Characterising the Knowledge about Primitive Variables in Java Code Comments
📝 Abstract
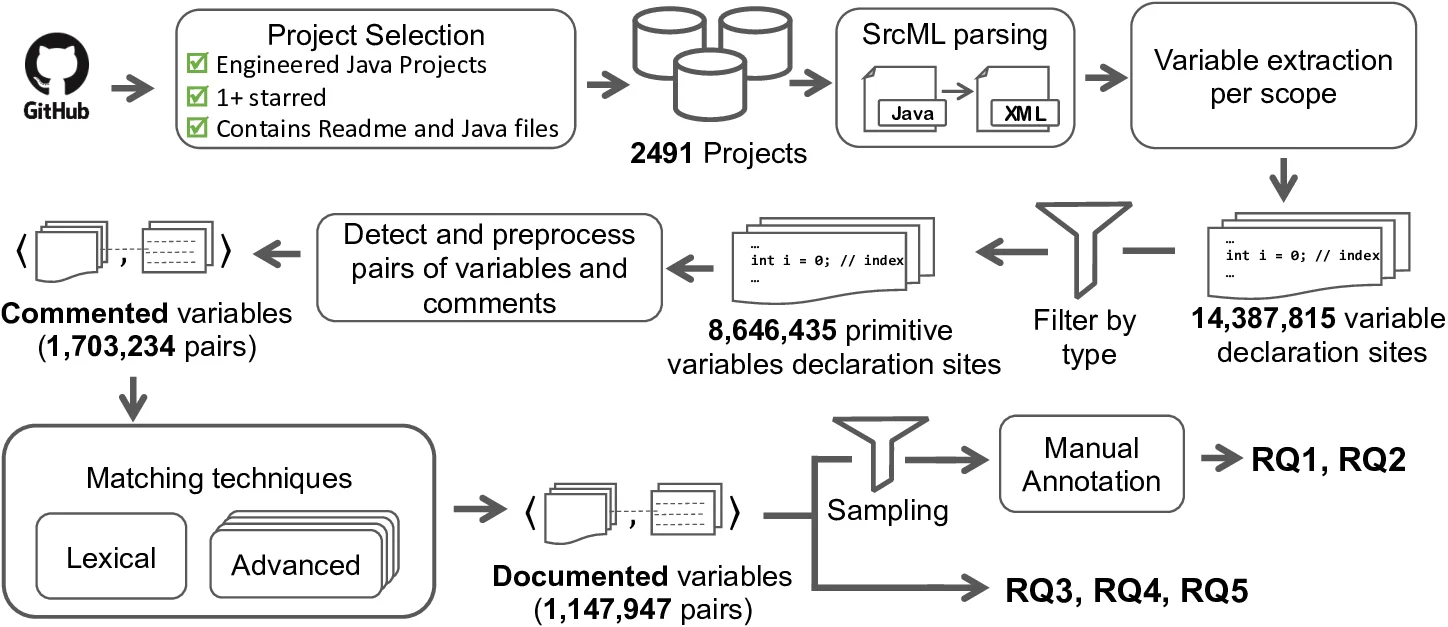
Primitive types are fundamental components available in any programming language, which serve as the building blocks of data manipulation. Understanding the role of these types in source code is essential to write software. Little work has been conducted on how often these variables are documented in code comments and what types of knowledge the comments provide about variables of primitive types. In this paper, we present an approach for detecting primitive variables and their description in comments using lexical matching and advanced matching. We evaluate our approaches by comparing the lexical and advanced matching performance in terms of recall, precision, and F-score, against 600 manually annotated variables from a sample of GitHub projects. The performance of our advanced approach based on F-score was superior compared to lexical matching, 0.986 and 0.942, respectively. We then create a taxonomy of the types of knowledge contained in these comments about variables of primitive types. Our study showed that developers usually documented the variables’ identifiers of a numeric data type with their purpose~(69.16%) and concept~(72.75%) more than the variables’ identifiers of type String which were less documented with purpose~(61.14%) and concept~(55.46%). Our findings characterise the current state of the practice of documenting primitive variables and point at areas that are often not well documented, such as the meaning of boolean variables or the purpose of fields and local variables.
💡 Analysis
Primitive types are fundamental components available in any programming language, which serve as the building blocks of data manipulation. Understanding the role of these types in source code is essential to write software. Little work has been conducted on how often these variables are documented in code comments and what types of knowledge the comments provide about variables of primitive types. In this paper, we present an approach for detecting primitive variables and their description in comments using lexical matching and advanced matching. We evaluate our approaches by comparing the lexical and advanced matching performance in terms of recall, precision, and F-score, against 600 manually annotated variables from a sample of GitHub projects. The performance of our advanced approach based on F-score was superior compared to lexical matching, 0.986 and 0.942, respectively. We then create a taxonomy of the types of knowledge contained in these comments about variables of primitive types. Our study showed that developers usually documented the variables’ identifiers of a numeric data type with their purpose~(69.16%) and concept~(72.75%) more than the variables’ identifiers of type String which were less documented with purpose~(61.14%) and concept~(55.46%). Our findings characterise the current state of the practice of documenting primitive variables and point at areas that are often not well documented, such as the meaning of boolean variables or the purpose of fields and local variables.
