Security and Privacy Issues in Deep Learning
To promote secure and private artificial intelligence (SPAI), we review studies on the model security and data privacy of DNNs. Model security allows system to behave as intended without being affected by malicious external influences that can compromise its integrity and efficiency. Security attacks can be divided based on when they occur: if an attack occurs during training, it is known as a poisoning attack, and if it occurs during inference (after training) it is termed an evasion attack. Poisoning attacks compromise the training process by corrupting the data with malicious examples, while evasion attacks use adversarial examples to disrupt entire classification process. Defenses proposed against such attacks include techniques to recognize and remove malicious data, train a model to be insensitive to such data, and mask the model’s structure and parameters to render attacks more challenging to implement. Furthermore, the privacy of the data involved in model training is also threatened by attacks such as the model-inversion attack, or by dishonest service providers of AI applications. To maintain data privacy, several solutions that combine existing data-privacy techniques have been proposed, including differential privacy and modern cryptography techniques. In this paper, we describe the notions of some of methods, e.g., homomorphic encryption, and review their advantages and challenges when implemented in deep-learning models.
💡 Research Summary
The paper “Security and Privacy Issues in Deep Learning” provides a comprehensive survey of the threats that modern deep‑learning (DL) systems face and the countermeasures that have been proposed to mitigate them. The authors introduce the concept of Secure AI (SP‑AI) and organize the literature into four main categories: (1) attacks on DL models, (2) defenses against those attacks, (3) privacy‑related attacks, and (4) privacy‑preserving defenses.
Attack taxonomy
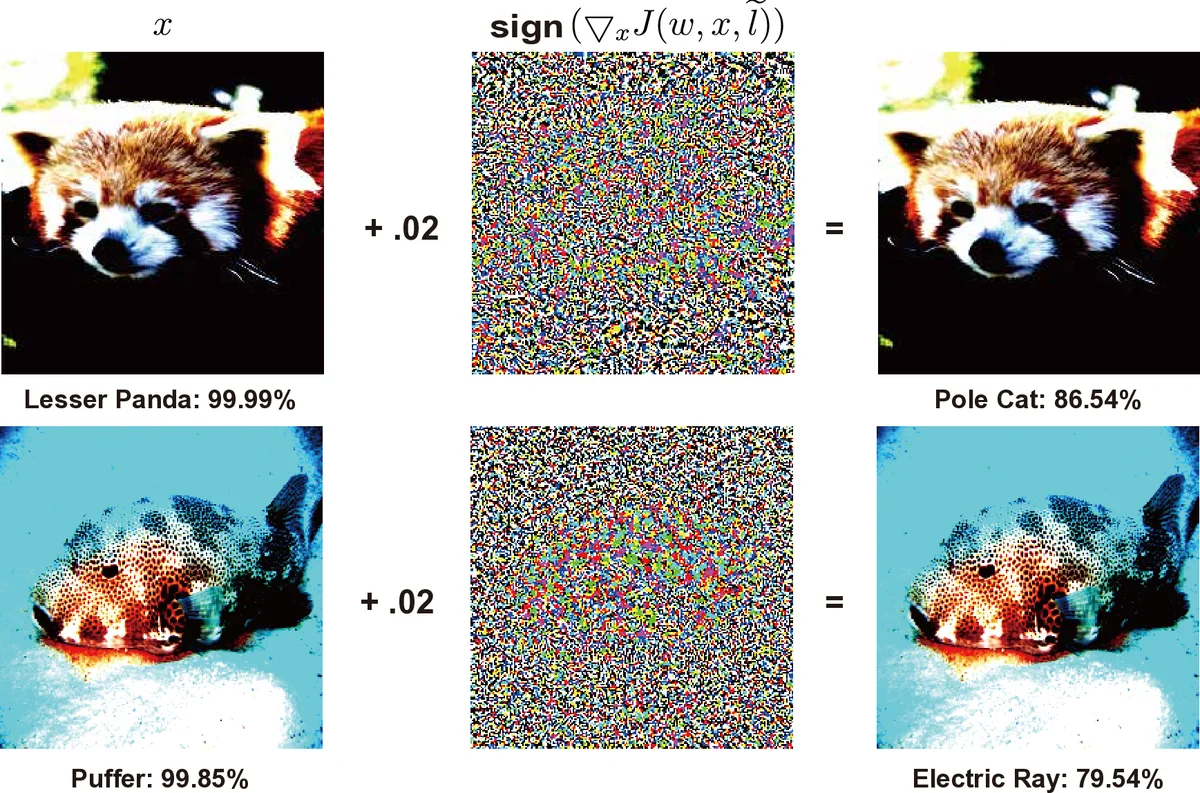
The authors split attacks by the phase in which they occur. Poisoning attacks target the training stage and are further divided into three sub‑classes: performance degradation (massive label noise), targeted poisoning (misclassifying a specific class), and backdoor attacks (embedding a hidden trigger that activates malicious behavior only on specially crafted inputs). Evasion attacks occur at inference time and are classified as white‑box (full knowledge of model architecture and parameters) or black‑box (only input‑output access). The paper reviews classic white‑box methods such as L‑BFGS, the Carlini‑Wagner (CW) attack, Fast Gradient Sign Method (FGSM) and its iterative variants, as well as newer techniques that exploit generative models (GAN‑based attacks) and spatial transformations. Black‑box methods include substitute‑model training, boundary attacks, and the recent AutoAttack ensemble that combines several white‑box and black‑box strategies.
Defensive strategies
