Enhancing Virtual Ontology Based Access over Tabular Data with Morph-CSV
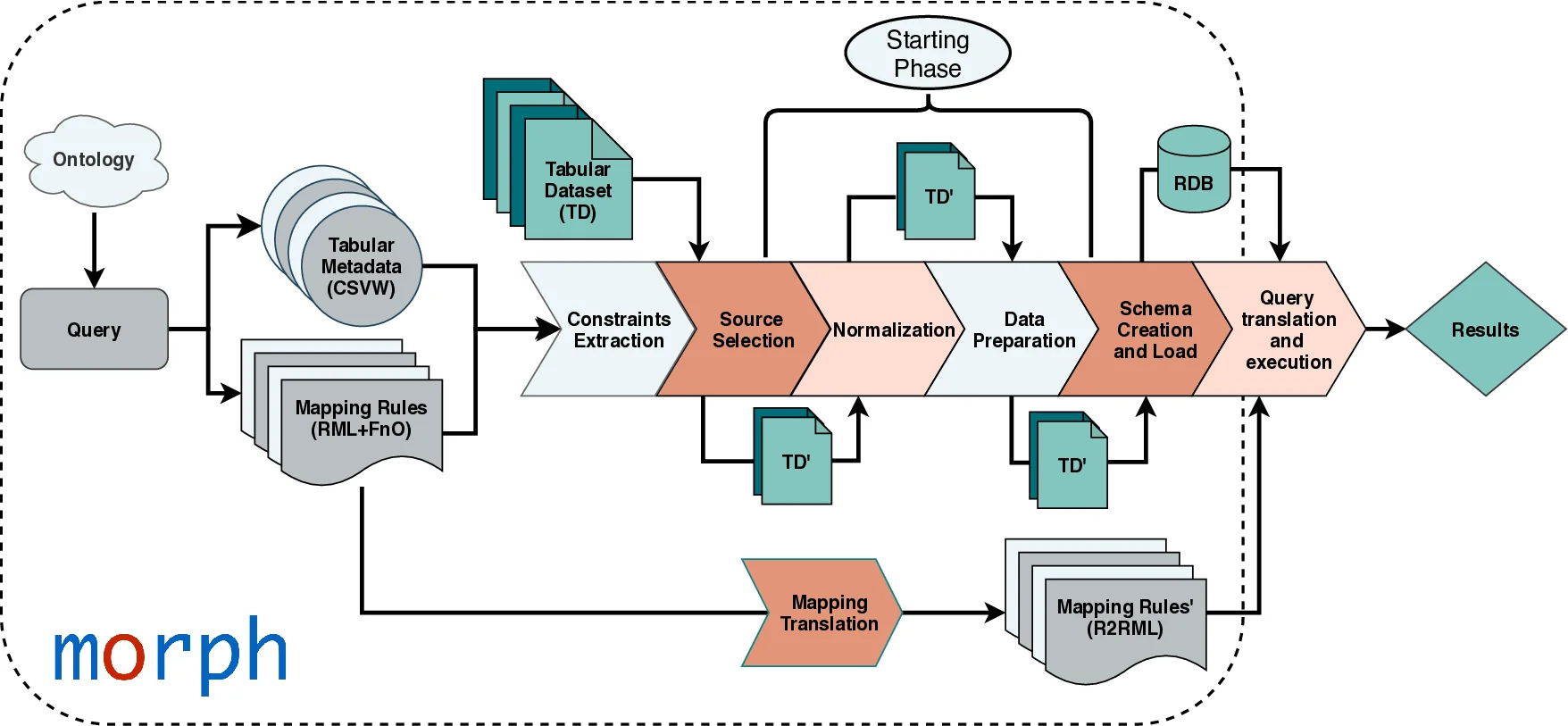
Ontology-Based Data Access (OBDA) has traditionally focused on providing a unified view of heterogeneous datasets, either by materializing integrated data into RDF or by performing on-the fly querying via SPARQL query translation. In the specific case of tabular datasets represented as several CSV or Excel files, query translation approaches have been applied by considering each source as a single table that can be loaded into a relational database management system (RDBMS). Nevertheless, constraints over these tables are not represented; thus, neither consistency among attributes nor indexes over tables are enforced. As a consequence, efficiency of the SPARQL-to-SQL translation process may be affected, as well as the completeness of the answers produced during the evaluation of the generated SQL query. Our work is focused on applying implicit constraints on the OBDA query translation process over tabular data. We propose Morph-CSV, a framework for querying tabular data that exploits information from typical OBDA inputs (e.g., mappings, queries) to enforce constraints that can be used together with any SPARQL-to-SQL OBDA engine. Morph-CSV relies on both a constraint component and a set of constraint operators. For a given set of constraints, the operators are applied to each type of constraint with the aim of enhancing query completeness and performance. We evaluate Morph-CSV in several domains: e-commerce with the BSBM benchmark; transportation with a benchmark using the GTFS dataset from the Madrid subway; and biology with a use case extracted from the Bio2RDF project. We compare and report the performance of two SPARQL-to-SQL OBDA engines, without and with the incorporation of MorphCSV. The observed results suggest that Morph-CSV is able to speed up the total query execution time by up to two orders of magnitude, while it is able to produce all the query answers.
