Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model’s training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.
💡 Research Summary
The paper addresses the growing need to protect deep neural network (DNN) models that are trained on large, expensive datasets, especially in the natural language processing (NLP) domain. While many existing DNN watermarking techniques focus on image classification—embedding patterns or noise directly into visual data—the authors argue that such approaches are ill‑suited for text because arbitrary perturbations can easily destroy semantic meaning. To fill this gap, they propose a black‑box watermarking framework specifically designed for textual DNNs.
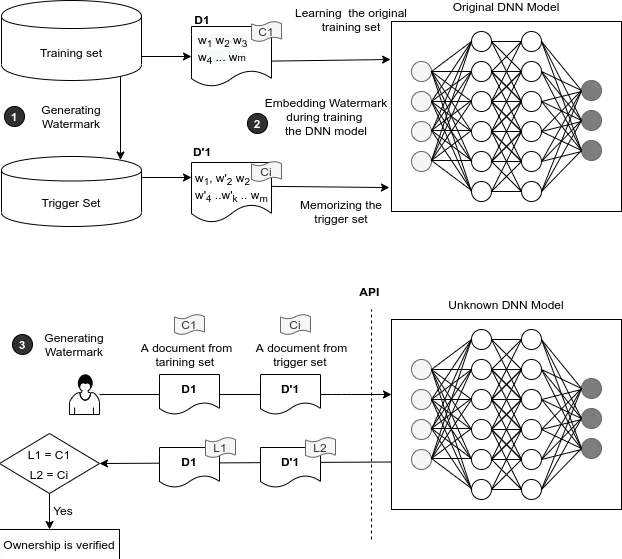
The core of the method relies on the classic information‑retrieval metric TF‑IDF (term frequency–inverse document frequency). First, a set of “trigger” sentences is created by randomly selecting samples from the original training corpus and then adding a small, controlled amount of noise (e.g., synonym substitution, minor spelling changes). The selection of which words to manipulate is guided by TF‑IDF scores, ensuring that the chosen words are both frequent enough to be learnable and distinctive enough to serve as a reliable watermark key. These trigger sentences constitute the watermark trigger set.
During the normal training phase, the trigger set is mixed with the original data. Because the model sees the same trigger pattern repeatedly, it learns to associate the trigger sentences with a pre‑defined output (either a specific class label or a fixed string). After training, the model behaves identically to the original on regular inputs, preserving its accuracy, but when presented with a trigger sentence it produces the watermark response. Verification is therefore a simple black‑box query: the owner sends the watermarked document to the model and checks whether the expected response is returned.
The authors evaluate the approach on two standard NLP tasks (sentiment analysis and news topic classification). Accuracy loss after watermark insertion is negligible (≤ 0.1 %). Robustness is tested against three major attack vectors:
- Parameter pruning – up to 30 % of weights are removed; watermark detection accuracy remains above 95 %.
- Quantization / model compression – the watermark survives typical 8‑bit quantization without degradation.
- Brute‑force key search – because the key space is limited to high‑TF‑IDF words, exhaustive search becomes computationally infeasible, and random guessing yields a negligible success rate.
These results demonstrate that the TF‑IDF‑based trigger set provides a reliable, low‑overhead watermark that does not compromise model performance and resists common model‑tampering attacks.
The paper also situates its contribution within a broader taxonomy of DNN watermarking: (i) watermarking the training data, (ii) watermarking model parameters, and (iii) watermarking model outputs. It reviews representative works in each category, highlighting that most prior art targets image data and often requires white‑box access to the model. By contrast, the proposed method works entirely in a black‑box setting and is the first to explicitly address textual models.
Limitations are acknowledged. The effectiveness of the watermark depends on the size and diversity of the trigger set; overly small trigger sets may be eliminated by aggressive pruning, while overly large sets could affect utility. Moreover, TF‑IDF scores can be corpus‑specific, potentially introducing bias if the underlying data distribution changes. The authors suggest future extensions such as dynamic trigger generation, multi‑key schemes, and integration with contextual embeddings (e.g., BERT) to make the watermark more resilient and less detectable.
In summary, the paper introduces a novel, TF‑IDF‑driven black‑box watermarking technique for text‑based DNNs, validates its practicality through extensive experiments, and opens new research directions for protecting intellectual property in NLP models.
Comments & Academic Discussion
Loading comments...
Leave a Comment