RCT: Resource Constrained Training for Edge AI
💡 Research Summary
The paper addresses the growing need for on‑device learning in edge AI, where neural networks must be trained directly on resource‑constrained terminals. While quantisation is widely used to reduce inference cost, existing quantisation‑aware training (QAT) methods assume abundant memory and energy. QAT typically keeps two copies of the model—an FP32 version for gradient accumulation and a quantised version for forward passes—forcing frequent data movement between off‑chip DRAM and on‑chip caches. This double‑copy approach is infeasible for battery‑powered edge devices because of high memory footprint and energy‑intensive data transfers.
To overcome these limitations, the authors propose Resource Constrained Training (RCT). RCT retains only a quantised model throughout training, thereby eliminating the need for an FP32 copy. The key innovation is a per‑layer metric called Gavg, which measures how often quantisation under‑flow occurs in a given layer. Gavg is defined as the average absolute gradient magnitude divided by the minimum quantisation step (Δ) of that layer. When Gavg is close to zero, the layer’s parameters rarely change because the gradient is smaller than Δ, indicating severe under‑flow. Conversely, a larger Gavg means the layer can still be updated effectively.
Using Gavg, RCT dynamically adjusts each layer’s bitwidth during training. A simple policy (Algorithm 1) raises the bitwidth by one bit if Gavg falls below a lower threshold T_min, and lowers it if Gavg exceeds an upper threshold T_max. The training loop (Algorithm 2) evaluates Gavg at regular intervals (e.g., every few batches) and applies the policy before the parameter update step. This approach allows the network to start with a very low precision (e.g., 8‑bit) to maximise energy and memory savings, and to allocate higher precision only to layers that suffer from under‑flow as training progresses.
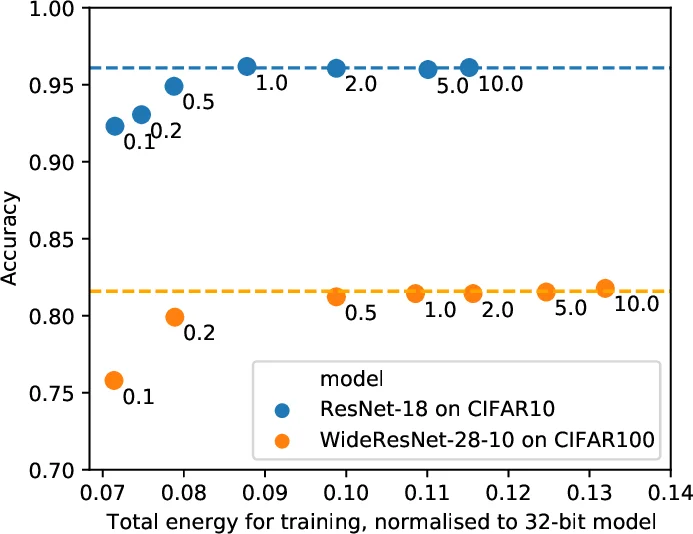
The authors evaluate RCT on a suite of image classification benchmarks (CIFAR‑10/100, SVHN, ImageNet) using four backbone architectures (ResNet‑20, ResNet‑110, MobileNetV2, WideResNet‑28‑10) and on representative NLP tasks. Quantisation is performed with linear scaling and stochastic rounding; activations are fixed at 8‑bit. Energy consumption for GEMM operations is estimated by scaling 32‑bit energy values, assuming a 16‑bit multiplication costs 25 % of a 32‑bit one. Memory usage is measured by the size of the stored parameters.
Results show that RCT reduces GEMM energy by more than 86 % and model‑parameter memory by over 46 % compared with a full‑precision baseline, while incurring only a modest drop in accuracy (typically <2 %). Compared to state‑of‑the‑art QAT methods, RCT saves roughly half the energy associated with moving model parameters between off‑chip and on‑chip memory, because it never stores an FP32 copy. Figure 3 illustrates how per‑layer bitwidths evolve: early in training many layers operate at 2‑4 bits, and as Gavg signals under‑flow, the bitwidths gradually increase to 8‑12 bits, achieving a balance between efficiency and learning capability.
The paper acknowledges limitations: Gavg currently only accounts for gradient magnitude relative to Δ, ignoring other training hyper‑parameters such as learning rate schedules or optimizer dynamics. Incorporating these factors could yield finer‑grained precision control. Moreover, the energy model is hardware‑agnostic; real‑world edge hardware may exhibit different scaling behaviours, necessitating empirical validation.
In summary, Resource Constrained Training offers a practical solution for on‑device quantised training under strict memory and energy budgets. By keeping only a quantised model and adaptively tuning per‑layer precision based on a simple under‑flow metric, RCT enables substantial resource savings while preserving competitive accuracy, making it well‑suited for continual learning scenarios on edge AI platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment