MGpi: A Computational Model of Multiagent Group Perception and Interaction
Toward enabling next-generation robots capable of socially intelligent interaction with humans, we present a $\mathbf{computational; model}$ of interactions in a social environment of multiple agents and multiple groups. The Multiagent Group Perception and Interaction (MGpi) network is a deep neural network that predicts the appropriate social action to execute in a group conversation (e.g., speak, listen, respond, leave), taking into account neighbors’ observable features (e.g., location of people, gaze orientation, distraction, etc.). A central component of MGpi is the Kinesic-Proxemic-Message (KPM) gate, that performs social signal gating to extract important information from a group conversation. In particular, KPM gate filters incoming social cues from nearby agents by observing their body gestures (kinesics) and spatial behavior (proxemics). The MGpi network and its KPM gate are learned via imitation learning, using demonstrations from our designed $\mathbf{social; interaction; simulator}$. Further, we demonstrate the efficacy of the KPM gate as a social attention mechanism, achieving state-of-the-art performance on the task of $\mathbf{group; identification}$ without using explicit group annotations, layout assumptions, or manually chosen parameters.
💡 Research Summary
The paper introduces MGpi (Multiagent Group Perception and Interaction), a deep neural architecture designed to endow robots with socially intelligent behavior in environments populated by multiple agents and multiple conversational groups. The authors argue that social intelligence comprises two complementary abilities: (1) social perception—the capacity to interpret non‑verbal cues such as gaze direction, body posture, and proxemic distance—and (2) social interaction management—the ability to select appropriate conversational actions (e.g., speak, listen, respond, leave) based on perceived signals.
MGpi is composed of three main modules. The Social Signal Gating (SSG) module first encodes each neighbor’s non‑verbal and verbal histories. Two GRU‑based encoders are employed: a Non‑Verbal Encoder that processes a history of relative gaze vectors and rotated positions, and a Conversational Encoder that processes a history of one‑hot action vectors. Both produce 64‑dimensional embeddings. These embeddings are fed into the Kinesic‑Proxemic‑Message (KPM) gate, a learned attention mechanism that jointly evaluates kinesic (body‑gesture) and proxemic (spatial) information to assign a relevance weight to each neighbor’s message. Unlike traditional F‑formation or hand‑crafted distance thresholds, the KPM gate learns its parameters directly from data, allowing it to adapt to diverse spatial layouts and group dynamics.
The second component is the Short‑Term Memory (STM) subsystem. Social‑STM aggregates the gated neighbor embeddings over time, while Self‑STM encodes the agent’s own past action sequence. Both use GRUs, providing the network with a short‑term memory of interaction dynamics that influences future decisions.
The third component, the Interaction Policy, concatenates the outputs of the KPM‑weighted neighbor messages, Social‑STM, and Self‑STM, and passes them through a multilayer perceptron that outputs a probability distribution over the discrete action space. The policy is trained via imitation learning: the authors generate expert demonstrations using a custom social interaction simulator that models realistic multi‑modal conversational dynamics (gaze exchange, turn‑taking, group formation, etc.). The simulator is deliberately designed to produce varied scenarios with dynamic group sizes, agent movement, and role changes, thereby providing rich training data in the absence of large‑scale annotated real‑world datasets.
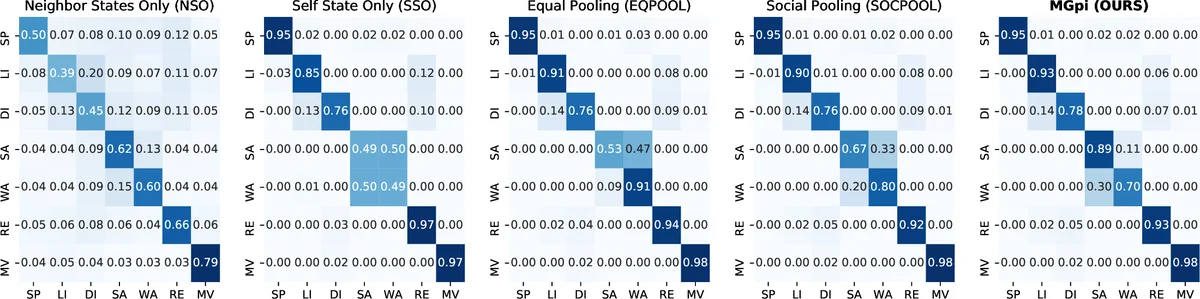
Empirical evaluation addresses two questions. First, does MGpi accurately predict the next conversational action of each agent? The model outperforms baseline multi‑agent communication approaches (including simple pooling and rule‑based methods) on a held‑out set of simulated interactions, achieving higher accuracy and faster convergence during training. Second, can the learned KPM attention be repurposed for group identification without explicit supervision? By clustering the attention weights produced by the KPM gate, the authors recover group memberships that surpass state‑of‑the‑art F‑formation detection algorithms in precision, recall, and F1 score, despite never having been trained on group labels. This demonstrates that effective social signal gating inherently captures the latent structure of conversational groups.
The paper also contributes a novel social interaction simulator, filling a gap in the community where public datasets typically lack conversational action annotations and multi‑group labeling. The simulator draws on prior work in small‑group conversation analysis and incorporates rules for gaze alignment, proxemic comfort zones, and turn‑taking probabilities. Experiments show that models trained on simulated data generalize to unseen simulated scenarios, suggesting that the learned representations capture fundamental aspects of human social behavior rather than overfitting to a specific synthetic environment.
In summary, MGpi advances the field of socially aware robotics by (1) integrating multimodal non‑verbal and verbal cues through dedicated encoders, (2) introducing a data‑driven KPM gating mechanism that replaces hand‑crafted spatial heuristics, (3) employing a short‑term memory architecture that respects the temporal nature of conversation, and (4) demonstrating that a policy learned for action prediction simultaneously yields high‑quality unsupervised group detection. The work opens avenues for future research on real‑world deployment, incorporation of higher‑level social constructs such as trust and emotion, and extension to continuous‑action spaces for more fluid human‑robot dialogue.
Comments & Academic Discussion
Loading comments...
Leave a Comment