💡 Research Summary
The paper addresses a critical gap in virtual Ontology‑Based Data Access (OBDA) when the underlying data sources are tabular files such as CSV or Excel. Traditional virtual OBDA systems assume that the relational schema of the sources contains primary‑key, foreign‑key, datatype and index information. In practice, tabular datasets lack these constraints, which leads to two major problems: (1) the SPARQL‑to‑SQL translation may produce incomplete answer sets because multi‑valued cells are treated as atomic strings and datatype mismatches prevent correct joins; (2) the lack of indexes and key constraints prevents the query optimizer from generating efficient execution plans, often resulting in full‑table scans and long response times.
To solve this, the authors introduce the concept of a Virtual Tabular Dataset (VTD) and propose Morph‑CSV, a framework that automatically extracts implicit constraints from standard metadata annotations (CSVW, RML, RML+FnO) and from the mapping files themselves. Morph‑CSV operates in four stages: (i) constraint generation – identifying candidate primary keys, foreign keys, data types, and normalization rules for multi‑valued columns; (ii) source and attribute selection – determining which tables and columns are actually needed for a given SPARQL query; (iii) preprocessing – normalizing multi‑valued cells, harmonizing date and numeric formats, and removing duplicate rows; (iv) physical schema creation – loading the cleaned data into a relational DBMS while automatically creating the identified primary‑key, foreign‑key constraints and appropriate indexes.
Because the framework is engine‑agnostic, it can be placed on top of any SPARQL‑to‑SQL translator. The authors integrated Morph‑CSV with two well‑known open‑source OBDA engines, Morph‑RDB and Ontop, and evaluated the combined system on three domains: (a) the Berlin SPARQL Benchmark (BSBM) for e‑commerce, (b) a GTFS‑Madrid benchmark that models bus and metro schedules, and (c) a real‑world Bio2RDF use case involving gene and protein data. Across 30+ queries, the results show that (1) query execution time is reduced by one to two orders of magnitude (average speed‑up of 10×–100×); (2) answer completeness is restored, especially for queries that rely on normalized date fields or multi‑valued attributes; and (3) the number of rows scanned drops dramatically due to the presence of indexes and proper key constraints.
The paper’s contributions are threefold: (1) a formal definition of VTD that aligns with existing OBDA frameworks; (2) a set of constraint operators that can be applied automatically to any tabular source, thereby improving both completeness and performance; (3) an extensive empirical evaluation demonstrating that the approach works with different OBDA engines and across heterogeneous domains. The authors also discuss the current limitations of CSVW and RML standards, which do not yet provide a comprehensive way to declare constraints, and they call for future work on extending these standards, supporting schema evolution, and integrating version control for tabular data.
In summary, Morph‑CSV offers a practical, non‑intrusive solution that bridges the gap between the simplicity of open‑data CSV files and the rigorous requirements of virtual OBDA systems. By automatically generating and enforcing relational constraints, it enables existing SPARQL‑to‑SQL engines to produce complete, correct results while achieving substantial performance gains, thus making large‑scale, open‑government and scientific tabular datasets far more accessible to data scientists and application developers.
Comments & Academic Discussion
Loading comments...
Leave a Comment