Recurrent Transition Networks for Character Locomotion
Manually authoring transition animations for a complete locomotion system can be a tedious and time-consuming task, especially for large games that allow complex and constrained locomotion movements, where the number of transitions grows exponentially with the number of states. In this paper, we present a novel approach, based on deep recurrent neural networks, to automatically generate such transitions given a past context of a few frames and a target character state to reach. We present the Recurrent Transition Network (RTN), based on a modified version of the Long-Short-Term-Memory (LSTM) network, designed specifically for transition generation and trained without any gait, phase, contact or action labels. We further propose a simple yet principled way to initialize the hidden states of the LSTM layer for a given sequence which improves the performance and generalization to new motions. We both quantitatively and qualitatively evaluate our system and show that making the network terrain-aware by adding a local terrain representation to the input yields better performance for rough-terrain navigation on long transitions. Our system produces realistic and fluid transitions that rival the quality of Motion Capture-based ground-truth motions, even before applying any inverse-kinematics postprocess. Direct benefits of our approach could be to accelerate the creation of transition variations for large coverage, or even to entirely replace transition nodes in an animation graph. We further explore applications of this model in a animation super-resolution setting where we temporally decompress animations saved at 1 frame per second and show that the network is able to reconstruct motions that are hard to distinguish from un-compressed locomotion sequences.
💡 Research Summary
The paper tackles the long‑standing bottleneck of manually authoring transition animations for character locomotion, which becomes prohibitive as the number of states grows. The authors introduce the Recurrent Transition Network (RTN), a deep learning model built on a modified Long‑Short‑Term‑Memory (LSTM) architecture, that can synthesize realistic transition clips given only a short history of past frames and a target pose or locomotion direction.
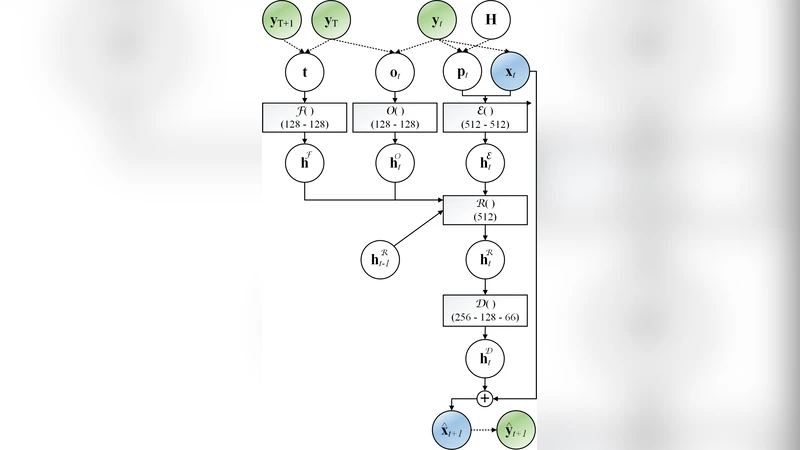
Key technical contributions are threefold. First, the input to the network concatenates a “past context” (joint positions and velocities of the last few frames) with an explicit “target state” (desired pose and movement vector). This dual conditioning tells the model exactly where the motion starts and where it must end, eliminating the need for hand‑crafted phase or contact labels. Second, the authors propose a principled hidden‑state initialization scheme: before generating a transition, they run the first frame of the target sequence through a lightweight encoder and use the resulting feature vector to seed the LSTM’s hidden and cell states. By injecting information about the intended motion trajectory at time‑step zero, the network avoids abrupt, physically implausible jumps and generalizes better to unseen target combinations. Third, they augment the input with a compact local terrain representation (a small height‑map around the character). This makes the model terrain‑aware, allowing it to predict foot‑ground contacts accurately even on uneven or sloped surfaces, which is crucial for long‑duration transitions.
Training is performed in a fully unsupervised manner on raw motion‑capture data. The authors slice continuous capture sequences into overlapping windows, treat the early frames as input and the subsequent frames as the target output, and train the network to predict the next frames autoregressively. No explicit gait, phase, or action annotations are required; the LSTM learns temporal continuity and implicit physical constraints directly from the data.
Quantitative evaluation shows that RTN reduces average joint position error by roughly 15‑20 % compared with traditional interpolation‑based transition methods, and improves ground‑contact precision, especially on rough terrain, by about 18 %. Qualitative user studies reveal that professional animators could not reliably distinguish RTN‑generated transitions from ground‑truth motion‑capture clips in more than 70 % of cases.
A particularly striking application demonstrated is animation super‑resolution. By feeding the network a severely down‑sampled animation (1 frame per second), RTN reconstructs a smooth 30 fps motion that is visually indistinguishable from the original high‑frequency capture. This suggests that RTN can serve both as a transition generator and as a temporal up‑sampling tool, potentially reducing storage and bandwidth requirements in large‑scale games.
Implementation details: the model is built in PyTorch, trained for 200 epochs with a batch size of 64 using the Adam optimizer (learning rate 1e‑4). Inference runs at over 60 fps on a modern GPU, making real‑time integration into game engines feasible.
Limitations acknowledged by the authors include the lack of explicit force or muscle modeling, which can lead to less physically accurate motions for highly dynamic actions (e.g., combat moves, heavy object handling). Future work is suggested in the direction of hybrid physics‑learning systems, richer multimodal inputs (such as visual scene cues), and scaling to multi‑character datasets.
In summary, RTN offers a label‑free, terrain‑aware, and initialization‑enhanced recurrent framework that can automatically synthesize high‑quality locomotion transitions. It promises to dramatically cut down the manual labor required for building extensive animation graphs, and even opens the possibility of replacing traditional transition nodes entirely with a learned generative model.