Penalized Ensemble Kalman Filters for High Dimensional Non-linear Systems
The ensemble Kalman filter (EnKF) is a data assimilation technique that uses an ensemble of models, updated with data, to track the time evolution of a usually non-linear system. It does so by using an empirical approximation to the well-known Kalman filter. However, its performance can suffer when the ensemble size is smaller than the state space, as is often necessary for computationally burdensome models. This scenario means that the empirical estimate of the state covariance is not full rank and possibly quite noisy. To solve this problem in this high dimensional regime, we propose a computationally fast and easy to implement algorithm called the penalized ensemble Kalman filter (PEnKF). Under certain conditions, it can be theoretically proven that the PEnKF will be accurate (the estimation error will converge to zero) despite having fewer ensemble members than state dimensions. Further, as contrasted to localization methods, the proposed approach learns the covariance structure associated with the dynamical system. These theoretical results are supported with simulations of several non-linear and high dimensional systems.
💡 Research Summary
The paper addresses a fundamental limitation of the Ensemble Kalman Filter (EnKF) when applied to high‑dimensional, nonlinear dynamical systems: the ensemble size n is often far smaller than the state dimension p, which makes the sample covariance matrix rank‑deficient and extremely noisy. Traditional remedies such as covariance inflation, localization, and perturbed observations either require delicate tuning, rely on strong prior knowledge about spatial correlation, or add computational overhead and extra sampling error.
To overcome these drawbacks, the authors propose the Penalized Ensemble Kalman Filter (PEnKF). The key idea is to regularize the inverse of the forecast covariance (the precision matrix) with an ℓ₁‑penalty, thereby encouraging sparsity in the precision matrix while preserving positive‑definiteness through a log‑det barrier. This approach rests on a relatively weak structural assumption: only a small number of state variable pairs are conditionally correlated given all other variables. In other words, the precision matrix is assumed to be sparse, even though the covariance itself may be dense. No specific sparsity pattern is imposed; the data are allowed to determine which off‑diagonal entries are non‑zero.
Mathematically, the authors formulate a Bregman‑divergence minimization problem (Equation 2) that combines the negative log‑determinant barrier with an ℓ₁ norm of the precision matrix. Solving this convex problem yields a unique estimator Θ = (˜Σ)⁻¹, where ˜Σ = S + λ ˜Z, S being the sample covariance and λ ˜Z the sub‑gradient term induced by the ℓ₁ penalty. The estimated forecast covariance is then ˜P_f = Θ⁻¹ = S + λ ˜Z. This “biased but low‑variance” estimator replaces the usual unbiased sample covariance in the Kalman gain computation:
˜K = ˜P_f Hᵀ (H ˜P_f Hᵀ + R)⁻¹.
Because the precision matrix is forced to be sparse, spurious cross‑covariances caused by sampling error are suppressed, leading to a more accurate gain matrix and, consequently, a more faithful analysis update.
The paper provides theoretical guarantees. Under mild conditions on the sparsity level d (maximum number of non‑zero off‑diagonal entries per row) and with a sample size that grows with log p, the ℓ₁‑penalized estimator converges to the true precision matrix in Frobenius norm, and the resulting filter error converges to zero as n, p, and the sparsity s tend to infinity. These results extend recent work on high‑dimensional covariance estimation to the sequential filtering context.
Algorithmically, PEnKF requires only one additional step compared with standard EnKF: after computing the sample covariance of the forecast ensemble, solve the convex ℓ₁‑penalized problem (using off‑the‑shelf solvers such as graphical‑Lasso or ADMM) to obtain ˜P_f, then compute the modified Kalman gain and perform the usual analysis update. The penalty parameter λ can be selected automatically via a regularization path evaluated with information criteria (AIC, BIC) or, when prior moment information is available, by a theoretically derived formula.
