Engineering an Intelligent Essay Scoring and Feedback System: An Experience Report
Artificial Intelligence (AI) / Machine Learning (ML)-based systems are widely sought-after commercial solutions that can automate and augment core business services. Intelligent systems can improve the quality of services offered and support scalability through automation. In this paper we describe our experience in engineering an exploratory system for assessing the quality of essays supplied by customers of a specialized recruitment support service. The problem domain is challenging because the open-ended customer-supplied source text has considerable scope for ambiguity and error, making models for analysis hard to build. There is also a need to incorporate specialized business domain knowledge into the intelligent processing systems. To address these challenges, we experimented with and exploited a number of cloud-based machine learning models and composed them into an application-specific processing pipeline. This design allows for modification of the underlying algorithms as more data and improved techniques become available. We describe our design, and the main challenges we faced, namely keeping a check on the quality control of the models, testing the software and deploying the computationally expensive ML models on the cloud.
💡 Research Summary
The paper presents a comprehensive experience report on building an intelligent essay scoring and feedback system for a specialized recruitment support service. The authors begin by outlining the unique challenges of the domain: customer‑submitted essays are highly unstructured, often contain spelling and grammatical errors, and may deviate from the intended topic, making traditional supervised learning approaches difficult to apply. In addition, the service requires the incorporation of business‑specific knowledge such as competency keywords, weighting schemes for different evaluation criteria, and industry‑specific expectations, which are not captured by generic language models.
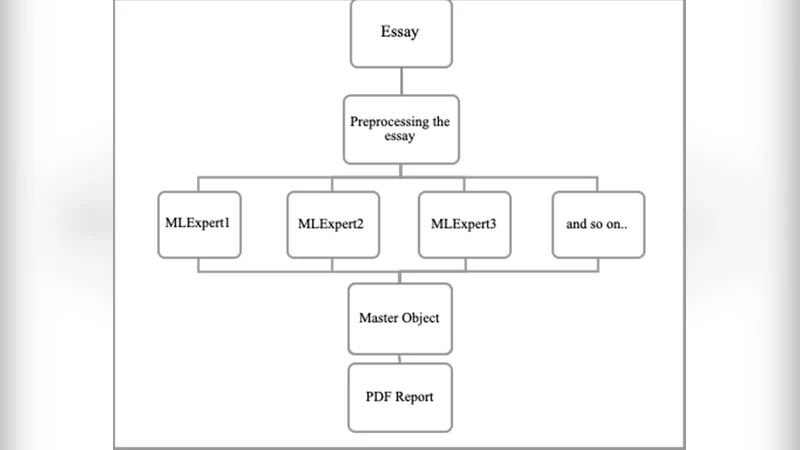
To address these issues, the team designed a modular, cloud‑native processing pipeline composed of four layers. The first layer performs robust preprocessing, including spell‑checking, sentence segmentation, and tokenization, while logging severely corrupted inputs for later analysis. The second layer extracts rich linguistic features using pre‑trained large language models (e.g., BERT, RoBERTa) to generate sentence embeddings, and runs parallel classifiers for grammar error detection and semantic coherence assessment. The third “domain‑knowledge enrichment” layer injects structured metadata—competency keywords, criterion weights, and rule‑based heuristics—into the embedding space, creating a combined “knowledge‑enhanced vector.” This vector is used to compute a hybrid score that blends rule‑based components with learned predictions. The final layer generates actionable feedback by merging template‑based natural language generation with a fine‑tuned GPT‑style model, producing personalized comments on strengths and improvement areas.
From an engineering perspective, the system leverages a hybrid cloud strategy. Real‑time scoring of short excerpts is handled by serverless functions (AWS Lambda) running lightweight models, guaranteeing sub‑second latency. Full‑essay scoring and detailed feedback generation are off‑loaded to GPU‑accelerated batch jobs on Google Cloud AI Platform, optimizing cost while maintaining throughput. Model versioning, infrastructure provisioning, and continuous integration/continuous deployment (CI/CD) are managed with Terraform and GitHub Actions, allowing seamless updates as new data or algorithms become available.
Quality control is a central theme. The authors evaluate model performance against human raters using Pearson correlation and R², and they track precision/recall for specific error categories (e.g., off‑topic content, missing competencies). An automated regression test suite validates that new releases do not degrade existing performance. Input monitoring detects out‑of‑distribution texts and prevents them from propagating through the pipeline, thereby reducing error amplification. Logging and anomaly detection further support rapid troubleshooting.
Pilot deployments demonstrated promising results: the system achieved an average correlation of 0.78 with human scores, and 85 % of end‑users reported that the feedback was useful for improving their essays. Operational costs were kept under $1,200 per month thanks to the serverless‑batch hybrid model. The paper concludes with lessons learned—particularly the importance of modular design for future algorithm swaps, the need for ongoing domain‑knowledge updates, and the challenges posed by limited labeled data. Future work includes incorporating reinforcement learning from human feedback (RLHF) to continuously refine scoring models, automating the labeling pipeline, and extending the platform to multimodal inputs such as spoken responses. Overall, the report offers a practical blueprint for deploying AI‑driven, domain‑aware text assessment systems in real‑world, cost‑constrained environments.