ODT FLOW: A Scalable Platform for Extracting, Analyzing, and Sharing Multi-source Multi-scale Human Mobility
💡 Research Summary
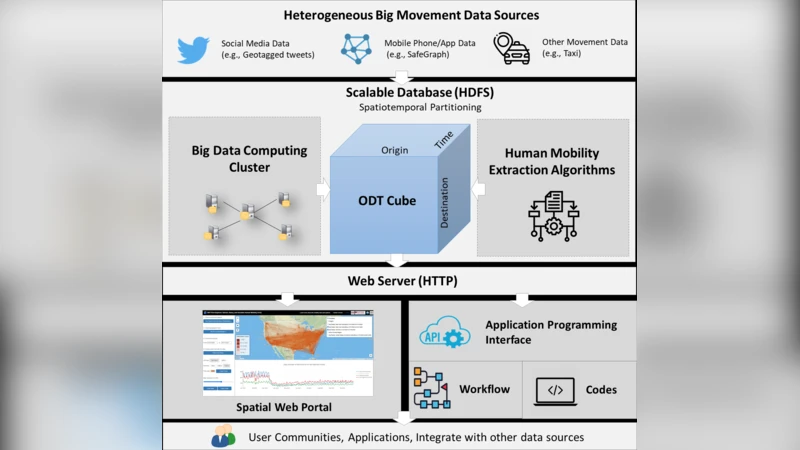
The paper presents ODT FLOW, a scalable online platform designed to extract, analyze, and share multi‑source, multi‑scale human mobility data, a need that became especially urgent during the COVID‑19 pandemic. At its core lies the Origin‑Destination‑Time (ODT) data model, which extends traditional space‑time cubes by treating origin and destination as separate dimensions alongside time. This model enables the storage of billions of OD cells and supports on‑the‑fly aggregation at arbitrary spatial and temporal resolutions.
The system architecture comprises five layers: (1) data‑source layer that ingests heterogeneous mobility streams such as geotagged Twitter posts, SafeGraph mobile device metrics, and transportation records; (2) processing and management layer that leverages a Hadoop Distributed File System (HDFS) for scalable storage, Hive/Impala for parallel SQL‑like queries, and Esri GIS Tools for Hadoop to perform massive point‑in‑polygon operations; (3) web‑server layer; (4) user‑interface layer featuring the ODT Flow Explorer, an interactive map‑based portal where users can define spatial extents and time windows, visualize OD flows, and download results; and (5) community layer that encourages reuse through RESTful APIs.
To build the ODT cube, the authors first construct a 4‑D entity‑origin‑destination‑time cube for each data source. For Twitter, they extract daily single‑day and cross‑day movements at the user level, filter out bot accounts, and record each user’s origin and destination per day. For SafeGraph, they use the Social Distancing Metrics to derive daily flows from anonymized mobile devices. These individual cubes are then aggregated along origin, destination, and time dimensions, producing three derived matrices: OD (origin‑destination), DT (destination‑time) and OT (origin‑time). Spatial aggregation can be performed on demand or pre‑computed and cached, allowing rapid queries across scales from census tracts to national levels.
The platform addresses the classic “5 Vs” of big mobility data: Volume (billions of records stored in HDFS), Velocity (real‑time or near‑real‑time ingestion and query), Variety (standardized ODT representation across heterogeneous sources), Veracity (fusion of multiple sources mitigates bias, while source‑specific cleaning improves data quality), and Value (provides actionable insights for disaster management, urban planning, and epidemic modeling). By exposing REST APIs, ODT FLOW enables programmatic access from scientific workflows, Jupyter notebooks, and custom applications, thereby enhancing reproducibility and replicability of mobility studies.
Demonstrations illustrate how researchers can retrieve custom OD slices, integrate them into epidemiological models, or visualize temporal flow patterns directly in a notebook. The open‑source stack (Cloudera Distribution Hadoop, Hive, Impala, Esri tools) can be deployed on-premise or in cloud environments, and the modular design permits future incorporation of additional data streams (e.g., cellular network logs, ride‑hailing records).
In summary, ODT FLOW offers a comprehensive, extensible solution for handling massive, multi‑source human mobility data. Its ODT cube model, parallel processing pipeline, interactive web portal, and programmable APIs together provide a powerful infrastructure for researchers and policymakers to monitor, analyze, and share mobility dynamics quickly and reliably during both routine and crisis situations.
Comments & Academic Discussion
Loading comments...
Leave a Comment