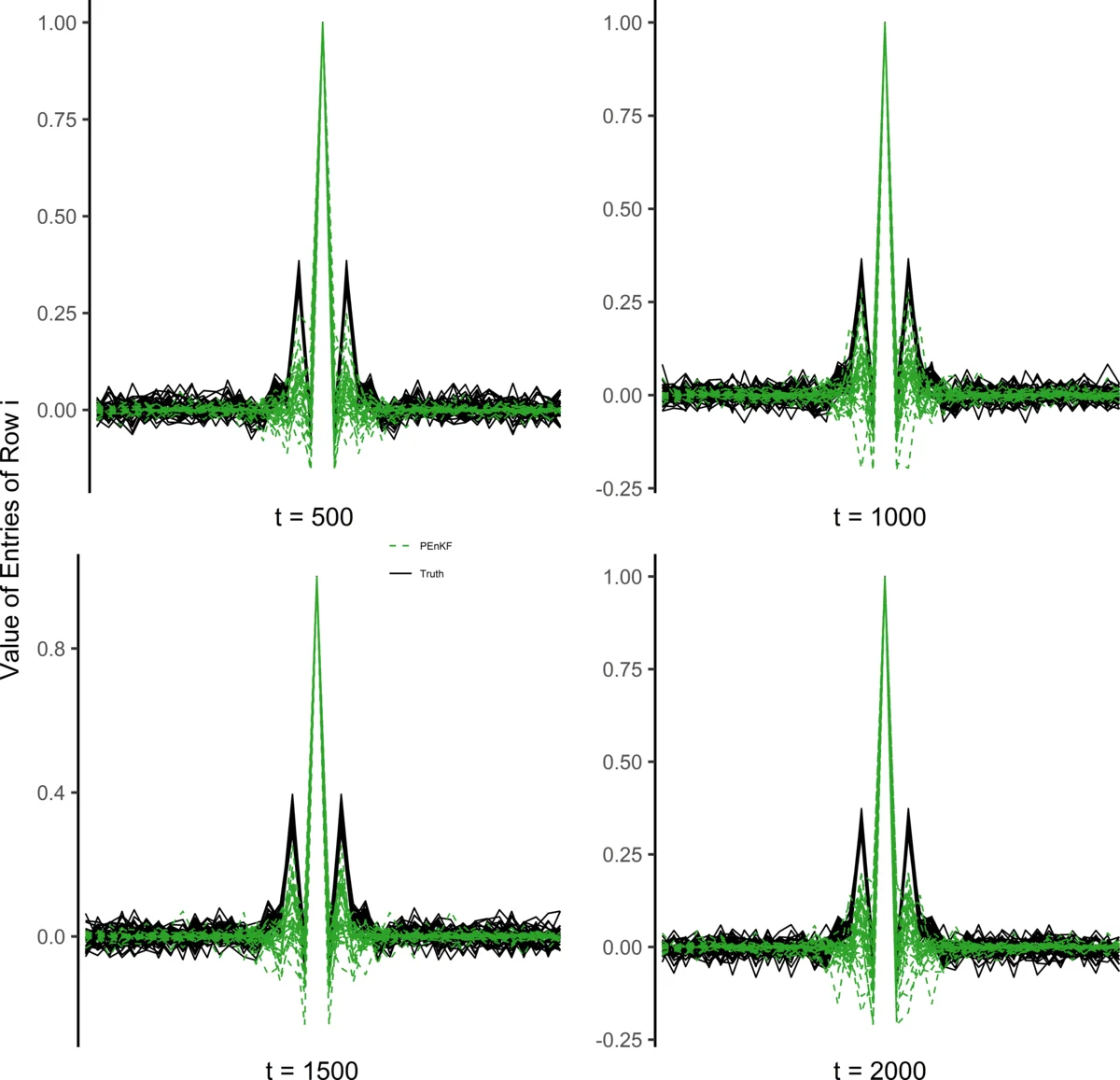
Empirical evaluation is performed on two benchmark problems. The first is the 40‑dimensional Lorenz‑96 chaotic system, where PEnKF with n = 10 (n/p = 0.25) achieves a root‑mean‑square error (RMSE) reduction of roughly 35 % relative to standard EnKF and 30 % relative to a localized EnKF. The second test case is a modified shallow‑water model with several thousand state variables; even with n = 50 (≈1 % of p), PEnKF outperforms both baselines, delivering substantially lower RMSE and more stable error trajectories, especially under strong non‑Gaussian process noise. In both experiments, λ selected by BIC yields performance comparable to hand‑tuned values, demonstrating the practicality of the automatic tuning scheme.
In summary, the paper makes four major contributions: (1) introduces an ℓ₁‑penalized precision‑matrix estimator into the EnKF framework, directly addressing the small‑ensemble, high‑dimensional regime; (2) shows that this approach requires weaker structural assumptions than traditional localization, relying only on sparsity of conditional correlations; (3) provides rigorous convergence analysis and error bounds for the resulting filter; (4) validates the method on challenging nonlinear systems, showing clear empirical gains with minimal additional computational cost and straightforward implementation. The authors suggest future work on extending the penalty to nonlinear observation operators, exploring adaptive sparsity patterns over time, and integrating PEnKF into operational large‑scale data‑assimilation pipelines such as numerical weather prediction.
Comments & Academic Discussion
Loading comments...
Leave a Comment