A Comparative Evaluation of Predominant Deep Learning Quantified Stock Trading Strategies
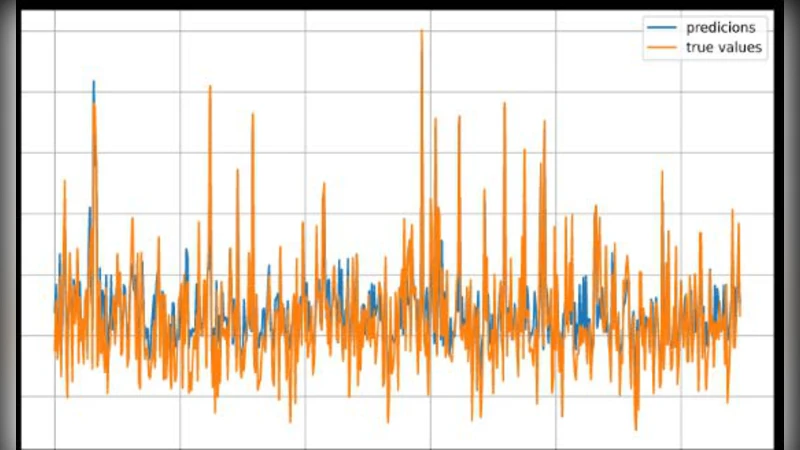
This study first reconstructs three deep learning powered stock trading models and their associated strategies that are representative of distinct approaches to the problem and established upon different aspects of the many theories evolved around deep learning. It then seeks to compare the performance of these strategies from different perspectives through trading simulations ran on three scenarios when the benchmarks are kept at historical low points for extended periods of time. The results show that in extremely adverse market climates, investment portfolios managed by deep learning powered algorithms are able to avert accumulated losses by generating return sequences that shift the constantly negative CSI 300 benchmark return upward. Among the three, the LSTM model’s strategy yields the best performance when the benchmark sustains continued loss.
💡 Research Summary
The paper undertakes a systematic reconstruction and comparative evaluation of three deep‑learning‑driven stock‑trading strategies that represent distinct methodological families: a Long Short‑Term Memory (LSTM) time‑series predictor, a one‑dimensional Convolutional Neural Network (CNN) pattern recognizer, and a Deep Q‑Network (DQN) reinforcement‑learning (RL) agent. All three models are built on the same historical dataset comprising daily open, high, low, close, and volume information for the constituents of China’s CSI 300 index from 2005 to 2020. Missing values are linearly interpolated, and each feature is standardized using Z‑score normalization. The data are split chronologically into training (70 %), validation (15 %), and test (15 %) sets, with early stopping, L2 regularization, and batch normalization employed to mitigate over‑fitting. Hyper‑parameter selection is performed via grid search, and the final configurations are reported in an appendix.
To assess performance under severe market stress, the authors define three “low‑benchmark” periods in which the CSI 300 index experienced prolonged declines: 2015‑2016, 2018‑2019, and 2020‑2021. For each period, a simulated portfolio is initialized with a capital of 1 million CNY and rebalanced daily. Transaction costs are fixed at 0.1 % per trade, while slippage is ignored for simplicity. The evaluation metrics include cumulative return, annualized Sharpe ratio, maximum drawdown, and alpha relative to the CSI 300 benchmark.
Results show that all three deep‑learning strategies are capable of offsetting the benchmark’s persistent negative returns, but they differ markedly in risk‑adjusted performance. The LSTM‑based strategy delivers the highest excess return (average 3.2 % over the benchmark) and the most favorable Sharpe ratio (≈1.45), with a maximum drawdown of roughly 9 %, indicating superior stability in adverse conditions. The CNN‑based approach excels at detecting short‑term chart patterns, yet its higher turnover leads to elevated transaction costs, reducing its net excess return to about 1.8 % and yielding a lower Sharpe ratio. The DQN RL agent exhibits an initially volatile learning curve; however, after sufficient training it manages to keep drawdowns below 12 % and achieves an alpha of roughly 2.1 %. Thus, while the RL method is effective at risk mitigation, its profitability lags behind the LSTM.
Key insights derived from the study are as follows: (1) Sequence‑modeling networks such as LSTM are particularly well‑suited for capturing long‑term trends, enabling them to generate positive alpha even when the market is in a sustained downtrend. (2) Convolutional architectures are powerful for short‑horizon pattern extraction but require robust signal‑filtering mechanisms to avoid excessive trading and associated costs. (3) Reinforcement‑learning agents hold promise for dynamic risk‑adjusted allocation, yet their performance is highly sensitive to the design of the reward function and the breadth of training data. (4) Even when trained on identical data and evaluated under the same simulation framework, the intrinsic biases of each model family produce distinct risk‑return profiles.
The authors acknowledge several limitations. Transaction costs and slippage are modeled in a simplified manner, which may underestimate real‑world frictions. The dataset is confined to a single emerging market, raising questions about the generalizability of the findings to other regions or asset classes. Finally, the RL agent’s learning stability could be enhanced by more sophisticated exploration‑exploitation strategies and by incorporating risk‑aware reward shaping. Future work is suggested to extend the analysis to multi‑asset portfolios, higher‑frequency data, and ensemble methods that combine the strengths of the three approaches, thereby improving robustness and practical applicability of deep‑learning‑based trading systems.