Defenses are grouped into empirical and certified approaches. Empirical defenses aim to make models harder to attack in practice: gradient masking, adversarial training, randomized smoothing, and various detection schemes that monitor statistical anomalies in inputs or internal activations. Certified defenses provide formal guarantees that a model’s prediction will not change for any perturbation within a specified norm ball; examples include randomized smoothing certificates and provable robustness bounds based on Lipschitz constants. The authors note that empirical methods are often broken by adaptive attacks (e.g., BPDA defeats gradient masking), whereas certified methods suffer from high computational cost and limited applicability to large‑scale architectures.
Privacy threats and protections
Beyond integrity, the paper discusses privacy leakage: model‑inversion attacks that reconstruct training images, membership inference attacks that determine whether a particular record was part of the training set, and attacks by dishonest service providers who may misuse stored data. Countermeasures include differential privacy (DP), which adds calibrated noise to gradients or model updates, homomorphic encryption (HE) that enables computation on encrypted data, and secure multi‑party computation (MPC) that distributes the training process among mutually distrustful parties. While DP offers a mathematically sound privacy guarantee, it degrades model accuracy when the privacy budget is tight. HE and MPC provide strong confidentiality but incur prohibitive latency and memory overheads, limiting their deployment in real‑time or edge scenarios.
Critical insights
The survey highlights a co‑evolutionary arms race: attackers increasingly rely on black‑box techniques such as zero‑knowledge gradient estimation, while defenders explore hybrid solutions that combine empirical robustness with formal certification. The authors stress that many defenses are evaluated on narrow benchmark datasets and that a standardized, comprehensive benchmark covering diverse attack vectors, model architectures, and privacy settings is still missing.
Future research directions
The paper outlines several promising avenues: (1) lightweight cryptographic protocols that can be integrated into edge devices; (2) hybrid frameworks that jointly enforce differential privacy and certified robustness; (3) systematic detection of backdoors through data‑flow analysis and causal tracing; and (4) the creation of open‑source evaluation suites that enable reproducible comparison of security and privacy methods across domains such as autonomous driving, medical imaging, and cloud AI services.
In conclusion, the authors argue that as deep learning becomes foundational to critical applications, security and privacy must be treated as first‑class design constraints rather than afterthoughts. The survey serves as a roadmap for researchers and practitioners aiming to build trustworthy AI systems that can resist both malicious manipulation and inadvertent data leakage.
Comments & Academic Discussion
Loading comments...
Leave a Comment