Optimal Gradient Checkpoint Search for Arbitrary Computation Graphs
Deep Neural Networks(DNNs) require huge GPU memory when training on modern image/video databases. Unfortunately, the GPU memory is physically finite, which limits the image resolutions and batch sizes that could be used in training for better DNN performance. Unlike solutions that require physically upgrade GPUs, the Gradient CheckPointing(GCP) training trades computation for more memory beyond existing GPU hardware. GCP only stores a subset of intermediate tensors, called Gradient Checkpoints (GCs), during forward. Then during backward, extra local forwards are conducted to compute the missing tensors. The total training memory cost becomes the sum of (1) the memory cost of the gradient checkpoints and (2) the maximum memory cost of local forwards. To achieve maximal memory cut-offs, one needs optimal algorithms to select GCs. Existing GCP approaches rely on either manual input of GCs or heuristics-based GC search on Linear Computation Graphs (LCGs), and cannot apply to Arbitrary Computation Graphs(ACGs). In this paper, we present theories and optimal algorithms on GC selection that, for the first time, are applicable to ACGs and achieve the maximal memory cut-offs. Extensive experiments show that our approach not only outperforms existing approaches (only applicable on LCGs), and is applicable to a vast family of LCG and ACG networks, such as Alexnet, VGG, ResNet, Densenet, Inception Net and highly complicated DNNs by Network Architecture Search. Our work enables GCP training on ACGs, and cuts off up-to 80% of training memory with a moderate time overhead (~30%-50%). Codes are available
💡 Research Summary
This paper addresses the pressing problem of GPU memory limitation during deep neural network (DNN) training by advancing Gradient Checkpointing (GCP) from a heuristic, linear‑graph‑only technique to a provably optimal method that works on arbitrary computation graphs (ACGs). The authors first formalize the memory‑peak objective as the sum of the memory occupied by selected gradient checkpoints (GCs) plus the maximum memory required for any local re‑forward segment between consecutive checkpoints. Mathematically, the problem is expressed as
min_{V_R} ( Σ_i l(v_Ri) + max_i l(v_Ri, v_R{i+1}) ),
where l(v) denotes the memory size of tensor v and l(v_Ri, v_R{i+1}) is the cumulative size of all intermediate tensors between two checkpoints.
For linear computation graphs (LCGs) they consider two scenarios. When all vertices have identical cost, the optimal solution distributes √N checkpoints evenly, reducing memory from N to 2√N, which matches the intuition behind the widely‑used Chen algorithm. When vertex costs differ, they introduce an “Accessibility Graph” that connects two vertices only if the cumulative cost between them does not exceed a chosen bound C. Finding the shortest path from source to target in this graph yields the minimal checkpoint cost under the constraint C. By enumerating all possible C values (i.e., all pairwise segment costs) and selecting the best resulting solution, they obtain the global optimum for any LCG. The algorithm runs in O(|V|²|E| + |V|³ log|V|) time, making it practical for modern networks.