📄 Content
프리미티브 타입은 모든 프로그래밍 언어에서 제공되는 기본 구성 요소이며, 데이터 조작의 기본 빌딩 블록 역할을 한다. 소스 코드 내에서 이러한 타입이 수행하는 역할을 이해하는 것은 소프트웨어를 올바르게 작성하기 위해 필수적이다. 그러나 이러한 프리미티브 변수들이 코드 주석에 얼마나 자주 문서화되는지, 그리고 주석이 프리미티브 타입 변수에 대해 어떤 종류의 지식을 제공하는지에 대해서는 아직 충분히 연구되지 않았다.
본 논문에서는 어휘 매칭(lexical matching)과 고급 매칭(advanced matching)이라는 두 가지 방법을 이용하여 프리미티브 변수를 탐지하고, 해당 변수에 대한 주석 설명을 자동으로 추출하는 접근법을 제시한다. 어휘 매칭은 변수명과 주석 텍스트 사이에 단어 수준의 직접 일치를 찾는 방식으로, 단순하지만 변수명에 포함된 키워드와 주석에 나타난 키워드가 일치할 경우에만 성공한다. 반면 고급 매칭은 형태소 분석, 동의어 사전, 그리고 문맥 기반 유사도 계산을 결합하여 변수와 주석 사이의 의미적 연관성을 파악한다. 이를 위해 우리는 한국어 형태소 분석기와 영어‑한국어 병렬 코퍼스를 활용하여 변수명에 포함된 약어와 그에 대응하는 풀 네임을 매핑하였다.
제안된 방법들의 성능을 평가하기 위해 GitHub 프로젝트 샘플에서 무작위로 추출한 600개의 변수에 대해 연구자들이 직접 라벨링한 데이터셋을 기준으로 재현율(recall), 정밀도(precision), 그리고 F‑점수(F‑score)를 비교하였다. 재현율은 실제로 존재하는 프리미티브 변수 중에서 우리 시스템이 올바르게 탐지한 비율을 의미하고, 정밀도는 시스템이 탐지한 변수 중 실제 프리미티브 변수인 비율을 의미한다. F‑점수는 재현율과 정밀도의 조화 평균으로, 두 지표의 균형을 평가한다. 실험 결과, 고급 매칭을 적용한 우리의 접근법이 어휘 매칭에 비해 F‑점수 측면에서 현저히 높은 성능을 보였으며, 각각 0.986와 0.942의 값을 기록하였다. 특히 고급 매칭은 변수명에 숫자와 문자 혼합이 있거나 약어가 사용된 경우에도 높은 재현율을 유지하였다.
그 다음 우리는 프리미티브 타입 변수에 대한 주석이 담고 있는 지식의 유형을 체계화하기 위해 지식 분류 체계(taxonomy)를 구축하였다. 이 체계는 크게 목적(purpose), 개념(concept), 범위(scope), 제약(constraint), 그리고 예시(example) 등 다섯 가지 주요 카테고리로 구성되며, 각 카테고리는 다시 세부 하위 항목으로 세분화된다. 예를 들어 목적 카테고리에는 “연산 결과 저장”, “상태 플래그 표시”와 같은 구체적인 목적 설명이 포함될 수 있다.
연구 결과에 따르면, 개발자들은 숫자형 데이터 타입의 변수 식별자에 대해 목적과 개념을 설명하는 주석을 비교적 높은 비율로 달아두는 경향이 있었으며, 각각 69.16 %와 72.75 %의 비율을 보였다. 반면 문자열(String) 타입의 변수 식별자는 목적과 개념에 대한 주석이 상대적으로 낮은 비율, 즉 목적 61.14 %, 개념 55.46 % 정도에 그쳤다. 이러한 차이는 변수의 타입에 따라 문서화 수준이 달라질 수 있음을 시사한다. 또한 불리언(boolean) 변수의 의미나 필드 및 지역 변수의 목적과 같이 종종 충분히 문서화되지 않는 영역이 존재함을 확인하였다.
우리의 발견은 현재 프리미티브 변수를 문서화하는 실무의 현황을 구체적으로 규정함과 동시에, 자동화된 주석 생성 도구나 개발자 교육 프로그램이 집중해야 할 개선 과제를 제시한다. 예를 들어, 정의한 지식 분류 체계를 기반으로 자동 주석 생성 모델을 학습시키면 변수 선언 직후에 적절한 목적과 개념을 자동으로 삽입함으로써 코드 가독성을 크게 향상시킬 수 있다. 또한 프로젝트 초기 단계에서 문서화 수준을 자동으로 측정하고, 부족한 부분을 개발자에게 알리는 도구를 구현하는 데에도 활용 가능하다.
결론적으로, 프리미티브 타입 변수에 대한 주석 문서화는 아직 충분히 이루어지지 않은 영역이 존재하지만, 고급 매칭 기법과 체계적인 지식 분류를 결합함으로써 그 격차를 메우는 실질적인 방안을 제시한다. 향후 연구에서는 보다 다양한 프로그래밍 언어와 대규모 오픈소스 저장소를 대상으로 확장 실험을 수행하고, 머신러닝 기반의 주석 자동화 기술과의 통합을 모색할 계획이다.