedy, history), the study finds genre‑specific lexical signatures—for example, “king” and “queen” dominate historical dramas, while “love” and “laugh” are prevalent in comedies. This suggests that the linguistic evolution captured by the models is not merely temporal but also stylistic.
The paper acknowledges several limitations. Manual spelling regularization, while improving consistency, may erase subtle orthographic signals that carry chronological information. The dataset is unevenly distributed across years, with early decades under‑represented, potentially biasing the models toward later periods. Finally, the reliance on a single external metadata source (the Catalogue) means that uncertainties in those “best‑guess” dates propagate into the training labels.
Future work is proposed along three lines: (1) expanding the corpus to include more plays and other dramatic forms (e.g., masques, interludes) to improve temporal coverage; (2) integrating multimodal features such as stage directions, musical cues, and even visual reconstructions of performance spaces; (3) adopting Bayesian hierarchical models to explicitly quantify uncertainty in both the lexical predictors and the target dates.
In sum, the study demonstrates that modern multivariate regression techniques—particularly a memetic‑algorithm‑driven continued fraction approach—can produce accurate, low‑dimensional, and interpretable models for dating early modern drama. This contributes a quantitative tool to literary scholarship, offering a data‑driven complement to traditional philological dating methods.
Comments & Academic Discussion
Loading comments...
Leave a Comment