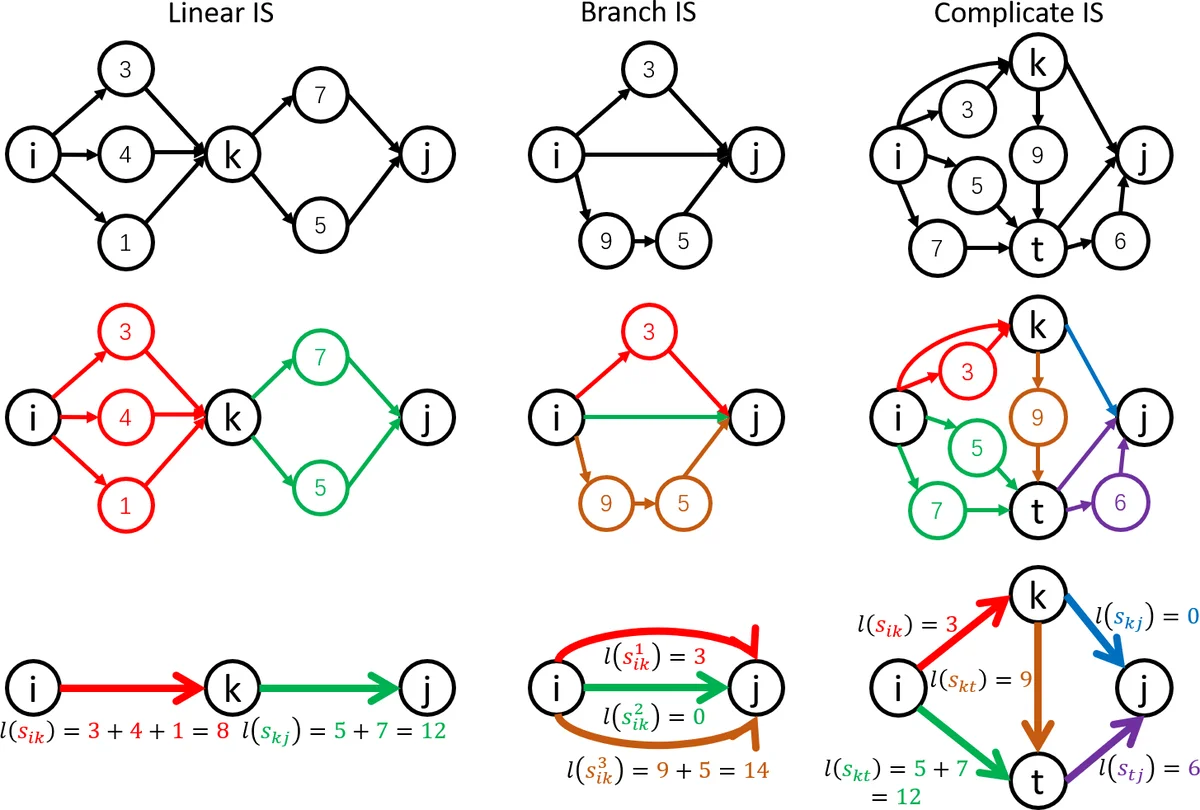
Extending to ACGs, the paper defines an Independent Segment (IS) as a sub‑graph bounded by two checkpoints that has no edges crossing its boundary. Each IS can be processed independently during re‑forward and backward passes. The authors classify ISs into linear and non‑linear types based on the existence of a “linear splitting vertex” that allows the segment to be broken into two smaller ISs sharing a common vertex. If an IS’s total memory exceeds the current bound C, it is recursively split by inserting additional checkpoints until all resulting ISs satisfy the constraint. The overall optimization again reduces to minimizing the sum of checkpoint memory under the maximal IS cost C, solved by iterating over candidate C values and applying the IS‑splitting procedure.
Experiments cover a wide spectrum of architectures: AlexNet, VGG, ResNet, DenseNet, Inception, and several networks discovered by Neural Architecture Search (NAS). Compared with prior methods that only handle LCGs (Griewank‑Walther, Chen, Gruslys), the proposed approach achieves memory reductions of 60‑80 % while incurring an average computational overhead of 30‑50 %. Notably, models that previously required >30 GB of GPU memory (e.g., high‑resolution image classifiers, 64‑frame video models) can now be trained on a single 11 GB RTX 2080 Ti. The authors release an open‑source implementation compatible with PyTorch and TensorFlow, facilitating reproducibility and integration into existing pipelines.
Key contributions are: (1) a rigorous theoretical framework for optimal GC selection on arbitrary directed acyclic graphs; (2) novel algorithms based on accessibility graphs and IS decomposition that guarantee global optimality; (3) extensive empirical validation demonstrating substantial memory savings across diverse, real‑world DNNs. Limitations include the quadratic‑to‑cubic scaling of the accessibility‑graph construction for extremely large graphs and potential extra overhead for models with highly dynamic memory patterns. Future work is suggested on graph compression techniques, hardware‑aware scheduling, and multi‑GPU collaborative checkpointing strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment