Inverse Optimization with Kernel Regression: Application to the Power Forecasting and Bidding of a Fleet of Electric Vehicles
This paper considers an aggregator of Electric Vehicles (EVs) who aims to learn the aggregate power of his/her fleet while also participating in the electricity market. The proposed approach is based on a data-driven inverse optimization (IO) method, which is highly nonlinear. To overcome such a caveat, we use a two-step estimation procedure which requires solving two convex programs. Both programs depend on penalty parameters that can be adjusted by using grid search. In addition, we propose the use of kernel regression to account for the nonlinear relationship between the behaviour of the pool of EVs and the explanatory variables, i.e., the past electricity prices and EV fleet’s driving patterns. Unlike any other forecasting method, the proposed IO framework also allows the aggregator to derive a bid/offer curve, i.e. the tuple of price-quantity to be submitted to the electricity market, according to the market rules. We show the benefits of the proposed method against the machine-learning techniques that are reported to exhibit the best forecasting performance for this application in the technical literature.
💡 Research Summary
The paper addresses the dual challenge faced by an electric‑vehicle (EV) fleet aggregator: short‑term forecasting of aggregate charging/discharging power and the construction of a market‑compliant bid/offer curve. Existing literature largely treats these tasks separately, using ARIMA, support‑vector regression (SVR), kernel‑ridge regression (KRR) or other machine‑learning tools to predict only the charging load, often ignoring bid generation and bidirectional vehicle‑to‑grid (V2G) capabilities. To bridge this gap, the authors propose a data‑driven inverse optimization (IO) framework that simultaneously learns the parameters of a forward linear programming model describing the aggregator’s response to electricity prices and produces the price‑quantity pairs required for market participation.
The forward model maximizes the aggregator’s welfare by selecting block‑wise power quantities (p_{b,t}) given marginal utilities (m_{b,t}) and price‑dependent constraints on total power and block limits. Because the parameters ({E_{b,t}, P_t^{\text{low}}, P_t^{\text{up}}, m_{b,t}}) are unknown, the authors treat their estimation as a generalized IO problem, which is highly nonlinear. To make the problem tractable, they adopt a two‑step estimation procedure: (1) estimate the functional relationship between the parameters and explanatory variables (past prices, past aggregate power, driving patterns, etc.) using kernel regression; (2) solve two convex programs that approximate the original bilevel problem, thereby preserving computational efficiency even for large datasets.
Kernel regression is the key to capturing nonlinear dependencies. The authors illustrate the approach with a Gaussian kernel (K_{t,\tau}= \exp(-\gamma|z_t-z_\tau|^2)), where (z_t) is the feature vector at time (t). The lower and upper bounds on total power and the marginal utilities are expressed as linear combinations of kernel values weighted by coefficients (\alpha_\tau) and (\rho_\tau). This endogenously embeds similarity information across time periods, allowing the model to learn complex patterns that linear regressions would miss.
Penalty parameters (feasibility penalty (H) and regularization (M)) are tuned via grid search, and the two convex programs are solved sequentially. The first program estimates the kernel coefficients; the second refines the forward model using the estimated parameters, ensuring that the reconstructed decisions match observed aggregate power as closely as possible.
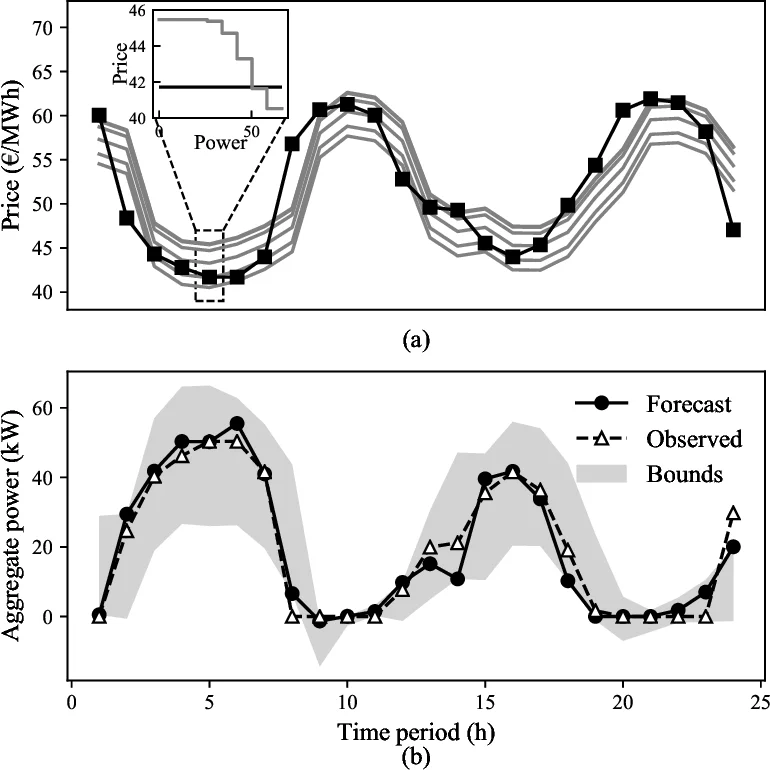
The framework respects market rules: the bid curve must be monotonically non‑increasing for a consumer (charging) and non‑decreasing for a producer (discharging). By differentiating marginal utilities for charging and discharging blocks, the model naturally yields a piecewise‑linear price‑quantity curve that can be submitted to the market (e.g., OMIE).
Empirical validation uses real‑world data derived from the 2019 National Household Travel Survey (NHTS) to simulate residential EV fleet behavior, including V2G. The dataset is split into training, validation, and test sets. The proposed IO‑kernel method is benchmarked against SVR and KRR, which are reported as the best machine‑learning baselines in the literature for this task. Performance metrics include Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and the accuracy of the generated bid curve (distance between predicted and optimal price‑quantity pairs). Results show that the IO‑kernel approach outperforms the baselines on all metrics, with particularly notable improvements in bid‑curve accuracy, translating into higher expected market revenues for the aggregator.
The authors claim three main contributions: (1) the first application of inverse optimization to jointly forecast EV‑fleet power and derive a market‑ready bid curve while accounting for V2G; (2) a computationally efficient two‑step convex approximation that incorporates kernel regression to capture nonlinearities; (3) a thorough empirical comparison demonstrating superior forecasting and bidding performance over state‑of‑the‑art machine‑learning methods.
Future research directions suggested include extending the framework to online/real‑time learning with streaming data, integrating multiple market layers (day‑ahead, real‑time, ancillary services), and incorporating stochastic or distributionally robust formulations to handle price and demand uncertainty. Such extensions would further empower aggregators to participate actively in power system operations, enhance renewable integration, and improve overall market efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment