hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
💡 Research Summary
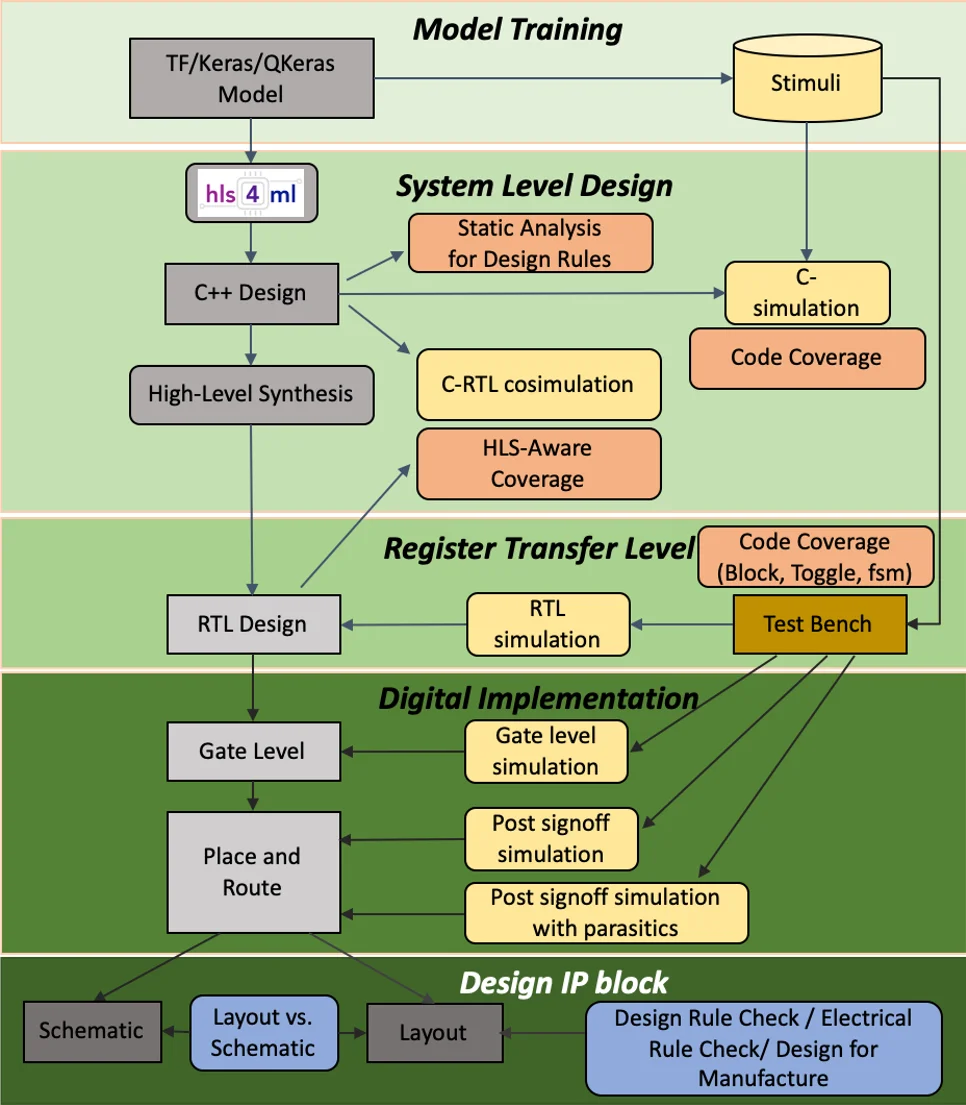
The paper presents the latest version of hls4ml, an open‑source software‑hardware co‑design framework that translates trained machine‑learning (ML) models into efficient hardware accelerators for both field‑programmable gate arrays (FPGAs) and application‑specific integrated circuits (ASICs). The authors motivate the work by highlighting the growing need for real‑time, near‑sensor processing in scientific experiments (e.g., high‑energy physics detectors) and in broader low‑power edge applications such as wearables, environmental monitoring, and agricultural sensing. Traditional edge hardware has struggled to keep pace with the computational demands of modern ML, and domain scientists often lack the multidisciplinary expertise required to design custom hardware. hls4ml addresses this gap by providing a high‑level synthesis (HLS) based workflow that bridges popular ML frameworks (Keras, PyTorch, ONNX) with hardware implementation tools (Xilinx Vitis HLS, Intel Quartus HLS, Mentor Catapult).
Key contributions of the new release include:
-
New Python APIs – Users can configure model conversion, precision, parallelism, and resource constraints directly from Python scripts or YAML files, enabling rapid design space exploration.
-
Quantization‑Aware Pruning (QAP) – Building on earlier quantization‑aware training (QAT), the framework now supports automatic pruning of low‑importance weights while preserving the quantization scheme, allowing models to be compressed to 1–8‑bit representations with minimal accuracy loss.
-
End‑to‑End FPGA Flow – hls4ml now generates complete Vitis HLS projects that can be synthesized, placed, and routed within the Xilinx toolchain, producing ready‑to‑integrate IP cores.
-
Long‑Pipeline Kernels for Low Power – A novel kernel architecture spreads computation over many clock cycles, reducing instantaneous power peaks and enabling fine‑grained control of DSP, BRAM, and LUT utilization. This is especially beneficial for battery‑powered or thermally constrained devices.
-
ASIC Backend – Support for Catapult HLS allows the same high‑level model description to be compiled into ASIC‑ready RTL, with built‑in power‑area (PPA) estimation and the ability to target multiple process nodes.
The workflow proceeds as follows: a trained model is imported, converted into an internal graph representation, and optionally optimized (e.g., batch‑norm folding, activation fusion, zero‑suppression). The user‑specified precision and parallelism are attached, after which backend writers emit C/C++ or SystemC code for the chosen target. During HLS, each layer becomes a configurable module; pipelining directives control latency and throughput, while resource pragmas manage DSP and memory usage. The framework also provides profiling utilities that display weight distributions, chosen bit‑widths, and estimated resource consumption, helping users avoid overflow or under‑utilization.
Experimental results demonstrate the practical impact. On a Xilinx Zynq‑7000 FPGA, an 8‑bit quantized fully‑connected network achieved >30 % power reduction compared to a baseline 16‑bit implementation, with less than 1 % accuracy degradation. In ASIC simulations (65 nm), the same network occupied 25 % less silicon area and delivered roughly twice the energy efficiency.
Overall, hls4ml democratizes low‑power ML acceleration by allowing scientists to iterate quickly from algorithm to silicon without deep hardware expertise. The authors envision future extensions such as additional quantization schemes, automated pipeline scheduling, and broader ASIC process support, further solidifying hls4ml as a cornerstone tool for TinyML and scientific edge computing.
Comments & Academic Discussion
Loading comments...
Leave a Comment