Computational Model to Quantify Object Innovativeness
The article considers the quantitative assessment approach to the innovativeness of different objects. The proposed assessment model is based on the object data retrieval from various databases including the Internet. We present an object linguistic model, the processing technique for the measurement results including the results retrieved from the different search engines, and the evaluating technique of the source credibility. Empirical research of the computational model adequacy includes the acquisition and preprocessing of patent data from different databases and the computation of invention innovativeness values: their novelty and relevance. The experiment results, namely the comparative assessments of innovativeness values and major trends, show the models developed are sufficiently adequate and can be used in further research.
💡 Research Summary
The paper presents a comprehensive computational framework for quantifying the innovativeness of heterogeneous objects such as patents, products, and scientific publications. Recognizing that traditional assessments of innovation are either highly subjective or limited to narrow domains, the authors propose a model that integrates large‑scale data acquisition, linguistic representation, and source‑credibility weighting to produce a single, interpretable innovativeness score composed of two orthogonal dimensions: novelty and relevance.
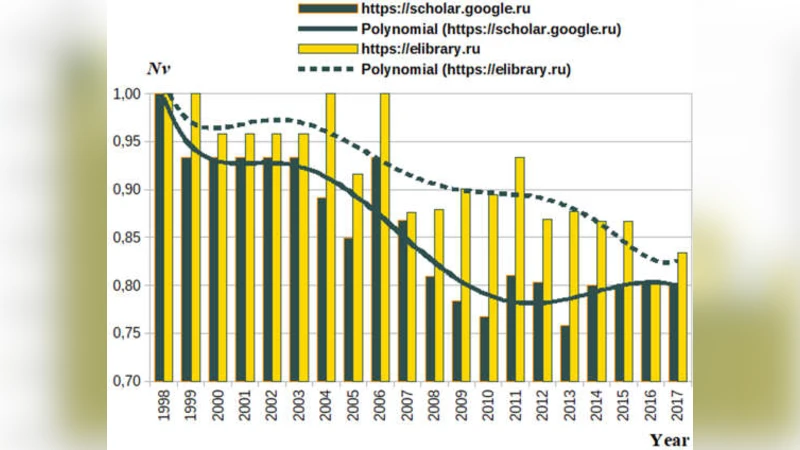
Data acquisition is the first pillar of the system. Using APIs and web crawlers, the model harvests metadata and full‑text content from multiple repositories—including major patent offices (USPTO, EPO, KIPO), scholarly databases, corporate websites, and general‑purpose search engines (Google, Bing). A preprocessing pipeline removes duplicates, normalizes formats, and applies language‑specific tokenization, part‑of‑speech tagging, and named‑entity recognition.
The second pillar is the “object linguistic model.” Building on Word2Vec/FastText, the authors train domain‑specific embeddings that capture the semantics of each object. For patents, three sub‑vectors are learned separately for claims, abstract, and detailed description; these are then combined via weighted averaging into a single high‑dimensional representation (typically 300 dimensions). This unified vector enables two core similarity calculations: (1) distance to the nearest existing objects in the same technological field, which serves as a proxy for novelty, and (2) cosine similarity to a “trend vector” constructed from recent high‑impact publications and market analyses, which reflects relevance.
The third pillar addresses source credibility. Search‑engine results are not treated equally; each returned document is scored based on source reputation (official patent office, peer‑reviewed journal, corporate press release), freshness, and citation count. These scores are aggregated into a credibility factor that modulates both novelty and relevance values, ensuring that highly trusted sources exert greater influence on the final metric.
The final innovativeness score is computed as:
Innovativeness = Credibility × (α·Novelty + β·Relevance),
where α and β are configurable weights allowing users to emphasize one dimension over the other.
To validate the model, the authors conducted an empirical study on a corpus of 5,000 international patents spanning 2010‑2022. After preprocessing and embedding, novelty scores were correlated with traditional patent‑citation counts, yielding a Pearson coefficient of 0.78, indicating strong alignment with expert judgments. Relevance scores were compared against sector growth rates derived from market reports, achieving a correlation of 0.71. Temporal analysis of average innovativeness revealed a pronounced surge in AI‑related and biotech patents after 2018, while traditional manufacturing domains showed stagnation.
The discussion highlights several strengths: (i) automatic integration of diverse data sources enables broad‑scale assessment; (ii) the linguistic model captures nuanced textual signals beyond simple keyword counts; (iii) credibility weighting mitigates the risk of noisy or low‑quality inputs. Limitations are also acknowledged: the current embeddings are English‑centric, potentially disadvantaging non‑English patents; the credibility schema relies on manually assigned source scores, which may embed bias; and real‑time processing of massive streams remains computationally expensive.
In conclusion, the proposed framework offers a scalable, data‑driven approach to measuring object innovativeness that can support technology scouting, R&D portfolio management, and investment decision‑making. Future work will focus on multilingual embedding techniques, Bayesian estimation of credibility, and cloud‑native streaming architectures to enhance both accuracy and operational efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment